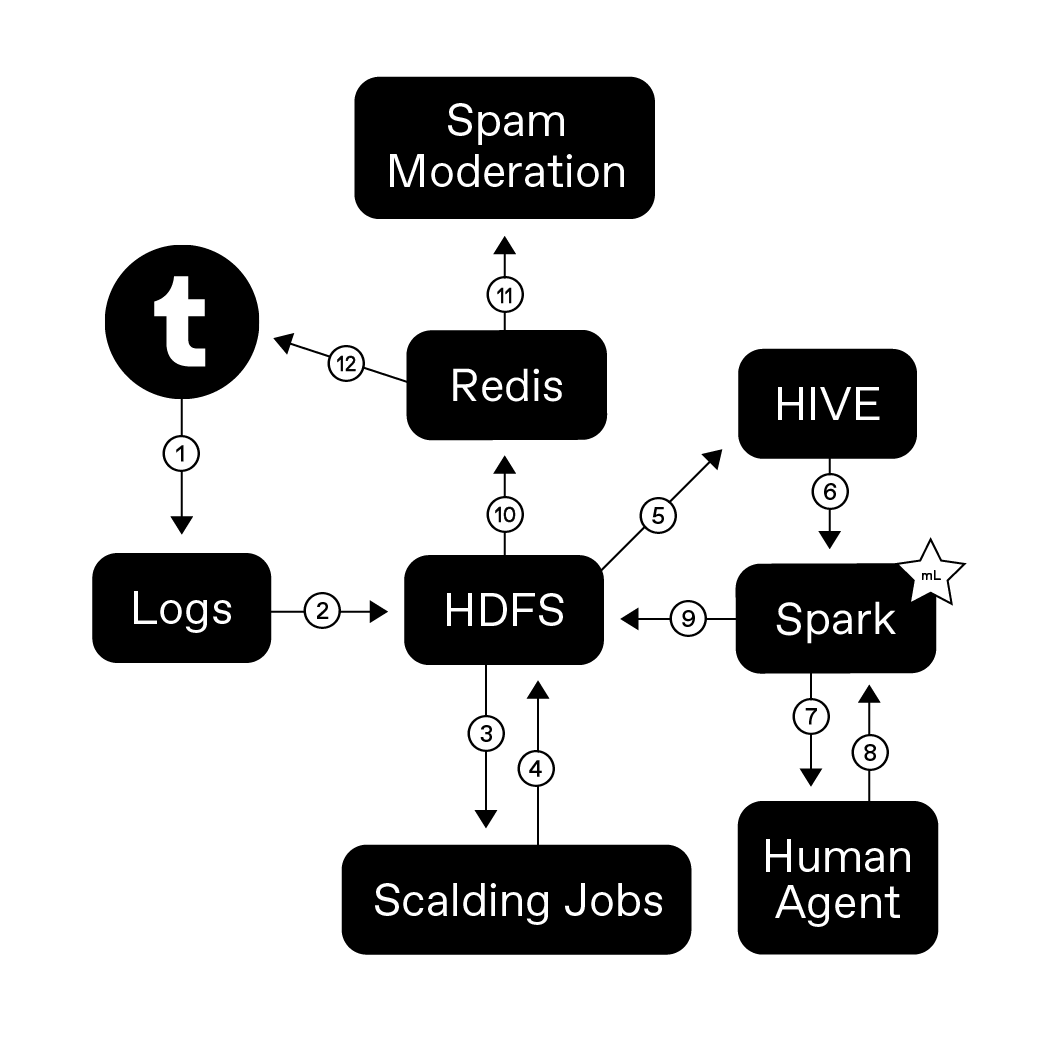
I’ve been at Tumblr for four years as of last month, and in those four years I’ve moved from Engineer to Senior Engineer to Principal Engineer. Everyone’s journey along the path of their career is different, and engineering is a little different everywhere, but this is my story. My hope is that it provides some insight into Tumblr’s career ladder and some themes that are universal across engineering cultures at other companies.
Prelude: Full Stack Madness
Before I joined Tumblr, I worked for ten (!!!) years as a full stack developer at a college, mostly alone. I’d been writing code (poorly) and immersing myself in tech since I was a kid, so I felt pretty confident as a teenager taking a job building websites for my college.
Over the course of that ten-year job, I went from writing terrible PHP and Javascript to performing the ultra full stack of work: rack-mounting servers, installing operating systems on them, splitting them up into application servers and database servers and whatnot, managing them often, writing application logic to run on and across them, designing databases (relational and NoSQL), designing user interfaces, bridging lots of different APIs, and scaling my applications to meet greater demands. Way too much for one person to do, really.
It was an opportunity for me to get my hands on all facets of building things for the internet. It afforded ample time to figure out what felt best for me, which turned out to be backend application development. I probably waited way too long before moving on to my next job, which luckily became Tumblr. When I did get the job at Tumblr, I had two main goals: to work as a component of a team rather than alone, and to focus on backend engineering.
Being heads-down as an Engineer
When I joined Tumblr, I came on as an Engineer. It’s technically a step above “entry level” at most companies, and it was the baseline for new engineering hires at Tumblr at the time. Someone at the Engineer level at Tumblr is expected to be a team member who focuses on a certain technical domain, such as databases, SRE, iOS, Android, Javascript, PHP, Scala, etc. For me, in product engineering, this roughly translated into being either a frontend engineer (iOS, Android, Javascript) or a backend engineer (PHP, Scala). When I started, I did a little bit of both since I had experience with both, but over the course of my first year I shed a lot of my frontend knowledge in favor of deepening my backend knowledge.
The Engineer level usually means you’re someone who is relatively “heads-down”, being given tickets to complete during sprints which contribute to a larger project that your team is working on. That was me — at the time I joined we were working on finishing up the “new” post forms on the web, and my team was about to start building blog-to-blog instant messaging. I worked with senior engineers to flesh out the architecture for messaging, and through that I learned how to build something that seemed simple to me but became very complex at scale. I churned through a lot of tickets and wrote a lot of code, almost entirely feature logic, rarely touching anything outside of my domain.
While I didn’t spend a lot of time in meetings or making decisions, I did get to have a voice in pretty much everything my team worked on, and I felt empowered by my manager to speak my mind across the company. During my first year that actually got me in trouble, as I become a bit overconfident in my own opinion, and I didn’t have the experience necessary to back much of it up. That was a good learning experience for me; it taught me how to pick my battles and when to use my voice and speak my mind. Sometimes saying nothing is the best option, and it’s important to keep yourself mindful of what your voice is actually contributing.
Opening up avenues into Senior Engineering
After my first year I started feeling very familiar with Tumblr’s engineering practices and a couple of lucky opportunities appeared. The first was being asked to act as a pseudo-member of the Core PHP team since they were understaffed, which broadened my responsibilities and gave me a reason to start digging around in our framework-level code. It afforded me time to learn a lot about our framework level and our design patterns, and I made some fundamental changes to how the Tumblr PHP app works. More importantly, it almost doubled the amount of code I was expected to review, much of it outside of my previous work as a product engineer.
Around that time, the senior engineers I was working with on messaging moved on from the project, leaving pretty much just me to finish the work a few months before we launched. Because of this, almost all of the PHP logic that exists for messaging on Tumblr is my code, and I became the go-to authority on how messaging works under the hood.
After launch, we continued to iterate on messaging features. A few of these iterations required heavy refactors of a system that was humming along, being used by millions of people. I learned how to make dramatic changes without anyone who was using the product noticing, and I started being one of the engineers who’d help others do the same for their projects.
One example of that kind of work was the Replies relaunch, which was outside my normal workload, but I lent a hand to help make sure it met the deadline we had set for ourselves. I also took the engineering lead on the infamous Lizard Election of 2016, coordinating work among designers, web engineers, iOS engineers, and Android engineers, while also building most of the backend for it myself. It was an extremely ambitious project that we put together in a very short period time, all for one absurd April Fools joke. The community loved it (or was extremely confused by it), and it provided a lot of insight for me into what it’d be like to lead cross-team efforts.
I also spent a lot of my first two years participating in Breaking Incidents — at Tumblr these are usually sudden high-impact problems that need to be fixed quickly, usually by someone who is on call. I probably learned the most about Tumblr’s features, systems, and edge cases while helping fix these problems. Sometimes these incidents were small, like just a user interface bug that had been accidentally deployed, and sometimes these incidents were huge, such as entire database clusters failing. Jumping in and helping to quickly resolve these incidents showed that I wasn’t afraid to get my hands dirty.
All of this additional responsibility meant I started going to more meetings and talking to more people across the company, as I had carved out a space that I felt was my own. It was really difficult and uncomfortable a lot of the time, and I made mistakes that broke things, but fixing them, persevering, and learning not to repeat them showed how much I was ready for a more senior role. I got promoted to Senior Engineer and stayed at that level for two and a half years, with a brief interlude as a Staff Engineer.
Raising the stakes as a Senior Engineer and then Staff Engineer
As a Senior Engineer, I felt much more empowered to take on difficult tasks, as I had a couple of major, successful projects behind me. The feeling of being uncomfortable became comfortable for me; I got used to being in a position where I didn’t have a ready solution to a problem, and I was happy to say so, but I felt confident I could figure it out by drawing on my past experience and doing some research.
I started being consulted by other teams when they’d be scoping out new projects, and I had a good sense for why a project could be difficult or easy. I also started going to meetings that had nothing to do with my normal job responsibilities, as I felt that it was important to stay on top of what was happening outside of those responsibilities. With only a couple hundred people at the company, it felt very feasible to know what was going on in most places.
It was around a year into being a Senior Engineer that I was invited to become a Staff Engineer, which at the time was parallel with the Senior Engineer role, having only a slightly different set of expectations. Being a Staff Engineer meant more talking about engineering problems and processes, more reviewing other peoples’ code and ideas, less time writing my own code. Usually this is actually its own dedicated step along the career path, as it typically means you’re some kind of dedicated domain owner in a much larger organization of engineers. I fell into it naturally, as I was already doing a lot of the kind of work it expected, which highlighted to me that the best career moves are often the obvious ones.
However, over time it began to feel like Staff Engineer was a role that would be more practical at a larger company of hundreds or thousands of engineers, and actually impractical at Tumblr’s size of just a hundred or so engineers. To me, many of the responsibilities of our Staff Engineer group felt like they should be that of any Senior Engineer or Managers/Directors. Many of our tasks involved shepherding other engineers and providing insight into how to fix hard problems, and defining processes that affected most engineers.
A lot of those processes were very administrative and felt like they’d be more enforceable if they came from someone at the executive level. At times, Staff Engineering also felt like the dreaded “ivory tower” approach to engineering, in which a select few get to decide what’s best for everyone, which I strongly disagree with. I hopped out of the Staff Engineer role after nine months or so, and the Staff Engineering group was dissolved shortly after I left it.
Becoming More Independent
After spending so much time spreading myself around the company, I gradually shifted out of being tied to a single team and I became a kind of “floater” among the product engineering teams. I started tackling bigger problems with our legacy systems (such as getting them GDPR compliant) and helping shape the architecture of new features (such as the Neue Post Format). I had become the same kind of engineer as those who had helped me build messaging, acting more as someone who isn’t afraid to get their hands dirty contending with the obscure parts of a ten year old codebase. It was around this time that I wrote How I Code Now and How I Review Code, as a lot of my job felt like it was honing those skills to a sharp point.
As I became a Senior Engineer and then Staff Engineer, more of my work became self-directed rather than decided for me by a supervisor. Instead of being given tickets to solve in a sprint, I got to do a combination of choosing my own work and being asked to help in certain areas by other managers and my supervisor. I went wherever that focus was needed, which still meant more time talking about problems, but now also more time writing framework code in support of other engineers.
After gaining a lot of experience in how Tumblr worked, it became easier for me to see where there were opportunities for improvement, both engineering- and product-wise. Since most of my passion is in the product work, I was given the latitude to try to push forward Tumblr’s product features more directly. Some of these projects I ran with myself, like the last three years of April Fools jokes and revamping Tumblrbot and pushing the Neue Post Format, but a lot of the time I’ve tried to help empower feature work that I’m just passionate about and want to see succeed.
Since I worked alone at my previous job for a very long time, I already had the ability to be self-directed and to self-organize. I try to keep my work well documented, I like to keep a trail of emails and tickets to show what I’m working on and have finished, and I can mentally context switch quickly between many different ongoing tasks. Most of that context switching ability centers around assigning priority to every task I do. If a project or task has no priority, it usually never gets done, but that’s fine; there is always more to do than can ever be done. Sometimes I have “rainy days” when I can pull something from the bottom of the priority list that I’ve wanted to do for awhile but not had time.
It was also around this time of becoming more self-directed that I began mentoring other engineers one-on-one, and working with them to help them grow in the same way that I had, or in whatever way they wanted to grow. Sometimes I join a specific team for a brief period, usually acting as a force-multiplier to the output of a team while I was on it. I like to tear through challenges and make big difficult decisions when they need to be made, talking and documenting them out to reinforce shared knowledge, while trying to avoid the pitfalls of seeking perfection. One example of that is the ongoing Neue Post Format project, which has involved huge refactors of existing code, tons of new code, and a complete overhaul of how all new posts on Tumblr are stored and represented. Not to mention thousands upon thousands of words of documentation.
All of this led me to becoming a Principal Engineer, which is where I’m at now. For me, it’s a role that expects continuous mentorship and sponsorship of other engineers, constant vigilance of best practices, tons and tons of code review and architecture-building, and heightened mindfulness of ones’ words and actions. In my experience so far, it’s a lot of talking and writing about engineering while making big, difficult engineering decisions, and actually writing fewer, but higher impact, lines of code.
Moving beyond Principal Engineer is a difficult and rare task. Of the hundred or so engineers at Tumblr, there are only a handful of Principal Engineers, and even fewer Senior Principals. From my understanding, moving beyond Principal at Tumblr means being a framework-level domain owner and decision maker, contributing to the entire scale of Tumblr’s success. I’m still trying to figure out if that challenge is something that interests me, but in the meantime there are more than enough challenges at Tumblr to keep me busy.
By the way, if my story sounds like an interesting adventure to you, we’re hiring.