Ten years ago HTTPS wasn’t as nearly as widespread as today. It is hard to believe that HTTPS was essentially opt-in, if available at all! Back then, people also had to get creative when inventing means to delegate access to someone else. One solution was OAuth 1, conceived by the IETF, later adopted by Tumblr in 2011.
Time went by, and here we are in 2021, with hardly any popular website not shielded with HTTPS (including your own blog!). Today, it wouldn’t make much sense to adopt OAuth 1 as inconvenient as it is. Yet here we are, still asking people to use outdated protocols for their new fancy Tumblr apps. Not anymore!
Starting today, you have another option: we’re officially opening up OAuth 2 support for the Tumblr API!
There are no plans to shut down OAuth 1. Your app will continue to work as usual. But be sure to keep an eye on this blog just in case anything new pops up that would prevent us from serving OAuth 1 requests.
What’s more, if you wish to adopt OAuth 2 in your app, given its superior simplicity, you don’t have to migrate entirely to OAuth 2 at once. Instead, you can keep the old sign-up / log-in flow working, and exchange OAuth 1 access token to OAuth 2 tokens on the fly. There’s only one catch: this exchange will invalidate the original access token, so you should be using only the OAuth 2 Bearer authentication for any subsequent requests.
Next steps
We’ll be adding support for OAuth 2 to our API clients in the coming months. Follow this blog to learn firsthand when this happens.
Although we do support client-side OAuth 2 flow, we can’t recommend using it unless absolutely required. We might harden it with PKCE someday, though.
He’ll be doing a workshop on how to use the Tumblr API that will hopefully inspire you to use our dataset to create the next big application. If you use the Tumblr API, you’re eligible to win a $500 Amazon Gift Card for you and your team!
If you’re going to be there, give a shout out (John is @codingjester). John will have stickers and t-shirts for anyone who swings by. We hope to see you there!
As some of you close watchers may have noticed, we recently updated the ID numbers for new posts on Tumblr to be huuuuuge. Post IDs were always 64-bit integers to us at Tumblr, but now they’re actually big enough to push into that bitspace. While this doesn’t change anything for anyone using the official Tumblr apps or website, it did cause some hiccups for third-party consumers using programming languages like Javascript, which support only 53 bits of precision for integers.
To help alleviate this, we’ve added a new field to our post objects via the Tumblr API called id_string, which is a string representation of the numeric post ID. You can use the value of this id_string instead of id in any request to the Tumblr API and it should work just the same. This is the same thing that Twitter did when they moved to big-number “snowflake” identifiers. Starting March 16th, you should see this new field whenever you encounter a post via the Tumblr API.
Why’d we change post IDs to be so huge? Some of you may have noticed there was quite a jump. We recently migrated Tumblr to a new datacenter, and as a part of that migration we updated the system that generates new post IDs. The new system generates much bigger IDs because it uses a different algorithm to generate them more safely.
If you run into trouble with this or don’t see it somewhere you need it, please contact Tumblr Support and we’ll take a look!
You’ve been asking for an official Golang wrapper for the Tumblr API. The wait is over! We are thrilled to unveil two new repositories on our GitHub page which can be the gateway to the Tumblr API in your Go project.
We’ve tried to structure the wrapper in a way that is as flexible as possible so we’ve put the meat of the library in one repo that contains the code for creating requests and parsing the responses, and interacts with an interface that implements methods for making basic REST requests.
The second repo is an implementation of that interface with external dependencies used to sign requests using OAuth. If you do not wish to include these dependencies, you may write your own implementation of the ClientInterface and have the wrapper library use that client instead.
Handling Dynamic Response Types
Go is a strictly typed language including the data structures you marshal JSON responses into. This means that the library could have surfaced response data as a map of string => interface{} generics which would require the engineer to further cast into an int, string, another map of string => interface{}, etc. The API Team decided to make it more convenient for you by providing typed response values from various endpoints.
If you have used the Tumblr API, you’ll know that our Post object is highly variant in what properties and types are returned based on the post type. This proved to be a challenge in codifying the response data. In Go, you’d hope to simply be able to define a dashboard response as an array of posts
type Dashboard struct {
// ... other properties
Posts []Post `json:"posts"`
}
However this would mean we’d need a general Post struct type with the union of all possible properties on a Post across all post types. Further complicating this approach, we found that some properties with the same name have different types across post types. The highest profile example: an Audio post’s player property is a string of HTML while a Video post’s player property is an array of embed strings. Of course we could type any property with such conflicts as interface{} but then we’re back to the same problem as before where the engineer then has to cast values to effectively use them.
Doing Work So You Don’t Have To
Instead, we decided any array of posts could in fact be represented as an array of PostInterfaces. When decoding a response, we scan through each post in the response and create a correspondingly typed instance in an array, and return the array of instances as an array of PostInterfaces. Then, when marshalling the JSON into the array, the data fills in to the proper places with the proper types. The end user can then interact with the array of PostInterface instances by accessing universal properties (those that exist on any post type) with ease. If they wish to use a type-specific property, they can cast an instance to a specific post type once, and use all the typed properties afterward.
This can be especially convenient when paired with Go’s HTML templating system:
snippet.go
// previously, we have some `var response http.ResponseWriter`
client := tumblrclient.NewClientWithToken(
// ... auth data
)
if t,err := template.New("posts").ParseFiles("post.tmpl"); err == nil {
if dash,err := client.GetDashboard(); err == nil {
for _,p := range dash.Posts {
t.ExecuteTemplate(response, p.GetSelf().Type, p.GetSelf())
}
}
}
This is a rudimentary example, but the convenience and utility is fairly evident. You can define blocks to be rendered, named by the post’s type value. Those blocks can then assume the object in its named scope is a specific post struct and access the typed values directly.
Wrapping Up
This is a v1.0 release and our goal was to release a limited scope, but flexible utility for developers to use. We plan on implementing plenty of new features and improvements in the future, and to make sure that improvements to the API are brought into the wrapper. Hope you enjoy using it!
Are you an iOS or OS X developer with opinions on how to implement large, performant applications using Core Data? If so, I want to hear what you think.
Core Data, Apple’s object-graph management framework for iOS and OS X, is really powerful but also somewhat complicated, and not always entirely straightforward to use. Sometimes it feels like everyone has their own unique way of using it. We’ve used Core Data for persistence in Tumblr for iOS for years now but are always interested in re-evaluating our approach to make sure that we’re leveraging the SDK as effectively as possible.
In the interest of gathering feedback, we’ve published the CoreDataExample sample project (inventive naming, I know). It displays a little bit of data from Tumblr API using a class called TMCoreDataController to access the underlying database, both from the main queue (user interface) and in the background. Everything in here should be pretty straightforward, but we’d still love for you to have a look and provide any feedback you may have on how we’ve implemented these particular access patterns.
The README contains more background information, so I’d recommend starting there if I’ve successfully piqued your interest. Thanks in advance; looking forward to hearing your thoughts.
John Bunting talks about different services Tumblr has built and how their architecture helps them be fault tolerant as they continue to grow.
John Bunting talks about different services Tumblr has built and how their architecture helps them be fault tolerant as they continue to grow.
You are looking at a Tumblr post, so you love GIFs. You are reading an engineering post, so you love bits. Have you ever wanted to know how Tumblr turns these bits into GIFs? Thanks to QCon, you can watch cyborg hacker codingjester talk about how its done.
One of the Core Web team’s goals at Tumblr is to reduce the number of runtime issues that we see in our React codebase. To help move some of those issues from runtime to compile time, I evaluated the two leading type systems, Flow and TypeScript, to see if they could give us more type safety. I did a bit of background reading about the differences between Flow and TypeScript to see what the community had to say about them.
This post claims that Flow and TypeScript are similar enough that you should choose whichever of them is easier to integrate with your other tools. For Angular development, it recommends using TypeScript; for React, Flow.
This post outlines the author’s experience with using Flow in a React codebase. It advocates switching from Flow to TypeScript because of Flow’s unhelpful error messages, bad tooling, and propensity to spread untyped code. It also claims that most of the type annotations are able to be shared between Flow and TypeScript with only minor changes.
This slideshow shows many differences around the philosophies and goals of TypeScript and Flow, and it gives detailed explanations in the differences between the two type systems. It explains IDE support and how to get access to third-party type definitions.
Lack of Consensus
It seems like many people have differing opinions about which type system is better for a React codebase. Because there wasn’t a broad consensus across the community, I decided to get some first-hand experience with each of these tools to see which one would be most practical and helpful for use at Tumblr.
For the most part, Flow and TypeScript are basically interchangeable. I was able to reuse most of the source code between both projects with only minor changes. Here are some examples of changes I needed to make to get my TypeScript code working with Flow:
Flow requires that types are imported using import type where TypeScript re-uses import.
Some generic type constraints are different in redux’s type declarations between Flow and TypeScript, so I dropped the generic constraint for Flow.
Types cannot have the same name as constants, so I had to rename a few small things (see below).
Testing
After I got the project prepared I set up the following situations to see which tool performed better. These are my assumptions of the most common situations in which a type checker will help when writing React code on a day-to-day basis.
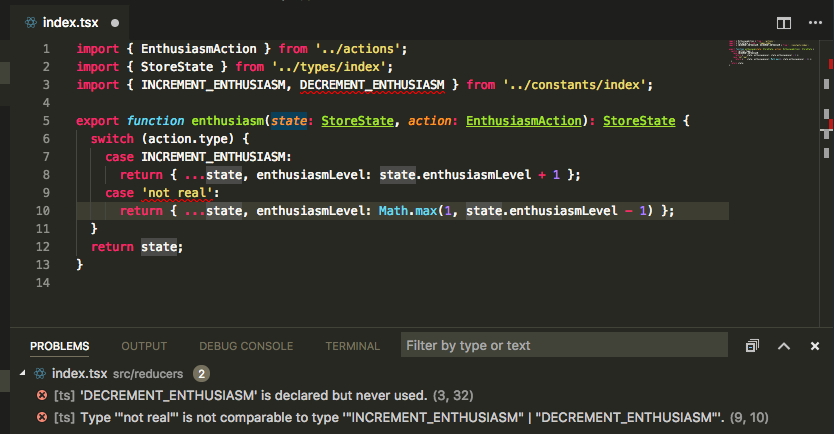
Handling an Unnecessary Case in a Switch
TypeScript
TypeScript realizes that 'not_real' is not a possible case for the switch.
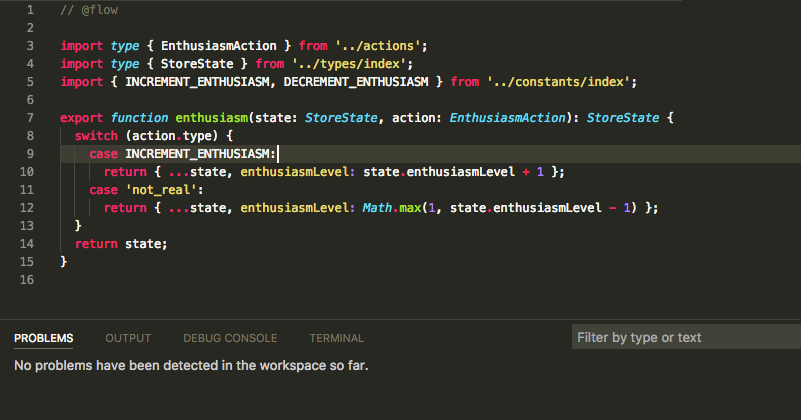
Flow
Flow does not detect any issue.
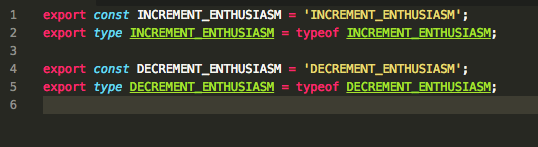
Declaring Variables with Same Name as Type
TypeScript
TypeScript allows types to have the same name as constants, and it allows Command-clicking on the types to see their declarations.
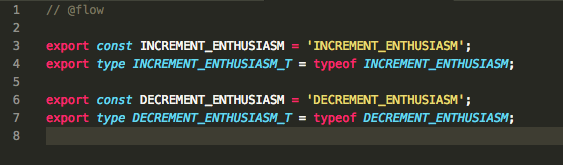
Flow
Flow requires types and constants to have different names. In this case, I needed to rename the type to INCREMENT_ENTHUSIASM_T to appease Flow’s type checker.
Returning Incorrect Type from Function
TypeScript
[ts]
Type '{ enthusiasmLevel: string; languageName: string; }' is not assignable to type 'StoreState'.
Types of property 'enthusiasmLevel' are incompatible.
Type 'string' is not assignable to type 'number'.
Flow 0.52
[flow] object literal (This type is incompatible with the expected return type of object type Property `enthusiasmLevel` is incompatible:)
Flow 0.53
[flow] property `enthusiasmLevel` of StoreState (Property not found in number) [flow] property `languageName` of StoreState (Property not found in number)
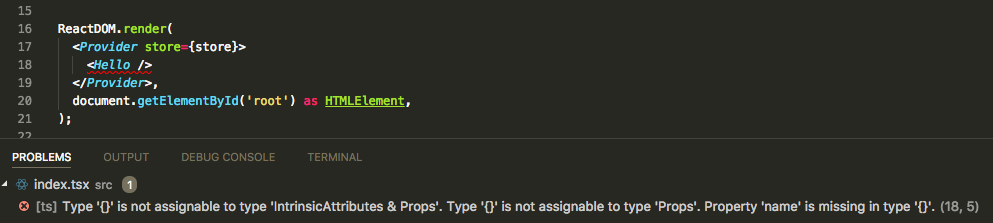
Missing Required Props When Instantiating a Component
TypeScript
TypeScript shows the error at the site where the properties are missing with the error:
[ts] Type '{}' is not assignable to type 'IntrinsicAttributes & Props'. Type '{}' is not assignable to type 'Props'. Property 'name' is missing in type '{}'.
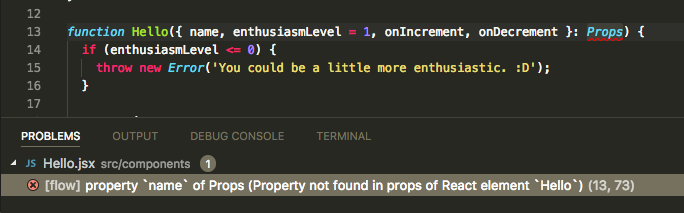
Flow
Flow shows the error within the component where the property will be used, with no way to discover which call site is missing a property. This can be very confusing in codebases that have lots of reusable components. Flow displays this error:
[flow] property `name` of Props (Property not found in props of React element `Hello`)
Code Safety
TypeScript
TypeScript allows enforcing full type coverage on .ts files with the noImplicitAny flag in the tsconfig.
Flow
Flow provides a code coverage plugin so that you can see which lines are implicitly not typed.
Other Considerations
Flow has the most React community support and tooling, so there is much more documentation about how to get Flow and React working together. TypeScript is more popular with Angular developers. Choosing TypeScript may be breaking from community standards, so we may have more issues that don’t have a simple answer on Google.
Conclusion
I concluded that we should use TypeScript because it seems easier to work with. My experience seems to line up with this blog post. It has better error messages to debug type issues and its integration with VSCode makes coding more pleasant and transparent. If this ends up being the wrong choice later on, our codebase will be portable to Flow with some minor changes.
Shortly after arriving at this conclusion, Flow 0.53 was released and a blog post on Medium published touting it’s “even better support for React”. However, after running through the test cases above, I only found one case where Flow had improved its error messaging. TypeScript still seems like the more reliable, easier to use solution.
At Tumblr, we’re always looking for new ways to improve the performance of the site. This means things like adding caching to heavily used codepaths, testing out new CDN configurations, or upgrading underlying software.
Recently, in a cross-team effort, we upgraded our full web server fleet from PHP 5 to PHP 7. The whole upgrade was a fun project with some very cool results, so we wanted to share it with you.
Timeline
It all started as a hackday project in the fall of 2015. @oli and @trav got Tumblr running on one of the PHP 7 release candidates. At this point in time, quite a few PHP extensions did not have support for version 7 yet, but there were unofficial forks floating around with (very) experimental support. Nevertheless, it actually ran!
This spring, things were starting to get more stable and we decided it was time to start looking in to upgrading more closely. One of the first things we did was package the new version up so that installation would be easy and consistent. In parallel, we ported our in-house PHP extensions to the new version so everything would be ready and available from the get-go.
A small script was written that would upgrade (or downgrade) a developer’s server. Then, during the late spring and the summer, tests were run (more on this below), PHP package builds iterated on and performance measured and evaluated. As things stabilized we started roping in more developers to do their day-to-day work on PHP 7-enabled machines.
Finally, in the end of August we felt confident in our testing and rolled PHP 7 out to a small percentage of our production servers. Two weeks later, after incrementally ramping up, every server responding to user requests was updated!
Testing
When doing upgrades like this it’s of course very important to test everything to make sure that the code behaves in the same way, and we had a couple of approaches to this.
Phan. In this project, we used it to find code in our codebase that would be incompatible with PHP 7. It made it very easy to find the low-hanging fruit and fix those issues.
We also have a suite of unit and integration tests that helped a lot in identifying what wasn’t working the way it used to. And since normal development continued alongside this project, we needed to make sure no new code was added that wasn’t PHP 7-proof, so we set up our CI tasks to run all tests on both PHP 5 and PHP 7.
Results
So at the end of this rollout, what were the final results? Well, two things stand out as big improvements for us; performance and language features.
Performance
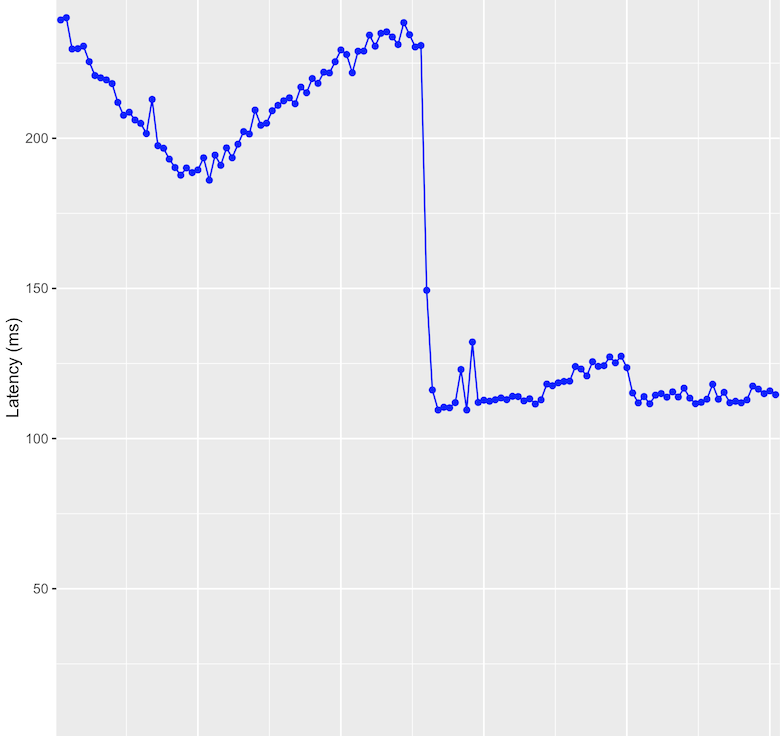
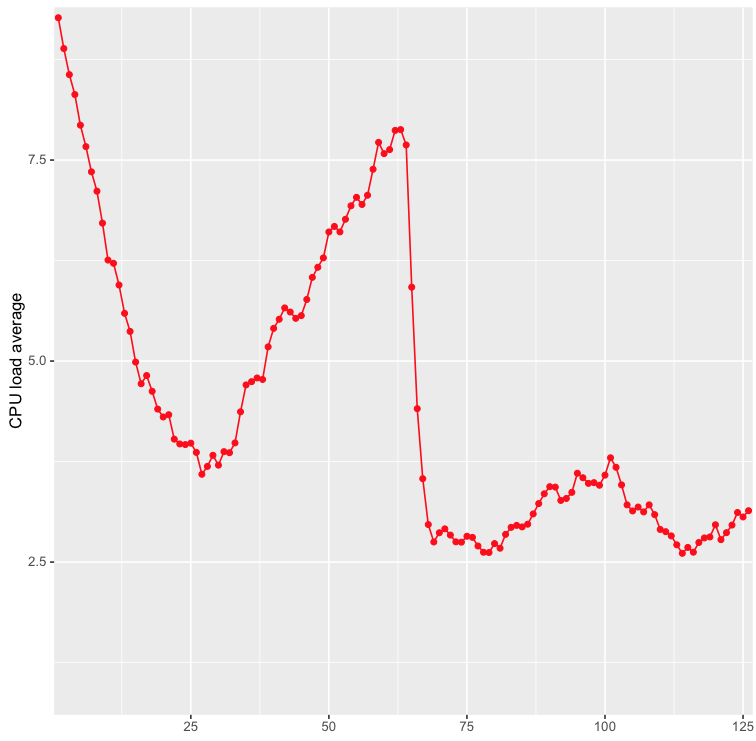
When we rolled PHP 7 out to the first batch of servers we obviously kept a very close eye at the various graphs we have to make sure things are running smoothly. As we mentioned above, we were looking for performance improvements, but the real-world result was striking. Almost immediately saw the latency drop by half, and the CPU load on the servers decrease at least 50%, often more. Not only were our servers serving pages twice as fast, they were doing it using half the amount of CPU resources.
These are graphs from one of the servers that handle our API. As you can see, the latency dropped to less than half, and the load average at peak is now lower than it’s previous lowest point!
Language features
PHP 7 also brings a lot of fun new features that can make the life of the developers at Tumblr a bit easier. Some highlights are:
Scalar type hints: PHP has historically been fairly poor for type safety, PHP 7 introduces scalar type hints which ensures values passed around conform to specific types (string, bool, int, float, etc).
Return type declarations: Now, with PHP 7, functions can have explicit return types that the language will enforce. This reduces the need for some boilerplate code and manually checking the return values from functions.
Anonymous classes: Much like anonymous functions (closures), anonymous classes are constructed at runtime and can simulate a class, conforming to interfaces and even extending other classes. These are great for utility objects like logging classes and useful in unit tests.
Various security & performance enhancements across the board.
We just published v1.1.0 of the tumblr.js API client. We didn’t make too much of a fuss when we released a bigger update in May, but here’s a quick run-down of the bigger updates you may have missed if you haven’t looked at the JS client in a while:
Method names on the API are named more consistently. For example, blogInfo and blogPosts and blogFollowers rather than blogInfo and posts and followers.
Customizable API baseUrl. We use this internally when we’re testing new API features during development, and it’s super convenient.
data64 support, which is handy for those times when you have a base64-encoded image just lying around and you want to post it to Tumblr.
Support for Promise objects. It’s way more convenient, if you ask me. Regular callbacks are still supported too.
Linting! We’ve been using eslint internally for a while, so we decided to go for it here too. We’re linting in addition to running mocha tests on pull requests.
Check it out on GitHub and/or npm and star it, if you feel so inclined.
tumblr.js REPL
When we were updating the API client, we were pleasantly suprised to discover a REPL in the codebase. If you don’t know, that’s basically a command-line console that you can use to make API requests and examine the responses. We dusted it off and decided to give it its own repository. It’s also on npm.
If you’re interested in exploring the Tumblr API, but don’t have a particular project in mind yet, it’s a great way to get your feet wet. Try it out!
This summer the engineering team at Tumblr got to work with some amazing Interns. We asked each of them to share their experiences and tell you a little bit about the projects they worked on. Here is the first in a series of upcoming intern profiles.
This summer I interned at Tumblr as a front end web engineer working with the discovery team. I had amazing opportunities here to build awesome things that many people see, but more important, to work with a creative and dynamic team, and be able to contribute to Tumblr. Additionally, I loved spending the summer in New York - really is an exciting place to be.
I started off getting setup with my own development box and similar access to full time employees at Tumblr. While I started off with smaller projects to get to know the codebase and team, I quickly started getting bigger and bigger projects. It was really overwhelming at first to deploy the tumblr.com codebase within the first week I was here, going from only writing tiny things to a site as big as Tumblr.
The first big project I worked on was making a new logged out tag page. Throughout the summer, I was mostly mentored by Johnny Benson, who really helped me out with how things are done and constant creative and practical decisions involving my work. I also worked with Tag Savage for many of the design changes I was working on. It was always fun for me to hear “if this isn’t too hard to do…,” and be able to make a proof-of-concept by the day’s end. In fact, the current tag page design started off as refinements to a current tag page, then grew into a bigger project when I took these suggestions on. The layout of this page is rather unique - smart sliding rows, and it took a good deal of code to make it work properly.
I also had the opportunity to clean up and improve on some of the already stunning login and register views. These pages were mostly complete, just needing some design and code tweaks. It was a bit nerve wracking deploying these pages as there was a chance I could have missed something and would break login. Most of the changes I made were on the backend PHP, so that going out without a hitch was great for me.
I really enjoyed the other interns at tumblr this summer - previously, I would be the only intern at a company, now I had other interns working with me. Going to lunch, exploring the city was always fun with the other interns.
Now, it is time for me to head back to school at the University of Southern California, and face the homework, the time crunches, and the assignments once again. Seeing Tumblr grow and change over the past few months was a cool experience, and I’m glad I was able to be a part of it.
Want to embed a tweet? Just paste the URL into a new link block on Tumblr. Or you can use the Share feature in other apps, like Twitter itself, to send the tweet URL to the Tumblr app.
You’ll get a perfect little screenshot of the tweet. You don’t have to flap your device around to help the image develop, but nobody is going to stop you.