




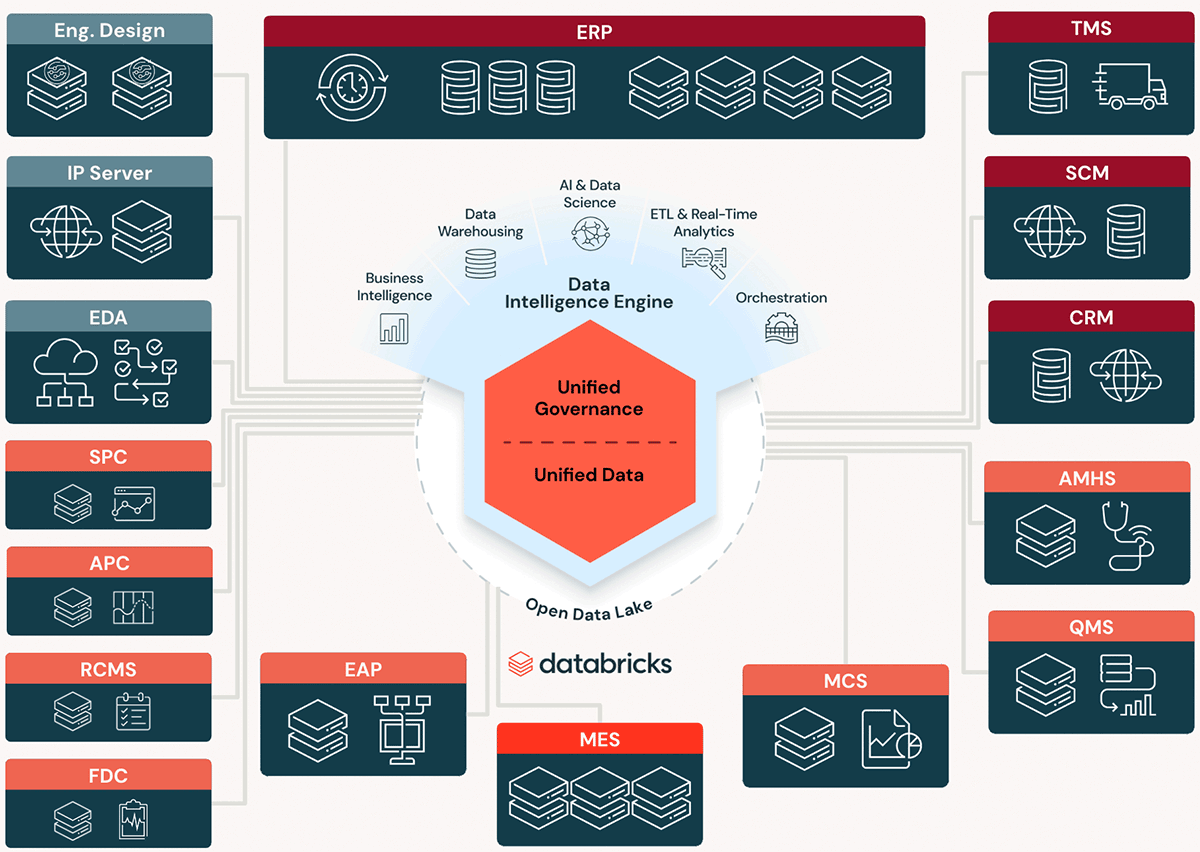

クラウド分析のパワーを解き放つ:Intelのデータ革命を垣間見る
世界有数のハイテク企業が、データ分析をどのように変革し、時代の最先端を走り続けているのかを知る準備はできていますか? Intel ITの最新ホワイトペーパーでは、Intel最大の事業部門である企業データ分析のクラウドへの移行を成功させた内部事情を明らかにしています。 Intel��がファウンドリサービスとソフトウェア開発の領域にさらに踏み込んでいる今、堅牢で高性能なデータプラットフォームに対する需要はかつてないほど高まっています。 このデータ主導型の変革のベースは、さまざまな事業活動から収集されたインテリジェントな知見にあり、Intelは迅速かつ十分な情報に基づいた意思決定を行うことができます。 この変革の中核となるのが、Databricks上に構築されたクラウドベースのデータ分析プラットフォームです。 この革命的なプラットフォームは、単なるデータストレージではなく、以下を含むダイナミックなエコシステムです: 統合データ分析のためのサンドボックス機能 何度でも使えるデータ取り込みと変換のテンプレート AIと機械学習の

よりスマートな製造:生成AIの合理化におけるガバナンスの役割
人工知能(AI)は、企業が生産し、顧客が接するあらゆる製品やサービスに組み込まれるようになるでしょう。 生成AIによって、私たちは今、あらゆる企業の競争優位に貢献するデータ & AIイニシアチブへの期待が高まる時代に突入しています。 データガバナンスは、企業が競争上の優位性を生み出し、それを維持するために成功するためには、絶対に欠かせないものです。 今日のダイナミックな状況において、データガバナンスの重要性を見過ごすことはできません。 なぜかというと、優れたAIは優れたデータから生まれるからです。 適切なガバナンスがなければ、良いデータを確保することはできません。 しかし、データガバナンスには大きな問題があります。 「プリンセス・ブライド」で有名なハリウッドのキャラクター、イニゴ・モントーヤから引用します。「データガバナンス...。あなたはこの言葉を使い続けています。 私は、それはあなたが思っているような意味ではないと思います!」。これは、データガバナンスという用語があまりに不定形になりすぎて、それが何な
エネルギー業界向けデータインテリジェンスプラットフォームのご紹介
よりスマートでクリーン& 信頼性の高いエネルギーシステムへのパラダイムシフトを促進 電気は新しい石油です。 エネルギー源は多様化し、エネルギーの用途はより電気的になっています。 電力は急速に一次エネルギー源になりつつあり、再生可能エネルギーは世界の電力の30%を供給しています。 顧客の嗜好と市場原理が再生可能エネルギーと脱炭素化を推し進める中、私たちは新旧のエネルギーシステムが共存する過渡期にあり、経済的影響を伴う価格変動を引き起こしています。 マッキンゼーによると、データとAIはこの移行期に不可欠であり、今後10年間で最大5兆ドルの価値を提供し、2050年までに実質ゼロ排出を達成するために不可欠です。 今後数年間、大手エネルギー企業はデータとAIを活用し、変動リスクを管理しながら移行を活用することになるでしょう。 しかし、エネルギー部門がAIの可能性を最大限に活用するには、以下のような大きなハードルを乗り越えなければなりません: レガシーなインフラやデータモデルによる独自のデータフォーマットやクローズド