

本日、LilacがDatabricksに参画することを発表できることを嬉しく思います。 Lilacは、データサイエンティストが生成AIを中心にあらゆる種類のテキストデータセットを検索、クラスタリング、分析するためのスケーラブルでユーザーフレンドリーなツールです。 Lilacは、大規模言語モデル(LLM)の出力の評価から、モデルのトレーニングのための非構造化データセットの理解と準備まで、さまざまなユースケースに使用できます。 LilacのツールをDatabricksに統合することで、顧客は自社の企業データを使用した生産品質の生成AIアプリケーションの開発を加速させることができます。
生成AI時代のデータ探索と理解
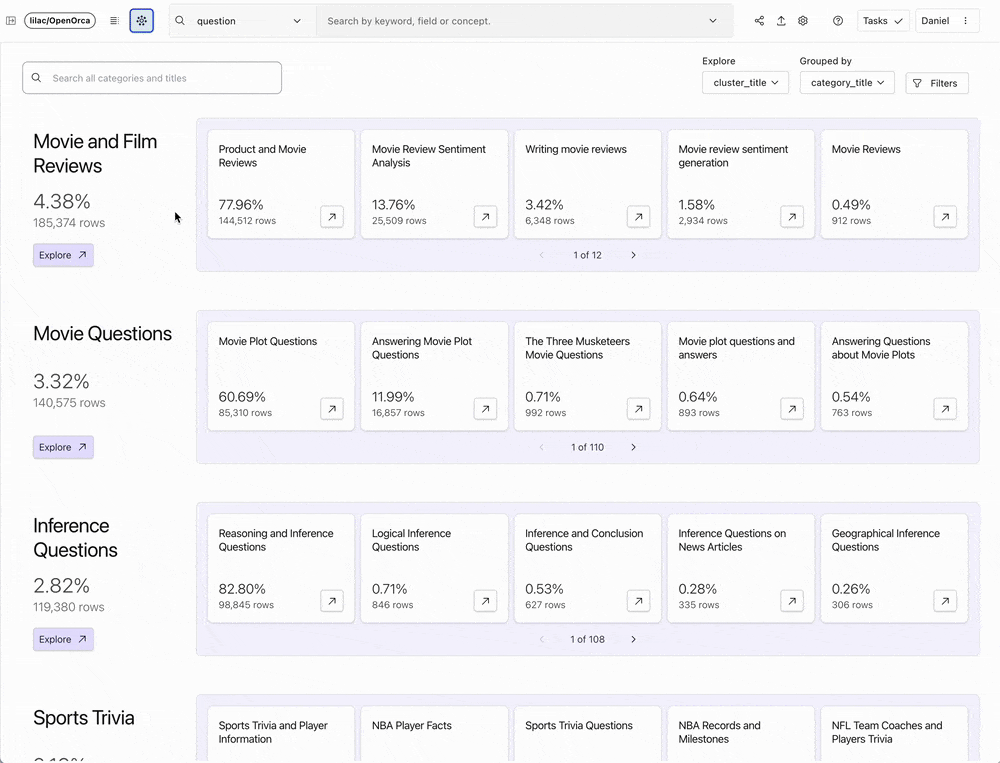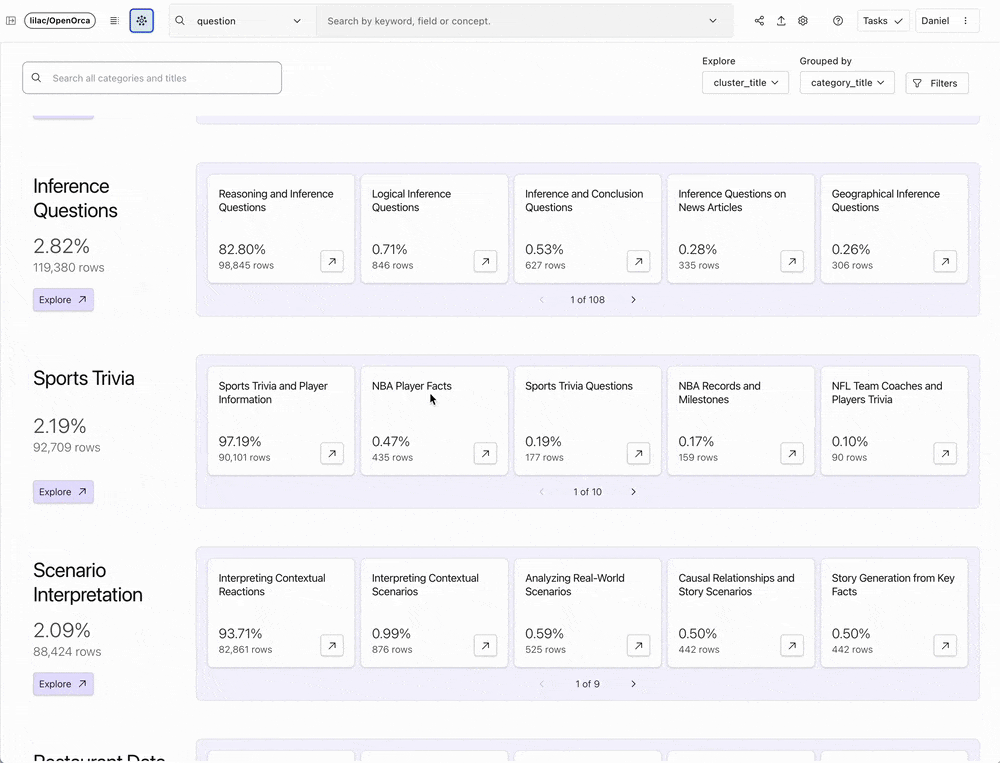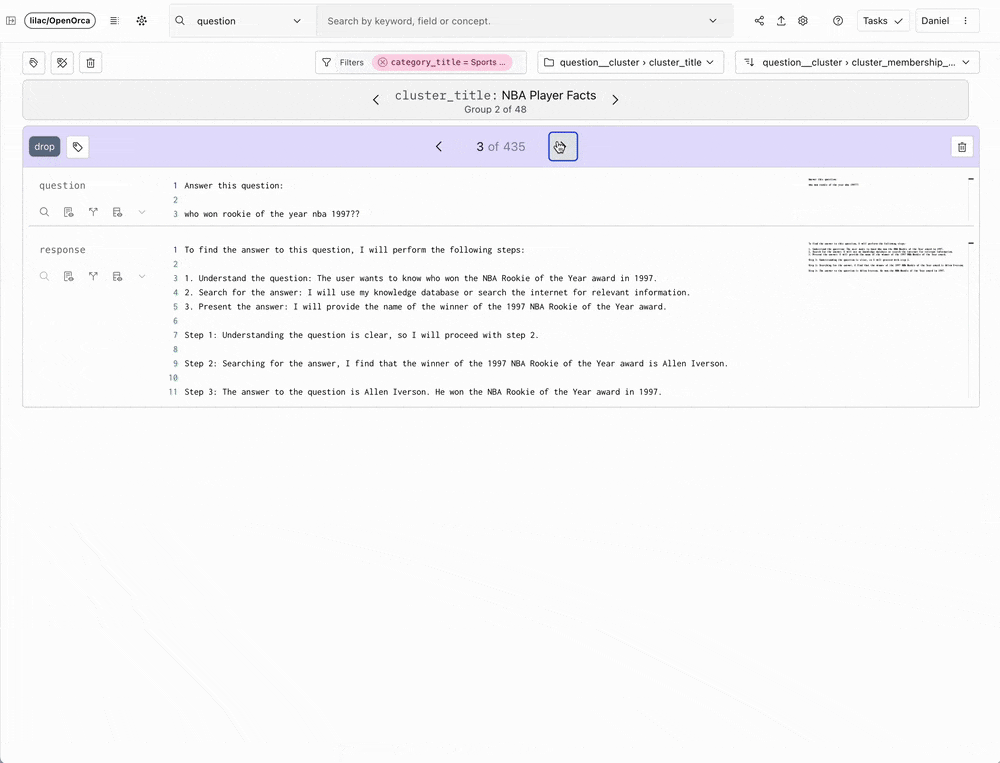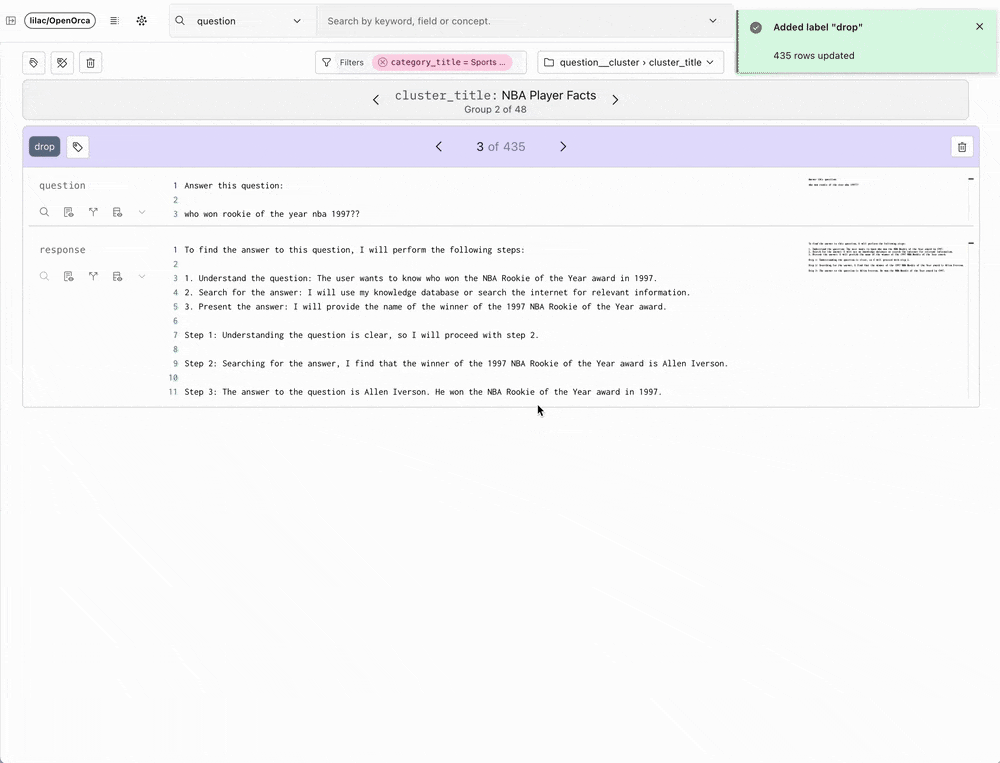
データは、モデルのトレーニングのためのデータセットの準備、モデルの出力の評価、RAG(Retrieval-Augmented Generation)データのフィルタリングなど、LLMベースのシステムの中核をなすものです。 これらのデータセットを探索し理解することは、質の高い生成AIアプリを構築する上で非常に重要です。 しかし、構造化されていないテキストデータを分析することは、生成AIの時代には非常に面倒で非常に難しくなります。 歴史的に、このプロセスは、拡張性に欠ける手作業で手間のかかる方法に悩まされてきました。 このような伝統的な方法は時間がかかるだけでなく、非常に困難であるため、多くの人が挑戦するのを躊躇してしまいます。
Lilacの紹介
Lilacの本質は、非構造化データの探索を容易にすることです。データサイエンティストやAI研究者が、扱いやすい方法でテキストデータセットを探索、理解、修正するための楽しいツールです。
Lilacは、データとのインタラクションを奨励し促進するスケーラブルなソリューションを提供することで、この分野に革新をもたらしました。 驚くほど直感的なユーザーインターフェイスとAIによる拡張機能を備えたLilacは、データ科学者や研究者がデータクラスターを探索し、人間のフィードバックや分類器を使用して新しいデータカテゴリーを導き出し、これらの洞察に基づいてデータセットを調整することを可能にします。 Lilacの開発チームは、モデル出力の偏りや有害性を分析し、RAGやLLMのファインチューニングやプリトレーニングのためのデータを準備できるように、製品を特別に構築しました。
Lilacのコアミッションは、エンドツーエンドの生成AI機能を顧客に提供するというDatabricksのコミットメントと一致しています。 彼らのオープンソースプロジェクトは、すでにデータサイエンスやAI研究コミュニティの幅広い聴衆を魅了しており、私たちのMosaic AIチームもその一人です。 Lilacの創設者であるDaniel SmilkovとNikhil Thoratは、それぞれGoogleで10年を過ごし、エンタープライズ規模のデータ品質ソリューション開発の専門知識を磨きました。 彼らの経験、チーム、テクノロジーをDatabricksに導入できることを嬉しく思います。
今後の展望:LilacとDatabricks
Databricks Mosaic AIでは、お客様自身のデータを使って高品質の生成AIアプリを開発するためのエンドツーエンドのツールを提供することを目標としています。 Lilacのテクノロジーは、統一されたプラット�フォームでLLMのアウトプットを評価・監視し、RAG、微調整、事前トレーニングのためのデータセットを準備することを容易にします。 LilacのテクノロジーをDatabricksに統合し、さらに多くのことを共有できることを楽しみにしています。 ご期待ください!
Databricksを使った生成AIアプリの構築については、オンデマンドウェビナー「The GenAI Payoff in 2024」をご覧ください。