
Ce document décrit les types d'événements que vous pouvez afficher dans vos graphiques. Un événement est une activité, telle qu'un redémarrage ou un plantage, qui affecte le fonctionnement d'un système. L'affichage d'événements peut vous aider à mettre en corrélation des données provenant de différentes sources lorsque vous tentez de résoudre un problème.
Pour chaque type d'événement, les informations suivantes sont fournies:
- Requête adaptée à une utilisation avec l'explorateur de journaux ou avec une règle d'alerte basée sur les journaux
- Références aux informations générales ou à la documentation de dépannage
La capture d'écran suivante illustre un graphique affichant une annotation, avec l'info-bulle de l'annotation activée:
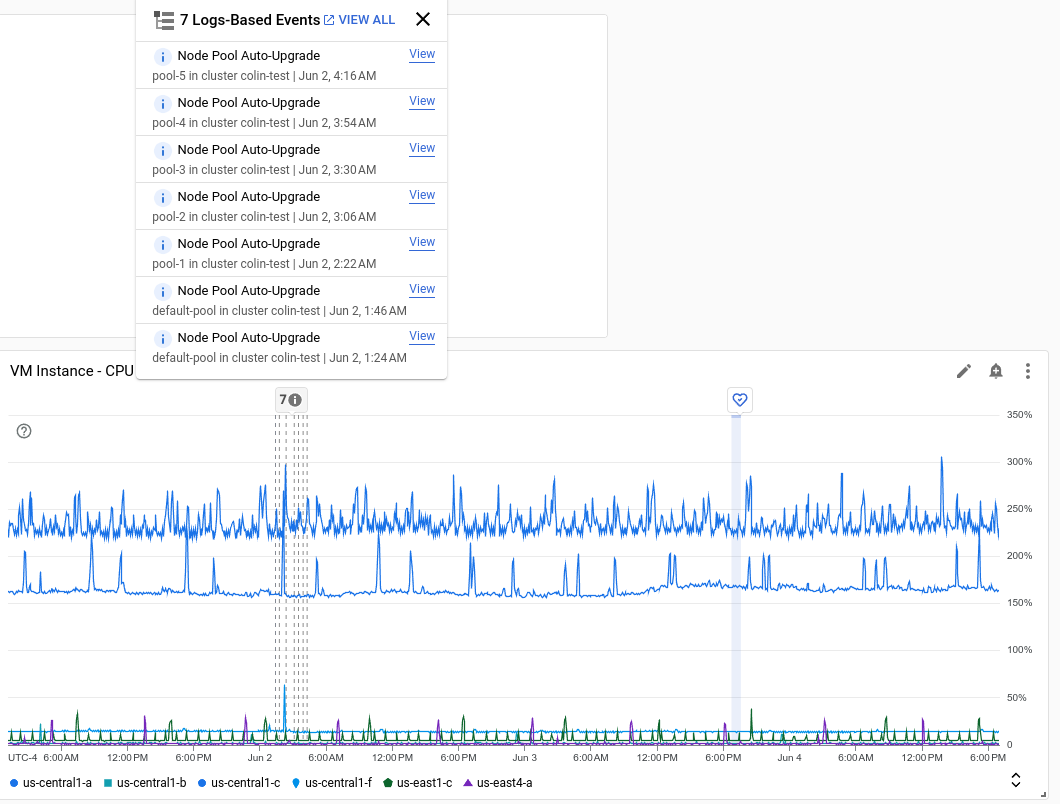
Chaque annotation peut répertorier plusieurs événements. Dans la capture d'écran précédente, un événement de déploiement GKE est listé.
Pour savoir comment afficher des événements dans vos tableaux de bord personnalisés, consultez Afficher les événements sur un tableau de bord.
Types d'événements Google Kubernetes Engine
Cette section décrit les types d'événements Google Kubernetes Engine pouvant être affichés dans un tableau de bord.
Charge de travail GKE corrigée ou mise à jour
Ce type d'événement vous aide à résoudre les problèmes liés au déploiement de la charge de travail GKE ou aux modifications de StatefulSet, car ces événements peuvent être corrélés à des régressions de performances ou à d'autres problèmes de performances. Ce type d'événement s'affiche lorsqu'une charge de travail est créée, mise à jour ou supprimée.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
resource.type=k8s_cluster protoPayload.methodName=(
io.k8s.apps.v1.deployments.create OR io.k8s.apps.v1.deployments.patch OR
io.k8s.apps.v1.deployments.update OR io.k8s.apps.v1.deployments.delete OR
io.k8s.apps.v1.deployments.deletecollection OR io.k8s.apps.v1.statefulsets.create OR
io.k8s.apps.v1.statefulsets.patch OR io.k8s.apps.v1.statefulsets.update OR
io.k8s.apps.v1.statefulsets.delete OR io.k8s.apps.v1.statefulsets.deletecollection OR
io.k8s.apps.v1.daemonsets.create OR io.k8s.apps.v1.daemonsets.patch OR
io.k8s.apps.v1.daemonsets.update OR io.k8s.apps.v1.daemonsets.delete OR
io.k8s.apps.v1.daemonsets.deletecollection
)
-protoPayload.authenticationInfo.principalEmail="system:addon-manager"
-protoPayload.request.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system)
Pour en savoir plus, consultez les pages Présentation du déploiement de charges de travail et Afficher les métriques d'observabilité.
Plantage d'un pod GKE
Ce type d'événement vous aide à identifier et à résoudre les plantages des pods GKE. Les plantages de pods peuvent être causés par l'épuisement de la mémoire ou par une erreur de l'application. Ce type d'événement s'affiche lorsque l'un des événements suivants se produit:
- État du pod :
CrashLoopBackoff - Le pod se termine par un code de sortie différent de zéro.
- Le pod se termine par une condition de mémoire insuffisante.
- Le pod a été évincé.
- Échec de la vérification d'aptitude/d'activité.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
(
log_id(events)
(
(resource.type=k8s_pod jsonPayload.reason=(BackOff OR Unhealthy OR Killing OR Evicted)) OR
(resource.type=k8s_node jsonPayload.reason=OOMKilling)
)
severity=WARNING
) OR (
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=k8s_cluster
(protoPayload.methodName=io.k8s.core.v1.pods.eviction.create OR
(protoPayload.methodName=io.k8s.core.v1.pods.delete
protoPayload.response.status.containerStatuses.state.terminated.exitCode:*
-protoPayload.response.status.containerStatuses.state.terminated.exitCode=0
)
)
)
Pour obtenir des informations de dépannage, consultez la section Résoudre les problèmes: CrashLoopBackOff.
Échec de la programmation d'un pod GKE
Ce type d'événement vous aide à identifier les pods qui ne peuvent pas être programmés sur un nœud et à résoudre les problèmes associés. Ce type d'événement s'affiche lorsque la planification des pods échoue pour l'une des raisons suivantes:
- Processeur de nœud insuffisant.
- Mémoire de nœud insuffisante.
- Aucun nœud pour les rejets ou les tolérances.
- Nombre de nœuds ayant atteint la limite maximale de pods.
- Pool de nœuds à la taille maximale.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
(
log_id(events) resource.type=k8s_pod jsonPayload.reason=(NotTriggerScaleUp OR FailedScheduling)
) OR (
log_id(container.googleapis.com/cluster-autoscaler-visibility)
resource.type=k8s_cluster jsonPayload.noDecisionStatus.noScaleUp:*
)
Pour obtenir des informations de dépannage, consultez la section Résoudre les problèmes de pod non programmable.
Échec de la création d'un conteneur GKE
Ce type d'événement vous aide à identifier et à résoudre les échecs de création d'un conteneur GKE. La création du conteneur peut échouer pour des raisons telles que l'échec de l'installation de volumes ou de l'extraction d'images.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
log_id(events) resource.type=k8s_pod jsonPayload.reason=(Failed OR FailedMount) severity=WARNING
Pour obtenir des informations de dépannage, consultez la section Dépannage: ImagePullBackOff et ErrImagePull.
Scaling à la hausse et à la baisse de l'autoscaler de pod
Cet événement vous offre une visibilité sur les rescales Autoscaler horizontal de pods, qui augmentent ou diminuent le nombre de pods en cours d'exécution pour une charge de travail. Pour en savoir plus, consultez la section Autoscaling horizontal des pods.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
resource.type=k8s_cluster log_id(events) jsonPayload.involvedObject.kind=HorizontalPodAutoscaler jsonPayload.reason=SuccessfulRescale
Scaling à la hausse et à la baisse de l'autoscaler de cluster
Cet événement vous donne une visibilité sur le moment où l'autoscaler de cluster augmente ou réduit le nombre de nœuds dans un pool de nœuds de votre cluster. Pour en savoir plus, consultez les sections À propos de l'autoscaling de cluster et Afficher les événements de l'autoscaler de cluster.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
(resource.type=k8s_cluster log_id(container.googleapis.com%2Fcluster-autoscaler-visibility) jsonPayload.decision:*)
Création et suppression d'un cluster
Cet événement suit les actions de création et de suppression de clusters GKE. Pour en savoir plus, consultez les pages Créer un cluster Autopilot, Créer un cluster zonal et Supprimer un cluster.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
google.container.v1alpha1.ClusterManager.CreateCluster OR
google.container.v1beta1.ClusterManager.CreateCluster OR
google.container.v1.ClusterManager.CreateCluster OR
google.container.v1alpha1.ClusterManager.DeleteCluster OR
google.container.v1beta1.ClusterManager.DeleteCluster OR
google.container.v1.ClusterManager.DeleteCluster
)
operation.first=true
Mise à jour du cluster
Cet événement permet de suivre les mises à jour de clusters GKE. Les mises à jour incluent les mises à niveau automatiques de la version du plan de contrôle ainsi que les mises à niveau manuelles et les modifications de la configuration du cluster. Pour en savoir plus, consultez les pages Mettre à niveau manuellement un cluster ou un pool de nœuds et Mettre à niveau un cluster standard.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.PatchCluster OR
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.UpdateCluster
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateCluster OR
google.container.v1.ClusterManager.UpdateCluster
)
operation.first=true
)
protoPayload.metadata.operationType=(UPGRADE_MASTER OR REPAIR_CLUSTER OR UPDATE_CLUSTER)
Mise à jour du pool de nœuds
Cet événement permet de suivre les mises à jour de pools de nœuds GKE. Les mises à jour incluent les mises à niveau automatiques de la version du pool de nœuds ainsi que les mises à niveau manuelles, les modifications de configuration et les redimensionnements. Pour en savoir plus, consultez les pages Mettre à niveau manuellement un cluster ou un pool de nœuds et Mettre à niveau un cluster standard.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
resource.type=gke_nodepool log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.RepairNodePool
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateNodePool OR
google.container.v1.ClusterManager.UpdateNodePool OR
google.container.v1beta1.ClusterManager.SetNodePoolSize OR
google.container.v1.ClusterManager.SetNodePoolSize OR
google.container.v1beta1.ClusterManager.SetNodePoolManagement OR
google.container.v1.ClusterManager.SetNodePoolManagement OR
google.container.v1beta1.ClusterManager.SetNodePoolAutoscaling OR
google.container.v1.ClusterManager.SetNodePoolAutoscaling
)
operation.first=true
)
Types d'événements Cloud Run
Cette section décrit les types d'événements Cloud Run pouvant être affichés dans un tableau de bord.
Déploiement Cloud Run
Ce type d'événement vous aide à identifier et à résoudre les échecs de déploiement de Cloud Run. Le déploiement peut échouer pour différentes raisons : compte de service supprimé, autorisations incorrectes, échec de l'importation d'un conteneur ou échec du démarrage d'un conteneur, par exemple.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloud_run_revision protoPayload.methodName=google.cloud.run.v1.Services.ReplaceService
Pour obtenir des informations de dépannage, consultez la page Résoudre les problèmes liés à Cloud Run.
Types d'événements Cloud SQL
Cette section décrit les types d'événements Cloud SQL pouvant être affichés dans un tableau de bord.
Basculement Cloud SQL
Ce type d'événement vous aide à déterminer quand des basculements manuels ou automatiques se produisent. Un basculement se produit lorsqu'une instance ou une zone subit une défaillance et que l'instance de secours devient la nouvelle instance principale. Lors d'un basculement, Cloud SQL passe automatiquement à l'instance de secours pour diffuser les données.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
resource.type=cloudsql_database
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=cloudsql.instances.failover
operation.last=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.autoFailover
)
)
Pour en savoir plus, consultez la section À propos de la haute disponibilité.
Démarrage ou arrêt de Cloud SQL
Ce type d'événement vous permet d'identifier qu'une instance Cloud SQL a été démarrée, arrêtée ou redémarrée manuellement. Lorsqu'une instance est arrêtée, toutes les connexions, les fichiers ouverts et les opérations en cours d'exécution sont également arrêtés.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloudsql_database protoPayload.methodName=cloudsql.instances.update operation.last=true protoPayload.metadata.intents.intent=(START_INSTANCE OR STOP_INSTANCE)
Pour en savoir plus, consultez les sections À propos de la haute disponibilité et Démarrer, arrêter et redémarrer des instances.
Stockage Cloud SQL
Ce type d'événement vous aide à identifier les événements liés à l'espace de stockage Cloud SQL, y compris lorsque l'espace de stockage de la base de données est saturé et lorsqu'une base de données est arrêtée parce qu'elle atteint sa capacité de stockage. Les bases de données ayant atteint leur capacité de stockage et pour lesquelles le stockage automatique n'est pas activé peuvent être arrêtées pour éviter toute corruption des données.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
resource.type=cloudsql_database
(
(
(log_id(cloudsql.googleapis.com%2Fpostgres.log) OR log_id(cloudsql.googleapis.com%2Fmysql.err))
textPayload=~"No space left on device"
severity=(ERROR OR EMERGENCY)
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.databaseShutdownOutOfStorage
)
)
Types d'événements Compute Engine
Cette section décrit les types d'événements Compute Engine pouvant être affichés dans un tableau de bord.
Arrêts de machines virtuelles
Ce type d'événement vous permet d'identifier les arrêts de machines virtuelles (VM), y compris les réinitialisations et arrêts déclenchés manuellement, les arrêts du système d'exploitation invité, les interruptions de maintenance et les erreurs d'hôte.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
beta.compute.instances.reset OR v1.compute.instances.reset OR
beta.compute.instances.stop OR v1.compute.instances.stop
)
operation.first=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=(
compute.instances.hostError OR
compute.instances.guestTerminate OR
compute.instances.terminateOnHostMaintenance
)
)
)
Pour en savoir plus, consultez les pages Arrêter et démarrer une VM et Résoudre les problèmes d'arrêt et de redémarrage de VM.
Échec du démarrage de l'instance de VM
Cet événement permet de suivre les échecs de démarrage des instances de VM Compute Engine. L'événement affiche les échecs de démarrage dus à des ruptures de stock, à l'épuisement de l'espace d'adresses IP, au dépassement de quota ou aux erreurs d'intégrité de la VM protégée.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(beta.compute.instances.insert OR v1.compute.instances.insert)
protoPayload.status.message=(ZONE_RESOURCE_POOL_EXHAUSTED OR IP_SPACE_EXHAUSTED OR QUOTA_EXCEEDED)
) OR (
log_id(compute.googleapis.com%2Fshielded_vm_integrity)
severity="ERROR"
)
)
Erreur de l'OS invité de l'instance de VM
Cet événement permet de suivre les erreurs spécifiques au système d'exploitation invité des instances de VM Compute Engine, telles qu'elles sont enregistrées dans les journaux de la console série. Les erreurs suivies sont les suivantes : disque saturé, échec de l'installation du système de fichiers et échecs de démarrage qui activent le mode d'urgence Linux.
Pour que ces événements soient visibles, vous devez activer la journalisation des données en sortie du port série sur Cloud Logging en définissant serial-port-logging-enable=true dans la VM ou dans les métadonnées du projet. Pour en savoir plus, consultez la page Activer et désactiver la journalisation des données en sortie du port série.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
resource.type=gce_instance
log_id(serialconsole.googleapis.com%2Fserial_port_1_output)
textPayload=~("No space left on device" OR "Failed to mount" OR "You are in emergency mode")
Mise à jour du groupe d'instances géré
Ce type d'événement vous permet d'identifier le moment où votre groupe d'instances géré (MIG) a été mis à jour. Par exemple, des VM ont été ajoutées ou supprimées, ou la limite de taille a été mise à jour. Pour en savoir plus, consultez la section Appliquer automatiquement les mises à jour de configuration de VM dans un MIG.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
resource.type=gce_instance_group_manager log_id(cloudaudit.googleapis.com%2Factivity) operation.first=true protoPayload.methodName=(beta.compute.instanceGroupManagers.patch OR v1.compute.instanceGroupManagers.patch)
Pour en savoir plus, consultez les pages Utiliser des instances gérées et Résoudre les problèmes liés aux groupes d'instances gérés.
Autoscaler de groupe d'instances géré
Cet événement permet de suivre les décisions de scaling prises par l'autoscaler d'un MIG d'instances géré. Ces décisions peuvent inclure des modifications de la taille recommandée pour un MIG géré ou un changement de l'état de l'autoscaler lui-même. Pour en savoir plus, consultez la page Effectuer l'autoscaling des groupes d'instances.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
resource.type=autoscaler log_id(cloudaudit.googleapis.com%2Fsystem_event) protoPayload.methodName=(compute.autoscalers.resize OR compute.autoscalers.changeStatus)
Types d'événements de test de disponibilité
Cette section décrit les types d'événements de test de disponibilité pouvant être affichés sur un tableau de bord.
Échec du test de disponibilité
Ce type d'événement vous permet d'identifier les échecs des tests de disponibilité dans les régions configurées.
Si vous souhaitez créer une règle d'alerte basée sur les journaux pour ce type d'événement, utilisez la requête suivante:
log_id(monitoring.googleapis.com%2Fuptime_checks) ( resource.type=uptime_url OR resource.type=gce_instance OR resource.type=gae_app OR resource.type=k8s_service OR resource.type=servicedirectory_service OR resource.type=cloud_run_revision OR resource.type=aws_ec2_instance OR resource.type=aws_elb_load_balancer ) labels.uptime_result_type=UptimeCheckResult severity=NOTICE
Pour obtenir des informations de dépannage, consultez Résoudre les problèmes liés aux surveillances synthétiques et aux tests de disponibilité.
Étapes suivantes
Pour savoir comment afficher des événements dans vos tableaux de bord, consultez Afficher les événements sur un tableau de bord.