
Neste tutorial, você usará o Striim para migrar o Oracle® Database Enterprise Edition 18c ou mais recente de um ambiente local ou de uma nuvem para uma instância do Cloud SQL para PostgreSQL no Google Cloud. O tutorial usa tabelas no esquema de amostra de RH do Oracle.
Este tutorial é destinado a arquitetos de bancos de dados corporativos, engenheiros de bancos de dados e proprietários de dados que planejam usar o Striim para migrar ou replicar bancos de dados Oracle para o Cloud SQL para PostgreSQL. Você precisa ter uma compreensão básica de como usar o Striim para criar pipelines. Você também precisa estar familiarizado com oInterface da interface da Web, dos conceitos principais do Striim e como criar um aplicativo usando Designer de fluxo do Striim.
O Striim é um parceiro de tecnologia de migração de banco de dados do Google Cloud. O Striim simplifica as migrações on-line usando uma interface do tipo arrastar e soltar para configurar o movimento contínuo de dados entre os bancos de dados. Para migrações para o Google Cloud, o Striim oferece uma plataforma de streaming não intrusiva para extração, transformação e carregamento (ETL) que é eficiente de implantar e simples de iterar. Para criar o pipeline de migração, use o Designer de fluxo do Striim ao longo deste tutorial.
Se a migração do banco de dados não for algo que você conhece, consulte esta palestra tecnológica do Cloud Next '19.
Arquitetura
A migração do banco de dados usando o Striim envolve dois estágios de movimentação de dados sequenciais:
- Estágio 1: uma replicação única do banco de dados Oracle.
- Etapa 2: a replicação contínua de cada alteração confirmada no sistema de banco de dados de origem, usando a captura de dados de alteração (CDC, na sigla em inglês).
O diagrama a seguir ilustra uma arquitetura básica de implantação:

Essa arquitetura envolve a execução do aplicativo Striim em uma instância do Compute Engine. Ele se conecta a um banco de dados Oracle hospedado no local ou na nuvem e grava dados em uma instância do Cloud SQL para PostgreSQL no Google Cloud.
Para evitar problemas de rede ou conectividade entre as instâncias do Striim e do Cloud SQL, use a mesma rede para as duas instâncias. É possível implantar o Striim a partir do Google Cloud Marketplace em uma instância do Compute Engine ou, se precisar de alta disponibilidade, implantar o Striim como um cluster
Para este tutorial, faça a implantação do Cloud Marketplace.
A vantagem de implantar o Striim a partir do Cloud Marketplace é que ele permite que você se conecte a vários bancos de dados e fontes de dados usando seus adaptadores integrados. É possível conectar os adaptadores usando o Designer de fluxo, a interface interativa de arrastar e soltar do Striim, para formar um gráfico acíclico. Esse gráfico também é conhecido como pipeline Striim ou aplicativo Striim.
O caso de uso de migração neste tutorial usa três adaptadores Striim:
- Leitor de banco de dados: lê dados do banco de dados de origem Oracle durante o estágio de carregamento inicial.
- Leitor do Oracle: lê dados usando o LogMiner do banco de dados de origem do Oracle durante o estágio de replicação contínua de dados.
- Database Writer: grava dados no banco de dados do Cloud SQL para PostgreSQL durante o carregamento inicial e durante a replicação contínua de dados.
Objetivos
Prepare seu banco de dados Oracle como um banco de dados de origem para migração ou replicação.
Prepare um banco de dados do Cloud SQL para PostgreSQL como o banco de dados de destino para migração ou replicação.
Cumpra os pré-requisitos para instalar e executar o Striim.
Converta o esquema do banco de dados Oracle para o esquema correspondente no PostgreSQL.
Realize a carga inicial do seu banco de dados Oracle para o Cloud SQL para PostgreSQL.
Configure a replicação contínua do banco de dados Oracle para o Cloud SQL para PostgreSQL.
Custos
Neste documento, você usará os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
A solução Striim no Cloud Marketplace oferece uma licença de avaliação gratuita limitada. Quando o teste expirar, as cobranças de uso serão cobradas da sua conta do Google Cloud. Também é possível conseguir licenças do Striim diretamente no Striim para implantação no local e em uma máquina virtual (VM) do Compute Engine. Também pode haver custos associados à execução de um banco de dados Oracle fora do Google Cloud.
Antes de começar
- Faça login na sua conta do Google Cloud. Se você começou a usar o Google Cloud agora, crie uma conta para avaliar o desempenho de nossos produtos em situações reais. Clientes novos também recebem US$ 300 em créditos para executar, testar e implantar cargas de trabalho.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
-
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud.
-
Verifique se a cobrança está ativada para o seu projeto do Google Cloud.
Este tutorial pressupõe que você já tem o seguinte:
- Um Oracle Database Enterprise Edition 18c ou posterior para Linux x86-64 que você quer migrar.
- Um Compute Engine executando o CentOS que tem o Striim instalado. É possível implantar o Striim por meio da solução do Google Cloud Marketplace.
Como preparar o banco de dados Oracle
As seções a seguir discutem as alterações de configuração que você pode precisar para conectar ao seu banco de dados Oracle e migrá-lo com o Striim. Para detalhes de configuração, consulte Tarefa de configuração básica do Oracle.
Escolha a origem do Oracle CDC
Embora haja diferentes fontes do Oracle CDC, este tutorial usa o LogMiner. É possível ler sobre as opções alternativas em Fontes alternativas do CDC do Oracle.
Preparar o Oracle Database Enterprise Edition 18c (ou posterior)
Para preparar o banco de dados do Oracle, siga as instruções na página de documentação do Striim para as seguintes etapas:
- Ative o
archivelogdo Striim. - Ative os dados de registro complementares do Striim.
- Ative a geração de registros da chave primária do Striim.
Crie um usuário do Oracle com privilégios do LogMiner para o Striim.
Para executar essas etapas, você precisa se conectar ao banco de dados do contêiner (CDB), mesmo se estiver migrando um CDB ou um banco de dados plugável (PDB). Recomendamos a instalação e o uso do SQL*Plus para interagir com o banco de dados Oracle.
Crie uma tabela
quiescemarkerdo Striim.O adaptador Oracle Reader do Striim para CDC precisa de uma tabela para armazenar metadados ao desativar um aplicativo. Se você usar o LogMiner como uma origem para CDC (como este tutorial faz), precisará da tabela quiescemarker. Você deve estar conectado ao CDB ao seguir as etapas para criar a tabela.
Estabeleça a conectividade de rede entre seu banco de dados Oracle e a instância Striim.
Por padrão, o listener Oracle está na porta
1521. Verifique se o endereço IP da instância do Striim tem permissão para se conectar à porta do listener do Oracle e se nenhuma regra de firewall a bloqueia. A porta em que o listener do Oracle está configurado está no arquivo$ORACLE_HOME/network/admin/tnsnames.ora.Anote o número de alteração do sistema (SCN, na sigla em inglês) do banco de dados Oracle.
O SCN é um carimbo de data/hora interno usado para fazer referência às alterações feitas em um banco de dados.
No banco de dados Oracle, use a SCN mais antiga:
SELECT MIN(start_scn) FROM gv$transaction;Copie esse número. Você precisará dele mais tarde nas etapas do pipeline de replicação contínua.
Como preparar a instância do Striim
Para mais informações sobre os sistemas operacionais compatíveis com o Striim, consulte os requisitos do sistema. Para usar o Oracle Reader com o LogMiner, coloque o driver JDBC da Oracle no caminho de classe do Java na sua instância do Striim. Siga estas etapas em cada servidor Striim que executa um adaptador do Oracle Reader:
- Faça login na sua conta do Oracle e, em seguida, faça o download do arquivo
ojdbc8.jarna máquina local.- Se você não tiver uma conta da Oracle, crie uma.
Clique no link Download do arquivo
ojdbc8.jar.- Se você aceitar os termos de licença, clique em Li e aceito o Contrato de Licença da Oracle para fazer o download do arquivo.
No Cloud Shell, crie um bucket do Cloud Storage e faça o upload do arquivo
.jarpara ele:gsutil mb -b on -l REGION gs://BUCKET_NAME gsutil cp PATH/ojdbc8.jar gs://BUCKET_NAMESubstitua:
- REGION: a região em que você quer criar o bucket do Cloud Storage
- BUCKET_NAME: o nome do intervalo do Cloud Storage em que você quer armazenar o arquivo
ojdbc8.jar - PATH: o caminho para onde você fez o download do arquivo
ojdbc8.jar.
Depois que o arquivo for salvo na máquina local, recomendamos que você faça upload do arquivo
.jarem um bucket do Cloud Storage para fazer o download dele em qualquer instância.Abra uma sessão SSH com sua instância do Striim, faça o download do arquivo
.jarpara sua instância do Striim e coloque-o no diretório/opt/striim/lib:sudo su - striim gsutil cp gs://BUCKET_NAME/ojdbc8.jar /opt/striim/libVerifique se o arquivo
ojdbc8.jartem as permissões de arquivo corretas:sudo ls -l /opt/striim/lib/ojdbc8.jarA saída será exibida assim:
-rwxrwx--- striim striim(Opcional) Se o arquivo
.jarnão tiver as permissões anteriores, defina as permissões corretas:sudo chmod 770 /opt/striim/lib/ojdbc8.jar sudo chown striim /opt/striim/lib/ojdbc8.jar sudo chgrp striim /opt/striim/lib/ojdbc8.jarPare e reinicie o Striim.
Depois de fazer qualquer alteração de configuração (como as alterações anteriores de permissão), você deve reiniciar o Striim.
Se você estiver usando a distribuição do CentOS 7 Linux, interrompa o Striim:
sudo systemctl stop striim-node sudo systemctl stop striim-dbmsSe você estiver usando a distribuição do CentOS 7 Linux, inicie o Striim:
sudo systemctl start striim-dbms sudo systemctl start striim-node
Se você quiser saber mais sobre como interromper e reiniciar o Striim para um sistema operacional diferente, consulte Como iniciar e interromper o Striim.
Instale o cliente psql na instância do Striim.
Use esse cliente para se conectar à instância do Cloud SQL e criar esquemas posteriormente neste tutorial.
Como preparar o esquema do Cloud SQL para PostgreSQL
Quando você copia ou replica continuamente dados tabulares de um banco de dados para outro, o Striim normalmente exige que o banco de dados de destino contenha tabelas correspondentes com o esquema correto. O Google Cloud não tem um utilitário para preparar o esquema, mas é possível usar o utilitário de conversão de esquema do Striim ou um utilitário de código aberto como o ora2pg.
Manter chaves estrangeiras durante o carregamento inicial
Durante a fase de carregamento inicial, preste atenção no tratamento de chaves estrangeiras. Chaves estrangeiras estabelecem a relação entre as tabelas em um banco de dados relacional. A criação ou a inserção fora de ordem de uma chave estrangeira no banco de dados de destino pode destruir a relação entre as duas tabelas. Se a integridade entre os dois bancos de dados for comprometida, poderão ocorrer erros. Portanto, é importante gerar todas as declarações de chave estrangeira em um arquivo separado durante a exportação do esquema mais adiante nesta seção.
Durante a replicação contínua nos pipelines do CDC, os eventos do banco de dados de origem são propagados para o banco de dados de destino na ordem em que ocorrem. Se você mantiver as chaves estrangeiras corretamente na origem, as operações de chave externa serão replicadas da origem para o banco de dados de destino na mesma ordem.
Por outro lado, o pipeline de carga inicial assume como padrão o carregamento das tabelas em ordem alfabética. Se você não desativar as chaves estrangeiras antes do carregamento inicial, ocorrerão erros de violação de chave externa. Para replicar dados durante o carregamento inicial das tabelas de banco de dados de origem para as tabelas de destino no Cloud SQL para PostgreSQL, desative as restrições de chave externa nas tabelas. Caso contrário, as restrições podem ser violadas durante o processo de replicação.
Desde junho de 2021, o Cloud SQL para PostgreSQL não é compatível com as opções de configuração para desativar as restrições de chave estrangeira.
Para lidar com restrições de chave estrangeira:
- Envie todas as declarações de chave estrangeira para um arquivo separado durante a exportação do esquema.
- Crie esquemas de tabelas no banco de dados do Cloud SQL para PostgreSQL sem as restrições de chave estrangeira.
- Conclua a replicação inicial de dados.
- Aplicar as restrições de chave externa nas tabelas.
- Crie o pipeline de replicação contínua.
Este tutorial oferece duas opções de conversão de esquema, que as seções a seguir explicam:
- O utilitário de conversão de esquema do Striim (recomendado)
- O conversor de esquema do banco de dados Oracle para PostgreSQL (Ora2Pg)
Converter o esquema usando o utilitário de conversão de esquema do Striim
Use o utilitário de conversão de esquema do Striim para preparar o Cloud SQL para PostgreSQL para integrar dados ao esquema de destino e criar tabelas que reflitam o banco de dados de origem do Oracle.
A ferramenta de conversão de esquema do Striim converte os seguintes objetos de origem em objetos de destino equivalentes:
- Tabelas
- Chaves primárias
- Tipos de dados
- Restrições exclusivas
- Restrições
NOT NULL - Chaves estrangeiras
Usando o utilitário de conversão de esquema do Striim, é possível analisar o banco de dados de origem e gerar scripts DDL para criar esquemas equivalentes no banco de dados de destino.
Recomendamos que você crie manualmente o esquema no banco de dados de destino usando os scripts DDL gerados. É mais fácil selecionar um subconjunto das tabelas, exportar o esquema e importá-lo para o banco de dados de destino do Cloud SQL para PostgreSQL.
O exemplo a seguir demonstra como preparar o banco de dados de destino do Cloud SQL para PostgreSQL para a carga inicial importando o esquema usando o utilitário de conversão de esquema do Striim:
Abra uma conexão SSH com a instância do Striim.
Acesse o diretório
/opt/striim:cd /opt/striimListe todos os argumentos:
bin/schemaConversionUtility.sh --helpExecute o utilitário de conversão de esquema e inclua as sinalizações apropriadas para seu caso de uso:
bin/schemaConversionUtility.sh \ -s=oracle \ -d=SOURCE_DATABASE_CONNECTION_URL \ -u=SOURCE_DATABASE_USERNAME \ -p=SOURCE_DATABASE_PASSWORD \ -b=SOURCE_TABLES_TO_CONVERT \ -t=postgres \ -f=falseSubstitua:
- SOURCE_DATABASE_CONNECTION_URL: URL de conexão do banco de dados Oracle, por exemplo,
"jdbc:oracle:thin:@12.123.123.12:1521/APPSPDB.WORLD"ou"jdbc:oracle:thin:@12.123.123.12:1521:XE" - SOURCE_DATABASE_USERNAME: nome de usuário do Oracle a ser usado para se conectar ao banco de dados Oracle
- SOURCE_DATABASE_PASSWORD: senha do Oracle a ser usada para se conectar ao banco de dados Oracle
- SOURCE_TABLES_TO_CONVERT: nomes de tabelas do banco de dados de origem usados para converter esquemas
Verifique se você está usando o argumento
-f=false. Esse argumento exporta as declarações de chave estrangeira para um arquivo separado.A pasta de saída pode conter alguns ou todos os arquivos a seguir. Para mais detalhes sobre esses arquivos, consulte a documentação do utilitário de conversão de esquema do Striim.
Nome do arquivo de saída Descrição converted_tables.sqlContém todas as tabelas convertidas que não precisam de coerção converted_tables_with_striim_intelligence.sqlContém todas as tabelas convertidas que foram convertidas com alguma coerção conversion_failed_tables.sqlContém tabelas em que a conversão foi tentada, mas um mapeamento não foi obtido converted_foreignkey.sqlContém todas as declarações de restrição de chave estrangeira conversion_failed_foreignkey.sqlContém todas as conversões de chave estrangeira com falha conversion_report.txtContém um relatório detalhado da conversão do esquema. Neste tutorial, você usa o arquivo
converted_tables.sqlpara criar tabelas equivalentes no banco de dados do Cloud SQL para PostgreSQL sem restrições de chave estrangeira. Após a replicação inicial, use o arquivoconverted_foreignkey.sqlpara aplicar as restrições de chave estrangeira.- SOURCE_DATABASE_CONNECTION_URL: URL de conexão do banco de dados Oracle, por exemplo,
Converter o esquema usando o Ora2Pg
Outra opção para converter esquemas de tabelas da Oracle em esquemas equivalentes do PostgreSQL é o utilitário Ora2Pg. É possível instalar esse utilitário em uma VM separada do Google Cloud.
O utilitário Ora2Pg converte o esquema do Oracle e exporta as instruções DDL necessárias para criar tabelas equivalentes no banco de dados do PostgreSQL. Essas instruções DDL são exportadas em um arquivo de saída denominado output.sql.
Durante a exportação de esquema, exporte e salve todas as declarações de chave estrangeira em um arquivo separado usando a seguinte sinalização no arquivo de configuração Ora2Pg:
FILE_PER_FKEYS 1
Por padrão, as chaves estrangeiras são exportadas para o arquivo de saída principal (output.sql). Quando você ativa a sinalização FILE_PER_FKEYS (1), as chaves estrangeiras são exportadas para um arquivo separado chamado FKEYS_output.sql
Neste tutorial, você usa o arquivo output.sql para criar tabelas equivalentes no banco de dados do Cloud SQL para PostgreSQL sem restrições de chave estrangeira.
Após a replicação inicial, use o arquivo FKEY_output.sql para aplicar as restrições de chave estrangeira.
Como preparar a instância do Cloud SQL para PostgreSQL
Para permitir que o Striim grave dados em uma instância do Cloud SQL para PostgreSQL, é necessário criar uma instância do Cloud SQL. Você também precisa criar as tabelas do banco de dados e o esquema em que o Striim grava:
No Cloud Shell, crie uma instância do Cloud SQL para PostgreSQL. Recomendamos que você configure o Cloud SQL para usar um endereço IP particular. Use o parâmetro
--networkpara configurar este endereço:$INSTANCE_NAME=INSTANCE_NAME gcloud beta sql instances create INSTANCE_NAME \ --database-version=POSTGRES_12 \ --network=NETWORK \ --cpu=NUMBER_CPUS \ --memory=MEMORY_SIZE \ --region=REGIONSubstitua:
- INSTANCE_NAME: o nome da instância;
- NETWORK: o nome da rede VPC que você usa para essa instância.
- NUMBER_CPUS: número de vCPUs na instância
- MEMORY_SIZE: quantidade de memória para a instância. Por exemplo, 3.072 MiB ou 9 GiB. O GiB será usado se você não especificar a unidade.
- REGION: a região em que você criou o bucket do Cloud Storage
Crie um nome de usuário e uma senha na instância do Cloud SQL:
CLOUD_SQL_USERNAME=CLOUD_SQL_USERNAME gcloud sql users create $CLOUD_SQL_USERNAME \ --instance=$INSTANCE_NAME \ --password=CLOUD_SQL_PASSWORDSubstitua:
- CLOUD_SQL_USERNAME: um nome de usuário da instância do Cloud SQL
- CLOUD_SQL_PASSWORD: a senha do nome de usuário do Cloud SQL
Este usuário recebe a propriedade das tabelas do PostgreSQL. O Striim também usa as credenciais desse usuário para se conectar ao banco de dados do Cloud SQL para PostgreSQL.
Os arquivos de esquema exportados durante a etapa de conversão de esquema podem ter uma instrução DDL que concede propriedade a um usuário, como no exemplo a seguir:
CREATE SCHEMA <SCHEMA_NAME>; ALTER SCHEMA <SCHEMA_NAME> OWNER TO <USER>;
Talvez seja necessário substituir
SCHEMA_NAMEporCLOUD_SQL_SCHEMAeUSERpeloCLOUD_SQL_USERNAMEcriado anteriormente.Criar um banco de dados PostgreSQL
CLOUD_SQL_DATABASE_NAME=CLOUD_SQL_DATABASE_NAME gcloud sql databases create $CLOUD_SQL_DATABASE_NAME \ --instance=$INSTANCE_NAMESubstitua:
- CLOUD_SQL_DATABASE_NAME: nome do banco de dados do PostgreSQL
Configurar o banco de dados do Cloud SQL para PostgreSQL para permitir o acesso pela instância Striim. As opções de conectividade dependem de você ter configurado a instância do Cloud SQL para usar um endereço IP público ou privado.
Se você configurou um endereço IP público, adicione o endereço IP da instância do Striim como um endereço autorizado na instância do Cloud SQL. A captura de tela a seguir mostra como fazer isso no Console do Google Cloud:

Se você configurou um endereço IP particular, as opções de conectividade disponíveis dependem se a instância do Cloud SQL e o Striim instâncias estão na mesma rede VPC.
Se a instância do Striim estiver na mesma rede VPC que a instância do Cloud SQL, ela poderá estabelecer conexão com a instância do Cloud SQL.
A captura de tela a seguir mostra que a instância do Cloud SQL está associada à rede VPC padrão. Se a instância do Striim também tiver sido criada na rede VPC padrão, ela poderá se conectar de modo particular à instância do Cloud SQL.
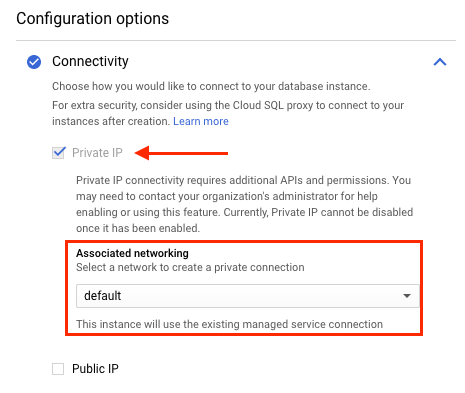
Se a instância do Striim estiver em uma rede VPC diferente da instância do Cloud SQL, configure o acesso a serviço particular na rede VPC da instância do Striim.
Crie esquemas de tabela sem restrições de chave externa no banco de dados do Cloud SQL para PostgreSQL.
Para exportar
output.sqldurante a etapa de conversão do esquema, use o arquivooutput.sqlpara criar os esquemas.Para exportar
converted_tables.sqldurante a etapa de conversão de esquema, use o arquivoconverted_tables.sqlpara criar os esquemas.É possível executar qualquer script usando qualquer cliente PostgreSQL com conectividade com a instância do Cloud SQL para PostgreSQL. No entanto, recomendamos usar o cliente PostgreSQL instalado anteriormente na instância do Striim.
Crie os esquemas:
psql -h HOSTNAME -p CLOUD_SQL_PORT -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAME -f PATH_TO_MAIN_SQL_FILESubstitua:
- HOSTNAME: endereço IP da instância do Cloud SQL
- CLOUD_SQL_PORT: porta da instância do Cloud SQL para se conectar. Por padrão, essa porta é
5432. - PATH_TO_MAIN_SQL_FILE: caminho para o script principal na instância Striim
Exemplo:
psql -h 12.123.123.123 -d testdb -U hr -p 5432 -f output.sql
Verifique se as tabelas foram criadas:
Conecte-se ao banco de dados do Cloud SQL para PostgreSQL:
psql -h HOSTNAME -p 5432 -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAMEListe as tabelas neste banco de dados:
\dtA saída é uma lista de tabelas que o script de conversão do esquema da tabela criou na etapa anterior.
Crie uma tabela de checkpoint no banco de dados do Cloud SQL para PostgreSQL:
Conecte-se ao banco de dados do Cloud SQL para PostgreSQL:
psql -h HOSTNAME -p 5432 -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAMECrie a tabela:
CREATE TABLE chkpoint ( id character varying(100) primary key, sourceposition bytea, pendingddl numeric(1), ddl text);O Striim precisa dessa tabela para manter os checkpoints durante o processo de replicação contínua.
Como carregar o banco de dados Oracle no Cloud SQL para banco de dados PostgreSQL
Nesta seção, descrevemos a replicação inicial única do banco de dados Oracle para o banco de dados do Cloud SQL para PostgreSQL.
Estabelecer uma conexão com o Oracle do Striim
Siga as orientações em Como executar o Striim no Google Cloud. Para a carga inicial, use o adaptador de leitor de banco de dados do Striim para se conectar ao Oracle pelo Striim. Você também pode usar o assistente CDC do Striim.
No adaptador Striim Database Reader, acesse Sources e, em seguida, pesquise e selecione Database na lista.
Defina as seguintes propriedades na janela Database.
- Nome: identifique esse componente do pipeline de migração.
- Adaptador:
DatabaseReader URL de conexão: insira uma string exclusiva para se conectar ao banco de dados Oracle:
jdbc:oracle:thin:@HOSTNAME:ORACLE_PORT:SIDOU
jdbc:oracle:thin:@HOSTNAME:ORACLE_PORT/PDB_OR_CDB_SERVICE_NAMESubstitua:
- ORACLE_PORT: porta do banco de dados Oracle (
1521por padrão) - SID: banco de dados SID da Oracle
- PDB_OR_CDB_SERVICE_NAME: nome do serviço Oracle PDB ou CDB: se suas tabelas estiverem em um PDB, use
PDB_SERVICE_NAME; Se eles estiverem em um CDB, useCDB_SERVICE_NAME.
É possível encontrar a porta e o nome do serviço no arquivo
tnsnames.oralocalizado em$ORACLE_HOME/network/admin/tnsnames.orana instância do Oracle.- ORACLE_PORT: porta do banco de dados Oracle (
Nome de usuário e senha: use o usuário Oracle (
c##striimusuário) criado nas etapas de pré-requisito. O Striim usa esse nome de usuário e senha para se conectar ao banco de dados Oracle e ler as tabelas.Tabelas: para Oracle, o leitor de banco de dados também precisa de uma lista de nomes de tabela para replicar. Essa propriedade é especificada no campo "Tabelas" em Mostrar propriedades opcionais. O formato dessa propriedade é o seguinte:
ORACLE_SCHEMA.ORACLE_TABLE_NAMESubstitua:
- ORACLE_SCHEMA: nome do esquema do Oracle
- ORACLE_TABLE_NAME: nomes de tabelas da Oracle nesse esquema
Também é possível especificar várias tabelas e visualizações materializadas como uma lista separada por ponto e vírgula ou com os seguintes caracteres curinga:
%: qualquer série de caracteres_: qualquer caractere únicoPor exemplo,
HR.%lê todas as tabelas no esquema de RH. Pelo menos uma tabela precisa corresponder ao caractere curinga. Caso contrário, o leitor do banco de dados falhará com o seguinte erro:Could not find tables specified in the databaseQuisce On IL Completion: alterne este campo para verde deslizando-o para a direita para pausar o pipeline quando a carga inicial estiver concluída.
Saída para: nomear a saída do adaptador. Use uma string com diferenciação de maiúsculas e minúsculas sem caracteres ou espaços especiais.
Clique em Save. As propriedades do adaptador exibem:

Testar a conexão
Agora que você se conectou ao Oracle pelo Striim, teste a conexão.
Clique na lista suspensa Criado para testar a conectividade do Striim com o banco de dados Oracle.
Clique em Implantar aplicativo.
Selecione a saída desse adaptador e clique em Visualizar para exibir os dados em tempo real enquanto o Striim os lê na origem.

Clique na lista suspensa Implantado e em Iniciar app.
(Opcional) Clique na lista suspensa Deployed e, em seguida, clique em Undeploy App para corrigir os erros.
(Opcional) Clique em Retomar app depois que todos os erros forem corrigidos para reiniciar o app.
Clique no grupo de implantação padrão.
Verifique se a opção Validar mapeamentos de tabelas está ativada e clique em Implantar.
O painel de dados de visualização e o status do pipeline mudam para Quiesced.
Neste ponto do tutorial, você verificou com sucesso que o Striim pode estabelecer uma conexão com o banco de dados Oracle e ler os dados dentro dele.
Adicionar um banco de dados do Cloud SQL para PostgreSQL como destino
Para essa migração, grave os dados na instância do Cloud SQL para PostgreSQL. O Striim fornece um adaptador genérico de gravador de banco de dados, chamado Database Writer, que pode ser usado na migração.
- No Designer de fluxo do Striim, acesse Destinos. Pesquise e selecione Cloud SQL Postgres na lista.
- Arraste Database Writer para o pipeline.
Defina as seguintes propriedades:
Adaptador:
DatabaseWriterURL de conexão: insira uma string exclusiva para estabelecer uma conexão com a instância do Cloud SQL:
jdbc:postgresql://CLOUD_SQL_IP_ADDRESS:CLOUD_SQL_PORT/CLOUD_SQL_DATABASE_NAME?stringtype=unspecifiedSubstitua:
- CLOUD_SQL_IP_ADDRESS: endereço IP da instância do Cloud SQL
Exemplo:
jdbc:postgresql://12.123.12.12:5432/postgres?stringtype=unspecifiedNome de usuário e senha: digite o nome de usuário e a senha do Cloud SQL criados anteriormente.
Tabelas: crie um mapeamento dos nomes de tabelas do banco de dados Oracle para nomes de tabelas do Cloud SQL. Especifique qual tabela de banco de dados Oracle é gravada em qual tabela Cloud SQL. Esse mapeamento usa o seguinte formato:
ORACLE_SCHEMA.ORACLE_TABLE_NAME,CLOUD_SQL_SCHEMA.CLOUD_SQL_TABLE_NAMESubstitua:
- CLOUD_SQL_SCHEMA: nome do esquema do PostgreSQL
- CLOUD_SQL_TABLE_NAME: nome da tabela do PostgreSQL
Para mapear várias tabelas, use o símbolo de caractere curinga (%) no campo Tabelas. Por exemplo:
HR.%,hr.%Os campos obrigatórios para o gravador de banco de dados são marcados na seguinte captura de tela:

Implantar o pipeline de migração
Depois que o pipeline de migração estiver pronto, implante-o pelo Striim Flow Designer e inicie o aplicativo. Também é possível visualizar os dados que estão sendo replicados em tempo real. Use os relatórios do Monitoring para acompanhar o progresso da replicação. Para acompanhar o progresso, selecione o ícone Progresso do aplicativo.

No Striim Flow Designer, implante o pipeline de migração. Clique na lista suspensa Criado e, em seguida, clique em Implantar aplicativo. Após a conclusão do carregamento inicial, o status do pipeline muda para
Quiesced.Clique em Cancelar a implantação do aplicativo para reverter a implantação.
Verifique se a carga de dados foi bem-sucedida verificando a contagem de linhas:
SELECT COUNT(*) FROM <TARGET CLOUD SQL TABLE>;Você verá uma saída diferente de zero. Caso contrário, o carregamento de dados falhou.
O carregamento inicial de dados do banco de dados Oracle para o Cloud SQL para PostgreSQL é atômico. O carregamento de dados inteiro é bem-sucedido ou o carregamento de dados inteiro falha. Se o carregamento inicial falhar, você precisará carregar os dados novamente.
Como ativar restrições de chave estrangeira nas tabelas do Cloud SQL para PostgreSQL
Após a conclusão do carregamento inicial, ative as restrições de chave estrangeira nas tabelas de destino. Use o arquivo com declarações de chave externa (FKEY_output.sql ou converted_foreignkey.sql) que você criou durante a conversão do esquema.
No Striim, abra uma sessão SSH.
Crie restrições de chave estrangeira nas tabelas:
psql -h HOSTNAME -d CLOUD_SQL_DATABASE_NAME -U CLOUD_SQL_USERNAME -p CLOUD_SQL_PORT -f PATH_TO_FOREIGN_KEY_FILESubstitua:
- CLOUD_SQL_USERNAME: nome de usuário do Cloud SQL para PostgreSQL
PATH_TO_FOREIGN_KEY_FILE: caminho para o script com restrições de chave externa na instância do Striim
Exemplo:
psql -h 12.123.123.123 -d testdb -U hr -p 5432 -f output.sql
Replicação contínua do banco de dados Oracle para o Cloud SQL para PostgreSQL
Depois de concluir o carregamento de dados inicial, crie um pipeline separado para replicar as alterações no banco de dados Oracle. Enquanto o sistema permanecer em execução, esse pipeline também manterá o banco de dados de origem sincronizado com o banco de dados de destino.
Estabelecer uma conexão com o Oracle do Striim
Para replicação contínua, use o adaptador Striim Oracle Reader para se conectar do Striim ao banco de dados Oracle. Esse adaptador Striim pode ler dados CDC do Oracle.
- No adaptador do Striim Oracle Reader, navegue até Sources.
Pesquise Oracle e selecione Oracle CDC na lista preenchida.
Defina as seguintes propriedades:
URL da conexão:
HOSTNAME:ORACLE_PORT/SIDOU
HOSTNAME:ORACLE_PORT/CDB_SERVICE_NAMESubstitua:
- CDB_SERVICE_NAME: nome do serviço de CDB da Oracle
O URL de conexão é uma string exclusiva usada para se conectar ao banco de dados Oracle. Ao contrário do adaptador do leitor de banco de dados usado para o carregamento inicial, o nome do serviço CDB é usado, independentemente de as tabelas de banco de dados estarem em um PDB ou CDB.
Por exemplo,
12.123.123.12:1521/ORCLCDB.WORLD.Nome de usuário/senha: use o nome de usuário do Oracle (
c##striimusuário) criado nas etapas de pré-requisito.Este usuário do Oracle precisa ter os privilégios para ler suas tabelas.
Tabelas: você também precisa de uma lista de nomes de tabelas para replicar. O nome é especificado no formato a seguir, dependendo se as tabelas estão em um CDB ou PDB.
Para a tabela do CDB:
ORACLE_SCHEMA.ORACLE_TABLE_NAMEPara a tabela PDB:
PDB_NAME.ORACLE_SCHEMA.ORACLE_TABLE_NAMESubstitua:
- PDB_NAME: nome do Oracle PDB
Esse comando replica suas tabelas de CDB ou PDB. Encontre seu
PDB_NAMEno arquivotnsnames.oralocalizado em$ORACLE_HOME/network/admin/tnsnames.orana instância do Oracle.Lembre-se de que
PDB_NAMEePDB_SERVICE_NAMEsão diferentes. Você usou oPDB_SERVICE_NAMEanteriormente na seção. Visualize o arquivotnsnames.orapara receber o nome do PDB:sudo su - oracle // Login as oracle user cat ORACLE_HOME/network/admin/tnsnames.oraA seguir, há um exemplo de
PDB_NAME(APPSPDB) no arquivotnsnames.ora:APPSPDB = (DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP) (HOST = orainst) (PORT = 1521)) ) (CONNECT_DATA = (SERVICE NAME = APPSPDB.WORLD) ) )Para especificar várias tabelas e visualizações materializadas como uma lista, separe os nomes das tabelas ou dos nomes de visualização por ponto e vírgula ou caractere curinga. Pelo menos uma tabela precisa corresponder ao caractere curinga. caso contrário, o Oracle Reader falhará com um erro
Could not find tables specified in the database.Iniciar SCN: para o pipeline contínuo, você precisa fornecer o SCN do banco de dados Oracle. O Striim precisa dele para começar a replicar todas as transações. Insira o valor do SCN que você gerou anteriormente.
Compatibilidade com PDB e CDB: é possível usar um CDB ou um PDB. expanda Mostrar propriedades opcionais e alterne a chave para a direita.
Tabela de marcadores simples: use o nome da tabela que você criou anteriormente.
A captura de tela a seguir fornece uma visão geral dos campos obrigatórios do adaptador do Oracle Reader:
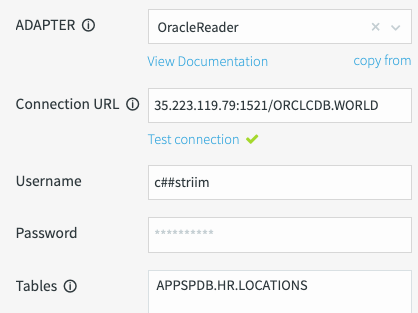
Testar conexão: clique em Testar conexão. O URL da conexão, o nome de usuário e a senha são necessários para testar a conectividade do banco de dados. Se o Striim conseguir estabelecer uma conexão, uma marca de seleção verde será exibida.
Teste a capacidade de Striim ler as tabelas do banco de dados Oracle:
- No adaptador Oracle Reader, selecione Implantar aplicativo.
- Selecione o grupo de implantação padrão.
- Clique em Implantar.
Clique no ícone de onda (Saída) do adaptador. O ícone de olho (Visualização) exibido é usado para visualizar os dados em tempo real conforme o Striim lê os dados na origem.
Clique em Iniciar app na lista suspensa Implantado.
Se ocorrer algum erro, selecione Cancelar implantação do app na mesma lista suspensa e corrija os erros. Depois de corrigir os erros, clique em Retomar app para reiniciar o aplicativo.
Quando o pipeline é iniciado, ele é atualizado para Em execução. Novas alterações na tabela de origem serão exibidas na janela de visualização. Como o adaptador do Oracle Reader usa CDC, as únicas alterações de tabela que aparecem no painel de dados de visualização são as que ocorrem após o lançamento do aplicativo.
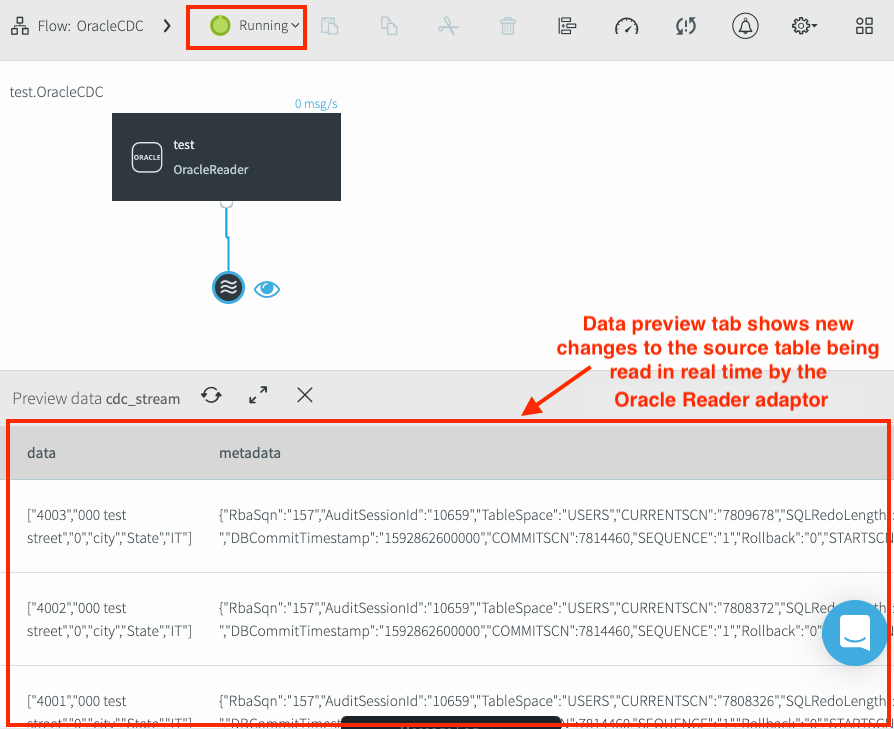
Verificar a capacidade de ler dados de CDC do Oracle
Para testar se o adaptador consegue ler novas alterações, siga estas instruções:
- Use instruções SQL para inserir novas transações nas tabelas de origem do Oracle.
- Verifique se as novas transações aparecem na guia Preview data do adaptador do Oracle Reader.
- Interrompa o aplicativo e clique em Cancelar implantação. Agora você está pronto para passar para a próxima etapa.
Até este ponto, você não adicionou um adaptador de destino ao pipeline. Nenhum dado será copiado, a menos que você adicione um adaptador de destino. Na próxima seção, você adicionará um adaptador de destino.
Adicionar um banco de dados do Cloud SQL para PostgreSQL como destino
Para gravar dados no banco de dados do Cloud SQL para PostgreSQL, você precisa adicionar um adaptador de gravador de banco de dados ao pipeline. Para o pipeline de replicação contínua, use o mesmo adaptador usado no pipeline de carga inicial.
- No Striim Flow Designer, acesse Targets, procure e selecione Cloud SQL Postgres na lista.
- Arraste Database Writer para o pipeline.
Defina as seguintes propriedades:
Adaptador:
DatabaseWriter.URL de conexão: insira o URL de conexão que você inseriu para estabelecer uma conexão com a instância do Cloud SQL:
jdbc:postgresql://CLOUD_SQL_IP_ADDRESS:CLOUD_SQL_PORT/CLOUD_SQL_DATABASE_NAME?stringtype=unspecifiedExemplo:
jdbc:postgresql://12.123.12.12:5432/postgres?stringtype=unspecifiedNome de usuário e senha: digite o nome de usuário e a senha do Cloud SQL criados anteriormente.
Tabelas: crie um mapeamento dos nomes de tabelas do banco de dados Oracle para os nomes das tabelas do Cloud SQL. Especifique qual tabela de banco de dados Oracle é gravada em qual tabela do Cloud SQL. Esse mapeamento usa o seguinte formato:
ORACLE_SCHEMA.ORACLE_TABLE_NAME,CLOUD_SQL_SCHEMA.CLOUD_SQL_TABLE_NAMEPara mapear várias tabelas, use o símbolo de caractere curinga (%) no campo Tabelas. Exemplo:
HR.%,hr.%Além dessas propriedades, você também precisa definir as seguintes propriedades para o pipeline de replicação contínua:
Clique em Mostrar propriedades opcionais.
Selecione o seguinte valor para o campo Código de exceção ignorável:
23505,NO_OP_UPDATE,NO_OP_DELETEComo você está iniciando o pipeline do CDC a partir de um ponto histórico, pode haver duplicatas. A eliminação de duplicações é feita no destino usando as propriedades de código de exceção ignoráveis anteriores. Os detalhes sobre os códigos de exceção podem ser encontrados na tabela a seguir:
Código de exceção Detalhes 23505O valor da chave primária duplicada viola a restrição exclusiva NO_OP_UPDATENão foi possível atualizar uma linha no destino, geralmente porque não havia uma chave primária correspondente NO_OP_DELETENão foi possível excluir uma linha no destino (normalmente porque não havia uma chave primária correspondente) Digite
chkpointno campo Tabela de pontos de verificação. O Striim usa essa tabela para armazenar metadados associados ao checkpoint do pipeline de replicação contínua.
Como ativar a recuperação e a criptografia
Antes de implantar o pipeline do CDC, é altamente recomendável que você ative a recuperação. Se o aplicativo Striim ou a VM falhar, ativar a recuperação ajuda a garantir que o Striim possa continuar o processamento. Essa etapa também ajuda a garantir uma semântica de processamento exata. Essas semânticas rastreiam o último checkpoint de leitura válido no banco de origem e o último checkpoint de gravação válido no banco de dados de destino. Se um aplicativo ou VM falhar, o Striim coordena os dois pontos de verificação para ajudar a garantir que nenhum dado seja perdido ou duplicado. A recuperação não se aplica a aplicativos de carregamento inicial.
Ativar recuperação
- No Striim Flow Designer, clique no ícone Configuration e selecione App Settings.
- Clique em Intervalo de recuperação.
- Digite
5e selecione Segundo na lista suspensa. - Clique em Ativar criptografia. O Striim criptografa todos os streams que movem dados entre os servidores Striim ou de um agente de encaminhamento para um servidor Striim.
Ativar criptografia
- No Striim Flow Designer, clique no ícone Configuration, selecione App Settings e, em Encryption, marque a caixa de seleção.
Consulte o site do Striim para saber mais sobre os métodos de recuperação do Striim.
Ativar exceções de geração de registros
Antes de implantar o pipeline de replicação contínua, recomendamos que você ative o armazenamento de exceções no Striim. Como parte do aplicativo CDC, pode haver duplicatas gravadas pelo aplicativo de carregamento inicial. O aplicativo Striim ignora esses erros, grava-os em um armazenamento (para análise e processamento) e continua o processamento.
- No Striim Flow Designer, selecione o ícone Exceções. O ícone mostra um ponto de exclamação entre duas setas curvas.
- Clique em Ativar.
Implante o pipeline.
Depois que o pipeline estiver pronto, implante-o e inicie o aplicativo. Também é possível visualizar os dados à medida que eles são replicados em tempo real e visualizar os relatórios de monitoramento. Quando o pipeline inicia a replicação contínua, o status do pipeline muda para Em execução.
- No adaptador Oracle Reader, selecione Implantar aplicativo.
- Selecione o grupo de implantação padrão.
- Clique em Implantar.
É possível manter o pipeline em execução pelo tempo que você quiser manter as tabelas do Oracle sincronizadas com as tabelas do Cloud SQL.
Você concluiu o tutorial. Se você tiver interesse em saber mais sobre outras fontes do Oracle CDC, veja as seções a seguir.
Origens alternativas do CDC do Oracle
Além do LogMiner, o adaptador do Striim pode ler bancos de dados Oracle dos arquivos de trilha XStream ou Oracle Golden Gate.
Para ler dados do XStream, use o leitor do adaptador do Oracle. O XStream pode ter melhor desempenho, mas requer uma licença Golden Gate e é compatível apenas com o Oracle Database 11.2.0.4.
Para ler arquivos de trilha do Golden Gate, use o adaptador de leitor de trilhas do GG do Striim.
A tabela a seguir descreve as diferenças entre o LogMiner e o XStream:
| Banco de dados Oracle Recursos do CDC |
Compatível com LogMiner? |
Compatível com XStream Out? |
|---|---|---|
Leitura de linguagem de definição de dados (DDL, na sigla em inglês), ROLLBACK e transações não confirmadas |
Sim | Não |
Como usar as funções DATA() e BEFORE() |
Sim | Não |
Como usar QUIESCE (consulte Comandos do console)
|
Sim | Não |
| Como receber eventos do CDC | Recebe eventos em lotes conforme definido pela propriedade FetchSize do Oracle Reader |
Recepção contínua de eventos de dados alterados |
| Como ler tabelas com tipos não compatíveis | Não lê a tabela | Lê as colunas de tipos compatíveis |
Limpeza
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados no tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
- No Console do Google Cloud, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir .
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
A seguir
- Confira a documentação do Striim: Guia de migração do Oracle para o Google Cloud PostgreSQL
- Assista ao vídeo sobre como migrar bancos de dados da Oracle para o Cloud SQL PostgreSQL.
- Para mais arquiteturas de referência, diagramas e práticas recomendadas, confira a Central de arquitetura do Cloud.
Oracle, Java e MySQL são marcas registradas da Oracle e/ou afiliadas. Outros nomes podem ser marcas registradas dos respectivos proprietários.