

Protecting users with differentially private synthetic training data
May 16, 2024
Alexey Kurakin, Research Engineer, Google Deepmind, and Natalia Ponomareva, Staff Software Engineer, Google Research
We describe our approach to generating differentially private synthetic data and its application to creating training data for on-device safety classification.
Quick links
Predictive models trained on large datasets with sophisticated machine learning (ML) algorithms are widely used throughout industry and academia. Models trained with differentially private ML algorithms provide users with a strong, mathematically rigorous guarantee that details about their personal data will not be revealed by the model or its predictions.
In “Harnessing large-language models to generate private synthetic text”, we described new methods for generating differentially private synthetic data, which is data that has the key characteristics of the original data, but is entirely artificial and offers strong privacy protection. In addition to training predictive models, synthetic data can be used for auxiliary tasks such as feature engineering, model selection and hyperparameter tuning. Synthetic data can also be manually inspected while debugging an ML algorithm, and it can be retained for an extended period of time for ongoing monitoring and alerting.
At Google, these methods have been used to generate differentially private synthetic data for several applications, including safe content classification, which we describe below. Our approach may be of wider interest to the research community, particularly to organizations without abundant in-house ML expertise who want to share their sensitive data with external researchers and academics without compromising privacy.
Differential privacy
Differential privacy is a formal mathematical framework for quantifying how well a data analysis algorithm (typically called a mechanism) preserves the privacy of users who contribute to the input dataset. When analyzing a mechanism within the framework of differential privacy, one considers two scenarios from the perspective of a single user — the user’s data is either present in the input dataset or it is absent. The mechanism is said to be private if its output is very similar in each of these scenarios. In the context of ML, the output can be a model, or, as in our case, synthetic data.
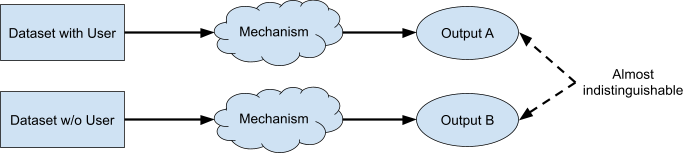
Differential privacy ensures that the outputs of a mechanism with and without using a particular user’s data will be almost indistinguishable. Diagram inspired by Damien Desfontaines.
More formally, a mechanism satisfies ε-differential privacy if the probability of an output under each of these scenarios does not vary by more than a factor eε. Lower values of ε imply stronger privacy, and the value ε = ∞ indicates that the mechanism is not private at all. More details are available in this readable introduction to differential privacy.
One of the most useful properties of differential privacy is that a mechanism’s privacy guarantees are preserved under any transformation of its output. Therefore, when developing a pipeline for generating private synthetic data, it suffices to verify that one step of the process satisfies differential privacy in order to ensure that all subsequent steps — as well as all uses of the generated data — are privacy preserving. For this purpose, we use a well-known private ML algorithm called differentially private stochastic gradient descent (DP-SGD) in a key step of our data generation pipeline.
Generating synthetic data by privately fine-tuning LLMs
Generating high-quality private synthetic data is significantly harder than privately training an accurate predictive model. Datasets are of much higher dimension than models, and instead of being used for a single task, a synthetic dataset is intended for a diverse variety of tasks, which places a high burden on the quality of the data.
Previous work has combined large-language models (LLMs) with DP-SGD to generate private synthetic data [1, 2, 3, 4]. The procedure starts with an LLM trained on public data. The parameters of the LLM are then fine-tuned using DP-SGD on a sensitive dataset. Using DP-SGD ensures that any text samples produced by the LLM do not compromise the privacy of users who contributed their data to the sensitive dataset. Next, the LLM is used to generate a synthetic dataset similar to the sensitive dataset. Finally, the synthetic data can be used for downstream tasks, like training a predictive model. Since LLMs are typically trained on a huge corpus (often internet-scale), fine-tuning an existing model using sensitive data is more effective than training a model from scratch on sensitive data, which is typically limited.
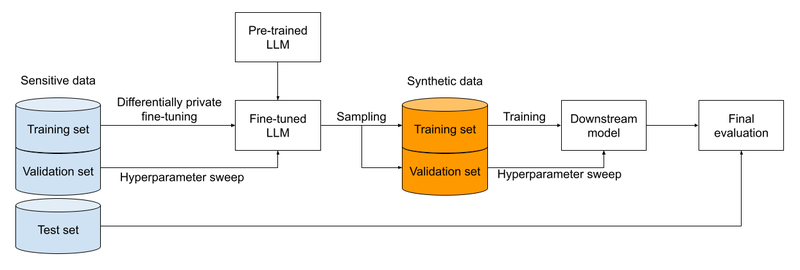
Framework for synthetic data generation and evaluation.
Parameter-efficient private fine-tuning
In the aforementioned work on generating private synthetic data, all the weights in the LLM model were modified during private training, which is computationally intensive. Further, as shown in our paper, it also leads to subpar results when used with DP-SGD. Therefore we explored parameter-efficient techniques that train a much smaller number of weights. For example, LoRa fine-tuning, which replaces each weight matrix W in the model with W + LR, where L and R are low rank matrices, and only trains L and R. Prompt fine-tuning inserts a “prompt tensor” at the start of the network and only trains its weights, effectively only modifying the input prompt used by the LLM.
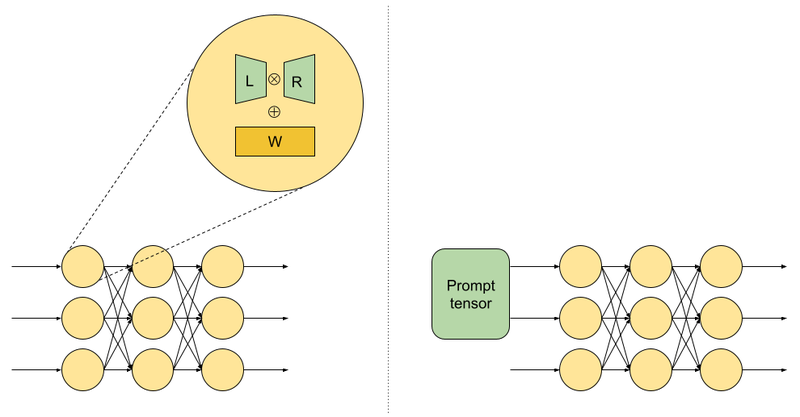
LoRa fine-tuning (left) and prompt fine-tuning (right). Only parameters in green are modified during training. Diagram inspired by Hu et al (2021) and Lester et al (2021).
For non-private training, parameter-efficient fine-tuning involves a trade-off: Training fewer parameters is faster, but the quality of the synthetic data is lower. Our key empirical finding is that when training the model with DP-SGD, using parameter-efficient fine-tuning can significantly improve the quality of the synthetic data. Our explanation for this phenomenon is related to how DP-SGD preserves privacy. In each iteration of DP-SGD, noise is added to the gradient vector, and this noise has magnitude proportional to the norm of the gradient. When there are many trainable parameters in the model, each gradient has a very large norm, and so the required amount of added noise is significant, which degrades the quality of the model’s output. Reducing the number of trainable parameters reduces the noise. Additionally, DP-SGD is quite slow when training large-parameter models, so having fewer parameters in the model yields more time for performing an extensive sweep of the model’s hyperparameters, which in turn leads to better performance.
Of course, this approach can not be pushed too far, and a model with very few trainable parameters will also have very poor output. As we explain below, we found that there is a “sweet spot” for the number of parameters that maximizes data quality while preserving privacy.
Empirical results
To evaluate our methodology, we first trained Lamda-8B, a decoder-only LLM with roughly 8 billion parameters, on a corpus of English text gathered from the Internet and other sources. We then privately fine-tuned this LLM using three publicly available, academic, open-sourced “sensitive” datasets (which are not actually sensitive, but were treated as such for the purposes of this evaluation exercise): IMDB movie reviews, Yelp business reviews, and AG news articles. We ensured that these datasets were disjoint from the original training corpus so that they did not contaminate the subsequent evaluation. LoRa fine-tuning modified roughly 20 million parameters, while prompt fine-tuning modified only about 41 thousand parameters. We used the fine-tuned LLM to generate synthetic versions of each of the sensitive datasets, and finally trained predictive classifiers on each synthetic dataset. For the review benchmarks, the goal of the classifier was to predict the polarity of the review (positive or negative), while the goal of the AG news classifier was to predict the topic of the article (from five possible topics). We tried two model architectures for the classifiers, one based on BERT embeddings, and another based on a word-level convolutional neural network. We evaluated the accuracy of each classifier on a held-out subset of the original data. As a baseline for comparison, we also tried a more direct method, which trains each predictive classifier on the original data with differential privacy (using aforementioned DP-SGD), without the intermediate step of generating synthetic data.
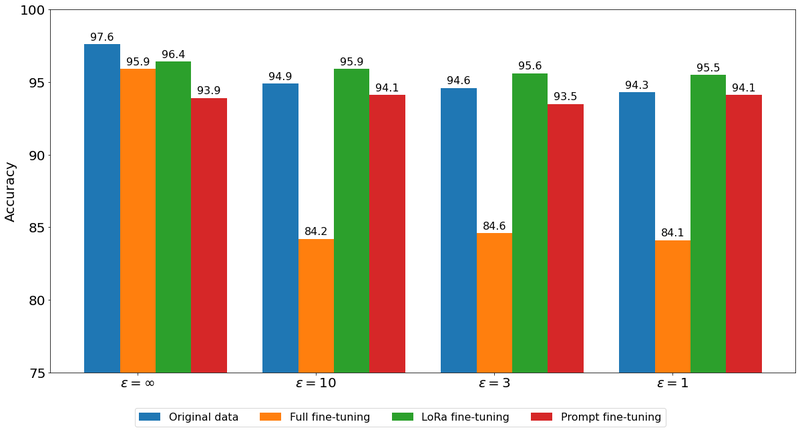
Test set accuracy of BERT-based classifiers trained on the original Yelp data (blue bar) and synthetic Yelp data (other bars) at various privacy levels.
The chart above shows the performance of BERT-based classifiers trained on Yelp data (additional results can be found in our paper). Two findings stand out. First, the accuracy of a classifier trained on synthetic data is maximized when the synthetic data is generated by an LLM that was LoRa fine-tuned on the sensitive data. The LoRa approach tunes many fewer weights than the total number of weights in the model, but many more weights than the prompt-based tuning approach, thus strongly suggesting that there is a ”sweet spot” for parameter-efficient private fine-tuning. Second, in many cases, a classifier trained on private synthetic data outperforms a classifier privately trained on the original sensitive data. One possible explanation for this striking result is that the LLM used to generate the synthetic data was trained on a corpus of publicly available data, in addition to the sensitive data, which likely improved the prediction accuracy of the model.
Application to on-device safety classification
Google recently announced updates to a version of Google's state-of-the-art foundation model that is intended for mobile devices. To ensure that every response generated by the model is appropriate to show to users, the model’s output is monitored by a high-precision Transformer-based safety classifier that was trained to detect inappropriate content. Since unsafe content is highly sensitive, the judgments of the safety classifier must not inadvertently reveal information about the users whose data was included in the classifier's training set. So we generated a differentially private synthetic version of the unsafe content using our method described above (training only on internal data), and then trained the safety classifier on this synthetic data. Generating synthetic data also allowed us to use more "hands-on" techniques for modifying the training data to improve classifier performance, such as filtering, augmenting and mixing.
Acknowledgements
This work is the result of a collaboration between multiple people across Google Research, Google DeepMind and Google's User Protections team, including (in alphabetical order by last name): Hanwen Chen, Catherine Huang, Alexey Kurakin, Liam MacDermed, Shree Pandya, Natalia Ponomareva, Jane Shapiro, Umar Syed, Andreas Terzis, Sergei Vassilvitskii.
Quick links
Other posts of interest
-

May 30, 2024
CodecLM: Aligning language models with tailored synthetic data- Conferences & Events ·
- Machine Intelligence ·
- Natural Language Processing
-

May 30, 2024
Few-shot tool-use doesn’t really work (yet)- Generative AI ·
- Natural Language Processing
-

May 29, 2024
ChatDirector: Enhancing video conferencing with space-aware scene rendering and speech-driven layout transition- Human-Computer Interaction and Visualization ·
- Machine Intelligence