
Effective large language model adaptation for improved grounding
May 24, 2024
Xi Ye, Student Researcher, and Ruoxi Sun, Research Scientist, Google Cloud
We introduce AGREE, a learning-based framework that enables LLMs to provide accurate citations in their responses, making them more reliable and increasing user trust.
Quick links
Over the last few years, large language models (LLMs) have showcased remarkable advances in various capabilities, such as multi-hop reasoning, generating plans, and using tools and APIs, all of which demonstrate promise for numerous downstream applications. However, their reliability in real-world deployment is sometimes compromised by the issue of "hallucination", where such models generate plausible but nonfactual information. Hallucinations tend to occur more frequently when LLMs are prompted with open-ended queries that require drawing upon broad world knowledge. This poses risks in domains that demand high factual accuracy, such as news reporting and educational content.
Grounding aims to combat the hallucination problems of LLMs by tracking back their claims to reliable sources. Such a system would not only provide coherent and helpful responses, but also supports its claims with relevant citations to external knowledge.
With this in mind, in our paper “Effective large language model adaptation for improved grounding”, to be presented at NAACL 2024, we introduce a new framework for grounding of LLMs. This framework, which we call AGREE (Adaptation for GRounding EnhancEment), enables LLMs to self-ground the claims in their responses and to provide precise citations to retrieved documents, increasing user trust and expanding their potential applications. Comprehensive experiments on five datasets suggest AGREE leads to substantially better grounding than prior prompting-based or post-hoc citing approaches, often achieving relative improvements of over 30%.
A holistic approach to improve grounding
Prior research on improving grounding mostly follows two prominent paradigms. One is to add citations post-hoc using an additional natural language inference (NLI) model. This approach heavily relies on the knowledge within an LLM’s embeddings and does not extend well to facts beyond that. Another common method for grounding is to leverage the instruction-following and in-context learning capabilities of LLMs. With this second approach, LLMs are required to learn grounding just from a few demonstration prompts, which, in practice, does not lead to the best grounding quality.
Our new framework, AGREE, takes a holistic approach to adapt LLMs for better grounding and citation generation, combining both learning-based adaptation and test-time adaptation (TTA). Different from prior prompting-based approaches, AGREE fine-tunes LLMs, enabling them to self-ground the claims in their responses and provide accurate citations. This tuning on top of the pre-trained LLMs requires well-grounded responses (with citations), for which we introduce a method that can automatically construct such data from unlabeled queries. The self-grounding capability of tuned LLMs further grants them a TTA capability that can iteratively improve their responses.
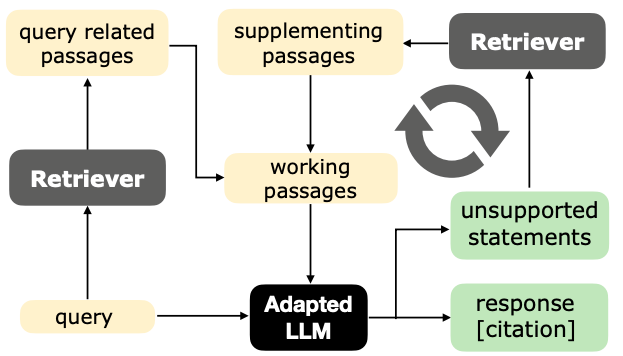
High-level illustration of AGREE. At training time, we generate training data automatically and adapt LLMs for better grounding via fine-tuning. At test time, we introduce a test-time adaptation mechanism to iteratively improve their responses.
Tuning LLMs for self-grounding
During training, AGREE collects synthetic data from unlabeled queries, which we then use to fine-tune a base LLM into an adapted LLM that can self-ground its claims. Given an unlabeled query, we first retrieve relevant passages from reliable sources (e.g., Wikipedia) using a retriever model. We present the retrieved passages to the base LLM and sample a set of initial responses (without citations). Next, we use an NLI model (in our case, a variant of Google TrueNLI model), which can judge whether a claim is supported by a passage, to help add citations to the initial responses. For each sentence in an initial response, we use the NLI model to find the passage that can support the sentence, and add a citation to the supporting passage accordingly. We do not add citations to those sentences that do not have a passage that can back them up.
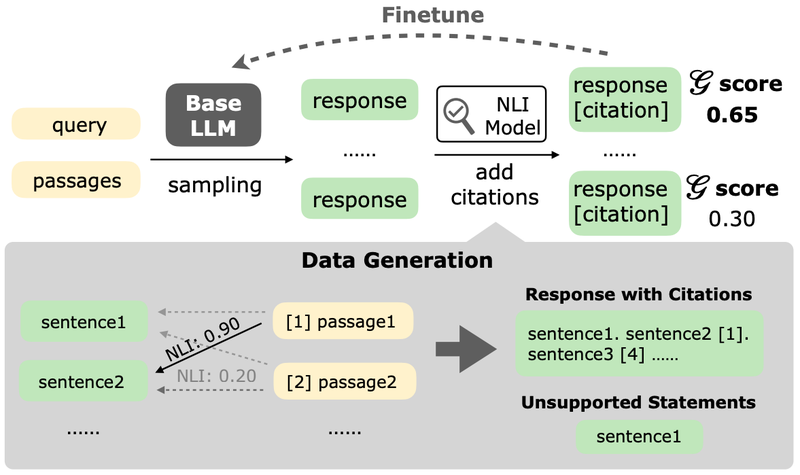
Illustration of the tuning process. We sample responses from the base model, use an NLI model to add citations to the sampled responses, and tune the base model with the best-grounded response.
Now that the initial responses are augmented with automatically created citations, we then select the best-grounded responses to fine-tune the base LLM. We determine which are the best grounded by measuring the averaged grounding score over all the sentences in the response according to the NLI model. With these responses, we tune the base LLM to teach it to include citations to its responses. In addition, we also teach base LLM to indicate those sentences in its responses that are unsupported, which will be useful during test-time adaptation so the LLM can iteratively refine its responses.
We create the tuning data using the queries from three commonly used datasets, Natural Questions, StrategyQA, and Fever, since they provide diverse text and require different types of reasoning processes.
Test-time adaptation
At test time, AGREE introduces an iterative inference strategy that empowers the LLM to actively seek additional information based on its self-generated citations. Given a query, we first use the retriever model to obtain an initial passage set. Next, we iteratively invoke the following procedure: 1) At each iteration, the adapted LLM generates a response containing citations to the passage set and finds any unsupported statements that do not have citations. 2) Then, we actively present more information to the LLM based on the citation information — if there are unsupported statements, we include additional information that is retrieved from reliable sources using those statements, otherwise, we include more unseen passages that are retrieved using the query to acquire more complete information.
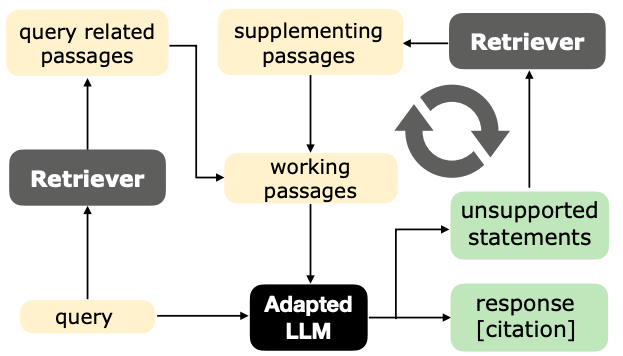
Illustration of the test-time adaptation (TTA) mechanism. The adapted LLM retrieves from the corpus based on self-generated citation information to refine its response in an iterative way.
Experiments
We conduct comprehensive experiments to demonstrate the effectiveness of AGREE both with and without TTA. We evaluate it across five datasets, including two in-domain datasets (NQ and StrategyQA) that have been used for adapting the base LLM and three out-of-domain datasets (ASQA, QAMPARI and an internal QA dataset, called “Enterprise” below) to test the generalization of our framework. We apply AGREE to adapt two LLMs and compare them against a competitive prompting-based baseline (ICLCite), and a post-hoc citing baseline (PostCite), both from ALCE.
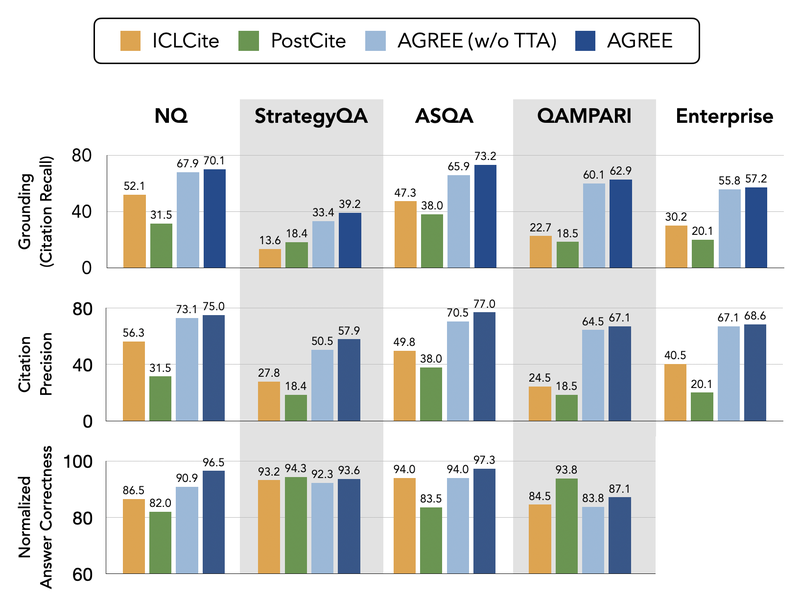
Performance across five datasets of AGREE compared to baselines ICLCite and PostCite. Our approach achieves substantially better grounding and citation precision compared to the baselines.
There are three key takeaways from the figure above, which illustrates the effectiveness of our approach.
- Tuning is effective for superior grounding.
Across five datasets, AGREE generates responses that are better grounded in the text corpus (measured by citation recall) and provides accurate citations to its responses (measured by citation precision). It outperforms each of our selected baselines by a substantial margin. Tuning with high-quality data is a much more effective way for LLMs to learn to ground their responses without needing an additional NLI model. - The improvements can generalize.
AGREE adapts the base LLM only using in-domain training sets (NQ, StrategyQA), and directly tests the model on out-of-domain test datasets (ASQA, QAMPARI, Enterprise). The results suggest that the improvements can effectively generalize to out-of-domain datasets that contain different question types or use different types of external knowledge. This is a fundamental advantage of the proposed approach — AGREE can generalize to a target domain in the zero-shot setting without needing demonstrations from that domain. - TTA improves both grounding and answer correctness.
Comparing our framework at its full capacity and a variant without test-time adaptation, we observe improvements in terms of both better grounding and accuracy. This is because TTA allows the LLMs to actively collect more relevant passages to construct better answers following the self-grounding guidance.
Conclusion
In conclusion, we present AGREE, a framework for improving the factuality and verifiability of LLM-generated content. AGREE presents an effective learning-based approach to adapt a base LLM to self-ground its response using automatically collected data. This integrated capability for grounding further enables the LLM to improve the responses at test time. Our evaluations across five datasets demonstrate the benefits of the holistic adaptation approach compared to approaches that solely rely on prompting or the parametric knowledge of LLMs. We encourage you to read the paper to learn about our findings and join us in building more trustworthy and reliable language models.
Acknowledgements
Thanks to colleagues Yanfei Chen, Tina Pang, Ankur Taly, Lucas Zhang, Jinsung Yoon, Andreas Terzis, for their helpful discussion and suggestions from various aspects of this work.
-
Labels:
- Generative AI
- Machine Intelligence
Quick links
Other posts of interest
-

June 14, 2024
Human I/O: Detecting situational impairments with large language models- Generative AI ·
- Human-Computer Interaction and Visualization ·
- Natural Language Processing
-

June 12, 2024
Smart Paste for context-aware adjustments to pasted code- Machine Intelligence ·
- Natural Language Processing
-

June 11, 2024
Advancing personal health and wellness insights with AI- Generative AI ·
- Health & Bioscience