When I can use JSTOR on my iPhone….
Love how we can always be together! Winner #3 of JSTOR Giftwaway!

When I can use JSTOR on my iPhone….
Love how we can always be together! Winner #3 of JSTOR Giftwaway!
See more posts like this on Tumblr
#JSTOR GIFtawayThis is how I feel about the JSTOR GIFtaway - I want to seriously thank everyone who entered. I’m constantly reminded of how awesome and funny and smart everyone in this community is and I want to hug all of you in a non-creepy way.
Winners of the random drawing by my coworker are:
Congrats you guys! I’ll be reblogging their awesome GIFs later today, along with some others that I found particularly funny. Thanks to everyone who participated and don’t worry if you didn’t win - we’ll definitely do this again!
I wanted to use this one in conjunction with the “I understood that reference” gif for yesterday’s jstor GIFtaway post, but I couldn’t find one that was full sized. So today I made one. For all of you to enjoy, and also on the off chance that duplicate entries will be counted in the giveaway.
I want the nerd cred that comes with having a JSTOR poster hanging in my cube at work goddammit. :D
ANNNNNND weirdly APPROPRIATE. Last of the JSTOR GIFtaway winners!
JSTOR TUMBLR GIFtaway!
Dearest tumblr friends,
Because we have such a wonderful and weird time with you here in tumblr-land, we are doing a limited time GIFtaway.
Should you win (lucky duck), you will receive a:
AND, because you are all Falcon-Bucky-Steve shippers:
We’re giving away 5 of these tote bags full of stuff and all you have to do to enter is post a gif that you think best captures your feelings about JSTOR (or research in general) and tag it “JSTOR GIFtaway"
Deadline is Friday, November 21, and I’ll tag and post the winners here! Official rules here.
Hi Everyone! We’ve posted the official rules here. Please let me know if you have any questions and keep ‘em coming. Y’all are hilarious.
ONLY 24 HOURS LEFT!!!
JSTOR TUMBLR GIFtaway!
Dearest tumblr friends,
Because we have such a wonderful and weird time with you here in tumblr-land, we are doing a limited time GIFtaway.
Should you win (lucky duck), you will receive a:
AND, because you are all Falcon-Bucky-Steve shippers:
We’re giving away 5 of these tote bags full of stuff and all you have to do to enter is post a gif that you think best captures your feelings about JSTOR (or research in general) and tag it “JSTOR GIFtaway"
Deadline is Friday, November 21, and I’ll tag and post the winners here!
JSTOR TUMBLR GIFtaway!
Dearest tumblr friends,
Because we have such a wonderful and weird time with you here in tumblr-land, we are doing a limited time GIFtaway.
Should you win (lucky duck), you will receive a:
AND, because you are all Falcon-Bucky-Steve shippers:
We’re giving away 5 of these tote bags full of stuff and all you have to do to enter is post a gif that you think best captures your feelings about JSTOR (or research in general) and tag it “JSTOR GIFtaway"
Deadline is Friday, November 21, 4:00 pm EST and I’ll tag and post the winners here!
An update!
Happy GIFday!
JSTOR TUMBLR GIFtaway!
Dearest tumblr friends,
Because we have such a wonderful and weird time with you here in tumblr-land, we are doing a limited time GIFtaway.
Should you win (lucky duck), you will receive a:
AND, because you are all Falcon-Bucky-Steve shippers:
We’re giving away 5 of these tote bags full of stuff and all you have to do to enter is post a gif that you think best captures your feelings about JSTOR (or research in general) and tag it “JSTOR GIFtaway"
Deadline is Friday, November 21, and I’ll tag and post the winners here! Official rules here.
This is what my brain does when I visit JSTOR: “I know you have a lot of work to do, you have an essay due on thursday, a midterm on tuesday and god knows what on Wednesday. you can just read one paper, that’s it, no more….wait what you are doing reading an article on specialized pollination on spider hunting wasps. you don’t even like wasps, waaait what come back here stopppppp”
I jump into a puddle and find myself deeper than I’ve thought possible.
(for the jstor giftaway)
Yup. Winner of JSTOR GIFtaway!
disasterhimbo asked:
I saw something about generative AI on JSTOR. Can you confirm whether you really are implementing it and explain why? I’m pretty sure most of your userbase hates AI.

jstor answered:
A generative AI/machine learning research tool on JSTOR is currently in beta, meaning that it’s not fully integrated into the platform. This is an opportunity to determine how this technology may be helpful in parsing through dense academic texts to make them more accessible and gauge their relevancy.
To JSTOR, this is primarily a learning experience. We’re looking at how beta users are engaging with the tool and the results that the tool is producing to get a sense of its place in academia.
In order to understand what we’re doing a bit more, it may help to take a look at what the tool actually does. From a recent blog post:
Problem: Traditionally, researchers rely on metadata, abstracts, and the first few pages of an article to evaluate its relevance to their work. In humanities and social sciences scholarship, which makes up the majority of JSTOR’s content, many items lack abstracts, meaning scholars in these areas (who in turn are our core cohort of users) have one less option for efficient evaluation.
When using a traditional keyword search in a scholarly database, a query might return thousands of articles that a user needs significant time and considerable skill to wade through, simply to ascertain which might in fact be relevant to what they’re looking for, before beginning their search in earnest.
Solution: We’ve introduced two capabilities to help make evaluation more efficient, with the aim of opening the researcher’s time for deeper reading and analysis:

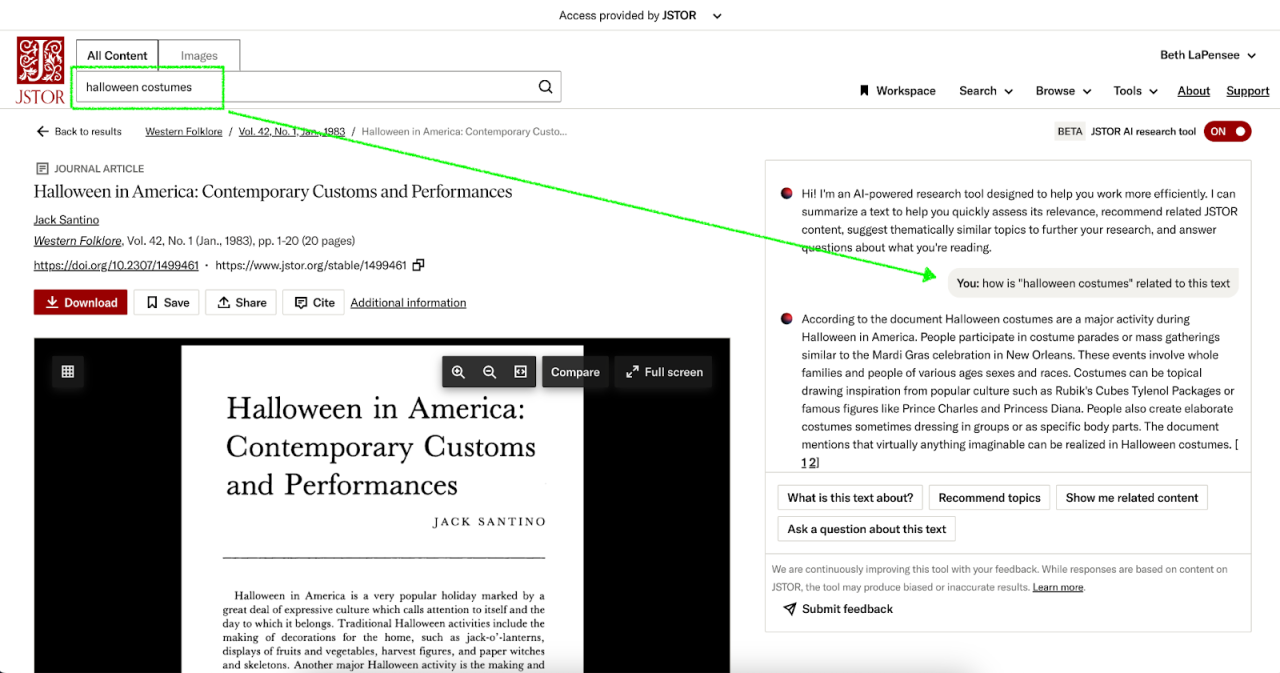
Problem: Once a researcher has discovered content of value to their work, it’s not always easy to know where to go from there. While JSTOR provides some resources, including a “Cited by” list as well as related texts and images, these pathways are limited in scope and not available for all texts. Especially for novice researchers, or those just getting started on a new project or exploring a novel area of literature, it can be needlessly difficult and frustrating to gain traction.
Solution: Two capabilities make further exploration less cumbersome, paving a smoother path for researchers to follow a line of inquiry:


Problem: You think you have found something that could be helpful for your work. It’s time to settle in and read the full document… working through the details, making sure they make sense, figuring out how they fit into your thesis, etc. This all takes time and can be tedious, especially when working through many items.
Solution: To help ensure that users find high quality items, the tool incorporates a conversational element that allows users to query specific points of interest. This functionality, reminiscent of CTRL+F but for concepts, offers a quicker alternative to reading through lengthy documents.
By asking questions that can be answered by the text, users receive responses only if the information is present. The conversational interface adds an accessibility layer as well, making the tool more user-friendly and tailored to the diverse needs of the JSTOR user community.
We knew that, for an AI-powered tool to truly address user problems, it would need to be held to extremely high standards of credibility and transparency. On the credibility side, JSTOR’s AI tool uses only the content of the item being viewed to generate answers to questions, effectively reducing hallucinations and misinformation.
On the transparency front, responses include inline references that highlight the specific snippet of text used, along with a link to the source page. This makes it clear to the user where the response came from (and that it is a credible source) and also helps them find the most relevant parts of the text.
This doesn't address the problem of authors not consenting to using their content this way OR the huge environmental cost, which is inexcusable
What rhube said.
Also:
"JSTOR’s AI tool uses only the content of the item being viewed to generate answers to questions"
If it's a Large Language Model, then doesn't it have to be trained on a large database of language?
While it might only be taking text from the piece being summarised, would it not still have to be trained on a larger set of resources?
If so, has JSTOR ensured that the training set is comprised of material from creators who have given informed consent to their work being used for this purpose?
And to repeat, even if both the database and the assessed pieces were completely ethical in terms of their copyright and procurement, I understand the environmental cost of AI as a whole is at ecosystem destroying levels, so maybe don't contribute to that?
We don’t allow others to train large language models or other generative AI technologies with content on JSTOR unless it’s a case explicitly permitted by our terms of use.
We don’t allow use of the content for commercial gain or allow others to make content available in a way that would substitute for access to JSTOR or the original publisher.
 ALT
ALTEgyptian cat amulet for your viewing pleasure :3
Image: Cat Amulet. 664–525 B.C. Faience, blue, H. 1.8 × W. 0.7 × D. 1.2 cm (11/16 × ¼ × ½ in.). Cat Amulet [08.202.41c]. The Metropolitan Museum of Art.
