
La dashboard di Google Cloud Service Health (CSH) fornisce informazioni sullo stato dei prodotti Google Cloud organizzati per regione e impostazioni internazionali globali.
Incidente grave
Google Cloud definisce un incidente come grave se soddisfa tutte le seguenti condizioni:
- Ambito elevato - L'incidente ha un impatto globale o sta interessando una percentuale significativa di progetti dei clienti in una o più regioni.
- Gravità elevata: uno o più prodotti non sono disponibili o sono gravemente ridotti.
Nei rari casi in cui si verifica un incidente grave, agiamo con urgenza per risolvere eventuali problemi.
Durante un incidente grave, lo stato del problema viene comunicato tramite la dashboard di Google Cloud Service Health. Un incidente grave è contrassegnato come Interruzione del servizio sulle dashboard dello stato. Una volta risolto il problema, pubblichiamo un rapporto pubblico sull'incidente che include i dettagli dei fattori che hanno contribuito all'incidente e le misure che prevediamo di adottare per evitare che si ripetano.
Nel caso di incidenti con ambito minore, potrebbe essere reso disponibile ai clienti un report non pubblico.
Ciclo di vita di un incidente
Quando viene rilevato un degrado di un prodotto, il team di assistenza di Google Cloud e il team tecnico del prodotto collaborano per risolvere l'incidente e fornirti gli aggiornamenti.
Il seguente diagramma mostra le responsabilità dei team di progettazione e assistenza del prodotto:

Nelle sezioni seguenti puoi trovare ulteriori informazioni su ciascuna di queste responsabilità.
Rilevamento
Google Cloud utilizza il monitoraggio interno e black box per rilevare gli incidenti. Per ulteriori informazioni, consulta il Capitolo 6 del libro Site Reliability Engineering.
Se utilizzi l'Assistenza Premium, Avanzata o Standard, puoi segnalare un incidente creando una richiesta di assistenza nella console Google Cloud. In caso contrario, puoi utilizzare questo modulo.
Risposta iniziale
Quando viene rilevato un incidente, il team dell'assistenza clienti Google Cloud gestisce le comunicazioni con i clienti. La notifica iniziale di un incidente è spesso scarsa e spesso fa solo riferimento al prodotto in questione. Questo perché diamo la priorità alle notifiche rapide I dettagli possono essere forniti negli aggiornamenti successivi.
Per fornirti quante più informazioni possibili senza sovraccaricarti di problemi che non ti riguardano, vengono utilizzati canali di comunicazione diversi a seconda dell'ambito e della gravità di un problema:
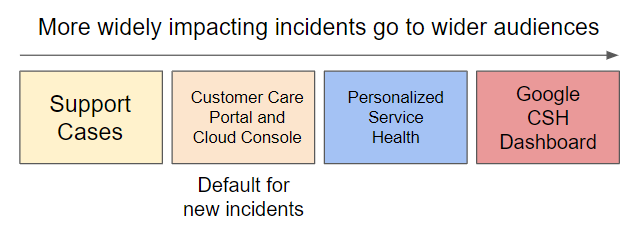
Ti consigliamo di utilizzare Service Health personalizzato come prima tappa in caso di interruzione del servizio. Tramite Service Health personalizzato puoi visualizzare le interruzioni relative ai tuoi progetti in base ai tuoi progetti e ai prodotti Google Cloud che utilizzi. Scopri di più su Service Health personalizzato e su come integrarlo nel flusso di lavoro della gestione degli incidenti.
La dashboard di Google Cloud Service Health mostra gli incidenti gravi ed è progettata per essere disponibile nel raro evento in cui Personalized Service Health non è disponibile o è interessata da un'interruzione.
Se non hai abilitato o integrato Personalized Service Health, ti consigliamo di verificare la presenza di interruzioni attive nella pagina di assistenza della console Google Cloud o nel portale di assistenza clienti. I problemi noti visualizzati nella pagina di assistenza della console Google Cloud e nel portale di assistenza clienti Google Cloud includono anche incidenti di minore entità con ambito limitato.
Le richieste di assistenza sono appropriate per problemi che non possono essere considerati incidenti o in cui è necessario un intervento diretto da parte di persone fisiche. La pagina dei problemi noti ti consente di creare una richiesta a partire da un incidente pubblicato, in modo da ricevere aggiornamenti regolari e parlare con il personale di assistenza.
Indaga
I team di tecnici del prodotto sono responsabili dell'analisi della causa principale degli incidenti. La gestione degli incidenti viene spesso eseguita da Site Reliability Engineers, ma può essere eseguita da ingegneri informatici o altri, a seconda della situazione e del prodotto. Per ulteriori informazioni, consulta il Capitolo 12 del Site Reliability Engineering Book.
Mitigazione/Correzione
Un problema viene considerato risolto solo quando sono state apportate modifiche e che Google ha la certezza che l'impatto sia terminato a tempo indeterminato. Ad esempio, la correzione potrebbe essere il rollback di una modifica che ha attivato un incidente.
Mentre è in corso un incidente, l'assistenza clienti e il team di prodotto tentano di attenuare il problema. La mitigazione avviene quando l'impatto o l'ambito di un problema può essere ridotto, ad esempio fornendo temporaneamente risorse aggiuntive a un prodotto sottoposto a sovraccarico.
Se non sono state trovate attenuazioni, quando possibile, il team dell'assistenza clienti trova e comunica le soluzioni. Le soluzioni alternative sono i passaggi che puoi seguire per risolvere l'esigenza di fondo nonostante l'incidente. Una soluzione alternativa potrebbe essere utilizzare impostazioni diverse per una chiamata API al fine di evitare un percorso del codice problematico.
Invia un follow-up
Mentre è in corso un incidente, il team dell'assistenza clienti fornisce aggiornamenti regolari. In genere gli aggiornamenti offrono:
Maggiori informazioni sull'incidente, ad esempio messaggi di errore, zone o regioni interessate, funzionalità interessate o percentuali dell'impatto.
Progressi verso la mitigazione, incluse eventuali soluzioni alternative.
Sequenza temporale della comunicazione personalizzata in base all'incidente.
Modifiche di stato, ad esempio quando un incidente è stato risolto.
Postmortem
Tutti gli incidenti hanno un post mortem internamente per comprenderli appieno e identificare i miglioramenti dell'affidabilità che Google può apportare. Questi miglioramenti vengono quindi monitorati e implementati. Per ulteriori informazioni sui post morteem di Google, consulta il Capitolo 15 del Site Reliability Engineering Book.
Report sugli incidenti
Quando gli incidenti hanno un impatto molto ampio e grave, Google fornisce report sugli incidenti che ne descrivono i sintomi, l'impatto, la causa principale, gli interventi correttivi e la prevenzione degli incidenti in futuro. Come per i post mortem, prestiamo particolare attenzione ai passaggi che compiamo per imparare dal problema e migliorare l'affidabilità. L'obiettivo di Google nella scrittura e nel rilascio dei post mortem è garantire la trasparenza e dimostrare il proprio impegno nella creazione di prodotti stabili per i clienti.
Modello dei dati sugli incidenti
Un incidente ha impatto su uno o più prodotti in una o più località. Gli incidenti hanno un'ora di inizio e un'ora di fine, oltre a una gravità complessiva. Un incidente include aggiornamenti che descrivono come cambia nel tempo, inclusi lo stato e le località interessate. Le informazioni sugli incidenti vengono rese disponibili tramite uno schema JSON.
Lo schema JSON contiene campi contrassegnati come Stabile e Instabile. In generale, i campi ID vengono considerati stabili, mentre i campi come i nomi visualizzati vengono considerati instabili e possono essere modificati senza avviso. Utilizza i campi stabili solo in caso di integrazione con un sistema esterno o l'automazione degli edifici. Vedi Posso creare integrazioni per utilizzare in modo programmatico i dati visualizzati nella dashboard di Service Health di Google Cloud?.
Domande frequenti
Che tipo di informazioni sullo stato posso trovare nella Dashboard di Google CSH?
La dashboard di Google CSH fornisce informazioni sullo stato dei prodotti che fanno parte di Google Cloud. Lo stato può includere interruzioni del prodotto o interruzioni del servizio o messaggi informativi su un problema temporaneo.
Quando un incidente viene pubblicato nella dashboard di Google CSH?
Gli incidenti che soddisfano uno qualsiasi dei seguenti criteri vengono visualizzati nella dashboard CSH:
- Incidenti gravi
- La dashboard personalizzata di Service Health non è disponibile.
- Prodotti Google Cloud non ancora disponibili su Personalized Service Health.
Dove posso trovare informazioni su interruzioni e interruzioni di prodotti precedenti?
La dashboard di Google CSH conserva un registro delle interruzioni e delle interruzioni dei prodotti Google Cloud per un massimo di cinque anni. La scheda Panoramica della dashboard mostra lo stato corrente dei prodotti in base alle impostazioni internazionali. Per visualizzare informazioni su interruzioni e interruzioni dei prodotti nell'ultimo anno, fai clic su Visualizza cronologia nella dashboard. Per visualizzare la cronologia delle interruzioni di un prodotto negli ultimi cinque anni, fai clic su Scopri di più per quel prodotto.
Come faccio a visualizzare informazioni sullo stato regionalizzate per i prodotti Google Cloud?
La dashboard di Google CSH mostra lo stato di tutti i prodotti Google Cloud organizzati per regione e impostazioni internazionali globali. Per visualizzare lo stato di più regioni, fai clic sulla scheda specifica per la regione.
Posso creare integrazioni per utilizzare in modo programmatico i dati visualizzati nella dashboard di Google Cloud Service Health?
Sì, puoi utilizzare i dati visualizzati nella dashboard di Google CSH nei seguenti modi:
- Tramite un feed RSS
Tramite un file di cronologia JSON
Puoi scaricare lo schema per il file JSON qui.
Il feed RSS e il file di cronologia JSON forniscono informazioni sullo stato di incidente che possono essere consultate tramite le integrazioni.
Utilizza i campi contrassegnati come Stabile nel file di cronologia JSON anziché i campi contrassegnati come Instabile. Esempio: se stai cercando di identificare in modo programmatico gli incidenti che interessano un determinato insieme di prodotti, utilizza gli ID prodotto (affected_products>id), non i nomi visualizzati.
Confronto tra ID prodotto e nomi di prodotti
Storicamente, la dashboard di integrità dei servizi Google Cloud non forniva un meccanismo per individuare l'ID di un determinato prodotto. Dall'inizio del 2023, la dashboard di Google Cloud Service Health ha messo a disposizione un catalogo dei prodotti che fornisce questa mappatura per tutti i prodotti. Un ID prodotto fornisce un campo stabile che può essere disattivato, consentendo la modifica del nome visualizzato di un prodotto. Preferisco fare riferimento all'ID prodotto quando identifichi in modo programmatico gli incidenti che interessano un insieme di prodotti.
Che cosa succede se ho integrazioni predefinite basate sulla dashboard dello stato di Google Cloud prima dell'introduzione dei report sullo stato regionalizzati e della modifica del nome in Google Cloud Service Health Dashboard?
Sia nel feed RSS che nel file JSON, le informazioni sullo stato a livello di regione sono aggiuntive alle informazioni già pubblicate prima dell'introduzione dei report sullo stato regionalizzati e della modifica del nome della dashboard dello stato di Google Cloud. Pertanto, prevediamo che le integrazioni esistenti continuino a funzionare. Tuttavia, se vuoi utilizzare le informazioni sullo stato a livello di regione tramite le integrazioni, devi modificarle.
Ecco una descrizione dettagliata di come vengono presentate le informazioni regionali nel feed RSS e nel file JSON:
Feed RSS
Le informazioni sullo stato regionale sono una nuova aggiunta alle informazioni dei feed fornite prima dell'introduzione dello stato regionalizzato. Tutte le località segnalate come interessate vengono aggiunte al messaggio RSS.
File JSON
Prima dell'aggiornamento dello stato a livello di regione, Google Cloud ha pubblicato un flusso di incidenti in cui ogni incidente conteneva un elenco di prodotti interessati e un elenco di aggiornamenti dello stato per ciascuno, se presente. Questi aggiornamenti dello stato contenevano un campo stringa non strutturato che conteneva o non conteneva le informazioni sulla località.
Ora Google Cloud pubblica un flusso di incidenti come prima. Tuttavia, per ogni incidente, ogni aggiornamento dello stato contiene i seguenti nuovi campi:
updates.affected_locations: contiene un elenco strutturato delle località interessate al momento della pubblicazione dell'aggiornamento. Ogni record di aggiornamento e il recordmost_recent_updatecontengono questo campo.currently_affected_locations: contiene le informazioni più recenti sulle località interessate attivamente dall'incidente. A differenza diupdates.affected_locations, questo elenco diventa vuoto dopo la risoluzione dell'incidente (ovvero quandoendè impostato su un valore non vuoto).previously_affected_locations: contiene un elenco delle località precedentemente interessate da un incidente, ma che non sono state interessate. Con l'avanzare dell'incidente, alcune località potrebbero avere una risoluzione dell'interruzione. Queste località continueranno a esistere inpreviously_affected_locations field. Una volta risolto l'incidente (ovvero, quandoendè impostato su un valore non vuoto), questo campo contiene un elenco di tutte le località interessate durante l'incidente.
Che cosa succede se ho riscontrato un problema che però non è elencato nella dashboard?
La dashboard di Google Cloud Service Health fornisce informazioni attuali e cronologiche sullo stato di qualsiasi incidente grave che interessa i prodotti e i servizi Google Cloud. Se riscontri un problema che non è elencato nella dashboard, potrebbe essere isolato ai tuoi progetti o alle tue istanze oppure potrebbe interessare un numero limitato di clienti. Gli incidenti di ambito più ristretto potrebbero essere elencati sul portale di assistenza clienti. Puoi contattare l'assistenza clienti in caso di problemi non elencati nella dashboard.
Se stai già utilizzando la dashboard Personalized Service Health, controlla se il problema è presente nell'elenco per stabilire se il progetto o l'istanza sono interessati.
Se utilizzi la console Google Cloud, puoi fare clic sullo strumento Invia feedback nell'angolo in alto a destra per segnalare problemi.
Chi aggiorna la dashboard?
Il team globale dell'assistenza clienti monitora lo stato dei prodotti utilizzando molti tipi diversi di indicatori e aggiorna la dashboard in caso di problemi diffusi. Se necessario, pubblicheranno un report dettagliato di analisi degli incidenti una volta risolto l'incidente.