

Puoi monitorare e risolvere i problemi di Dataproc Serverless per i carichi di lavoro batch di Spark utilizzando le informazioni e gli strumenti illustrati nelle sezioni seguenti.
Server di cronologia permanente
Dataproc Serverless per Spark crea le risorse di calcolo necessarie per eseguire un carico di lavoro, ne esegue il carico su queste risorse e poi elimina le risorse al termine del carico di lavoro. Le metriche e gli eventi del carico di lavoro non vengono mantenuti dopo il completamento del carico di lavoro. Tuttavia, puoi utilizzare un server di cronologia permanente (PHS) per conservare la cronologia delle applicazioni dei carichi di lavoro (log degli eventi) in Cloud Storage.
Per utilizzare un PHS con un carico di lavoro batch:
Specifica il PHS quando invii un carico di lavoro.
Utilizza il gateway dei componenti per connetterti al PHS e visualizzare i dettagli dell'applicazione, le fasi dello scheduler, i dettagli a livello di attività e le informazioni su ambiente ed esecutore.
Dataproc Serverless per log di Spark
Il logging è abilitato per impostazione predefinita in Dataproc Serverless per Spark e i log dei carichi di lavoro vengono mantenuti al termine di un carico di lavoro. Dataproc Serverless per Spark raccoglie i log dei carichi di lavoro in Cloud Logging.
Puoi accedere ai log dei carichi di lavoro spark, agent, output e container nella risorsa Cloud Dataproc Batch in Esplora log.
Esempio di Dataproc Serverless per Spark in modalità batch:

Per ulteriori informazioni, consulta Log di Dataproc.
Metriche del carico di lavoro
Per impostazione predefinita, Dataproc Serverless per Spark consente la raccolta delle metriche Spark disponibili, a meno che non utilizzi le proprietà di raccolta delle metriche Spark per disattivare o sostituire la raccolta di una o più metriche Spark.
Puoi visualizzare le metriche dei carichi di lavoro dalla pagina Metrics Explorer o dalla pagina Dettagli batch nella console Google Cloud.
Metriche batch
Le metriche delle risorse batch di Dataproc forniscono insight sulle risorse batch, ad esempio il numero di esecutori batch. Le metriche batch sono precedute dal prefisso dataproc.googleapis.com/batch.

Metriche Spark
Le metriche Spark disponibili includono le metriche del driver e degli esecutori Spark e le metriche di sistema. Le metriche Spark disponibili hanno il prefisso custom.googleapis.com/.
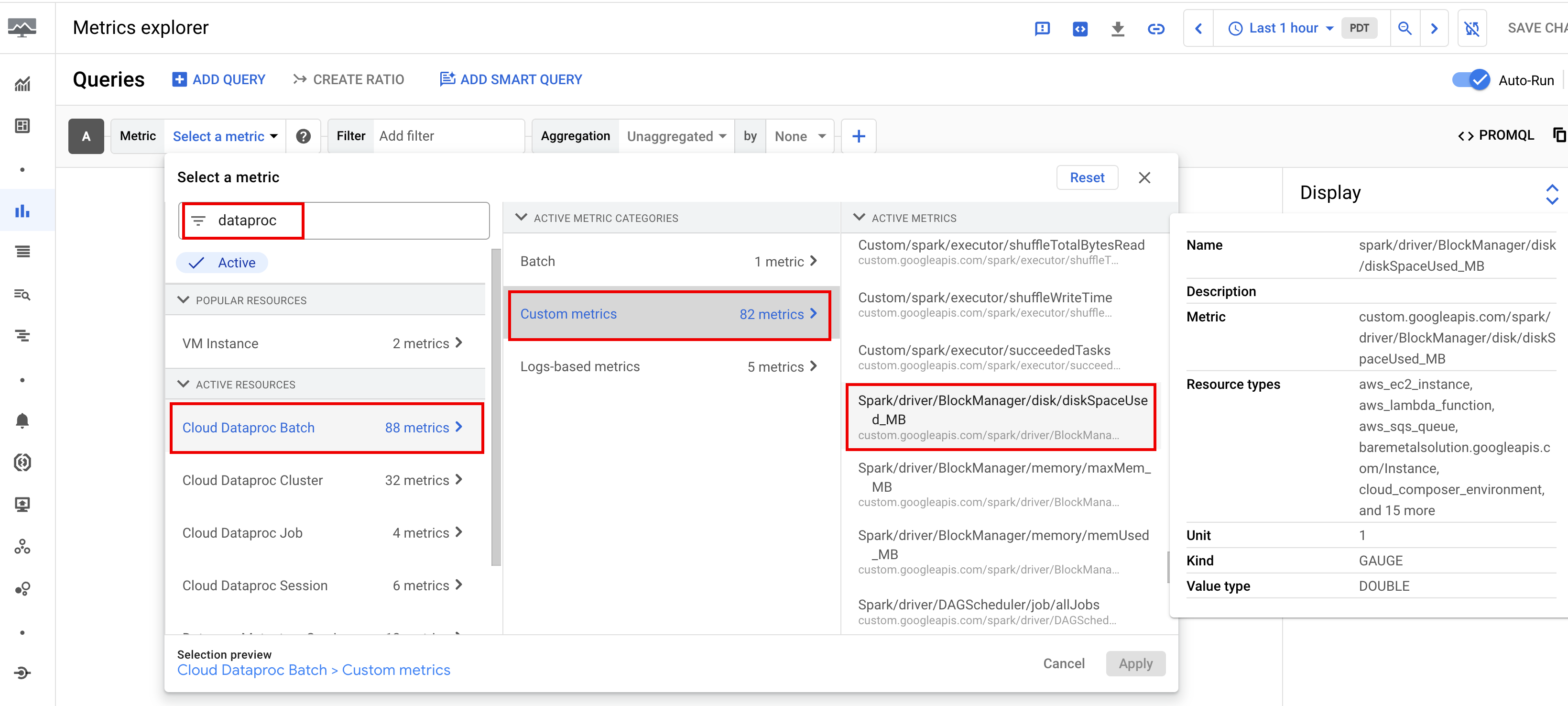
Configura gli avvisi per le metriche
Puoi creare avvisi per le metriche Dataproc per ricevere notifiche sui problemi dei carichi di lavoro.
Creare grafici
Puoi creare grafici che visualizzano le metriche dei carichi di lavoro utilizzando Metrics Explorer nella console Google Cloud. Ad esempio, puoi creare un grafico per visualizzare disk:bytes_used e poi filtrare per batch_id.
Cloud Monitoring
Monitoring usa i metadati e le metriche dei carichi di lavoro per fornire insight su integrità e prestazioni di Dataproc Serverless. Le metriche dei carichi di lavoro includono metriche Spark, metriche batch e metriche operative.
Puoi utilizzare Cloud Monitoring nella console Google Cloud per esplorare metriche, aggiungere grafici, creare dashboard e creare avvisi.
Creare dashboard
Puoi creare una dashboard per monitorare i carichi di lavoro utilizzando metriche di più progetti e diversi prodotti Google Cloud. Per maggiori informazioni, consulta Creare e gestire dashboard personalizzate.
Risoluzione dei problemi avanzata (anteprima)
Questa sezione illustra le funzionalità avanzate di anteprima di risoluzione dei problemi disponibili nella console Google Cloud, tra cui la risoluzione dei problemi per Dataproc Serverless assistita da Gemini, che fa parte dell'offerta Gemini in BigQuery.
Accesso alle funzionalità in anteprima
Per registrarti per la release di anteprima delle funzionalità avanzate per la risoluzione dei problemi, compila e invia il modulo Gemini in BigQuery Preview. Una volta approvato il modulo, i progetti elencati nel modulo avranno accesso alle funzionalità in anteprima.
Anteprima dei prezzi
Non sono previsti costi aggiuntivi per la partecipazione all'anteprima. Gli addebiti verranno applicati alle seguenti funzionalità in anteprima non appena diventeranno disponibili pubblicamente:
- Risoluzione dei problemi assistita da Gemini per Dataproc Serverless
- Caratteristiche principali delle metriche batch
- Log del job
Un preavviso sugli addebiti di GA verrà inviato all'indirizzo email fornito nel modulo di registrazione di anteprima.
Requisiti delle funzionalità
Registrazione: devi registrarti per la funzionalità.
Autorizzazione:devi avere l'autorizzazione
dataproc.batches.analyze.Se hai il ruolo predefinito
roles/dataproc.admin,roles/dataproc.editororoles/dataproc.viewer, hai l'autorizzazione richiesta. Non sono necessari ulteriori interventi.Se utilizzi un ruolo personalizzato per accedere ai servizi Dataproc, il ruolo personalizzato deve disporre dell'autorizzazione
dataproc.batches.analyze. Puoi utilizzare l'interfaccia alla gcloud CLI per aggiungere l'autorizzazione, come mostrato nel comando seguente, che aggiunge l'autorizzazione a livello di progetto:
gcloud iam roles update CUSTOM_ROLE_ID --project=PROJECT_ID \ --add-permissions="dataproc.batches.analyze"
Abilita la risoluzione dei problemi assistita da Gemini per Dataproc Serverless: attivi la risoluzione dei problemi assistita da Gemini per Dataproc Serverless quando invii ogni carico di lavoro batch ricorrente di Spark utilizzando la console Google Cloud, gcloud CLI o l'API Dataproc. Dopo aver abilitato questa funzionalità su un carico di lavoro batch ricorrente, Dataproc archivia una copia dei log del carico di lavoro per 30 giorni e utilizza i dati di log salvati per fornire la risoluzione dei problemi del carico di lavoro assistita da Gemini. Per informazioni sui contenuti dei log dei carichi di lavoro Spark, consulta Log Serverless per Spark.
Console
Esegui i passaggi seguenti per abilitare la risoluzione dei problemi assistita da Gemini su ogni carico di lavoro batch Spark ricorrente:
Nella console Google Cloud, vai alla pagina Batch di Dataproc.
Per creare un carico di lavoro batch, fai clic su Crea.
Nella sezione Contenitore, inserisci il nome Coorte, che identifica il batch come uno di una serie di carichi di lavoro ricorrenti. L'analisi basata su Gemini viene applicata al secondo carico di lavoro e a quelli successivi inviati con questo nome coorte. Ad esempio, specifica
TPCH-Query1come nome coorte per un carico di lavoro pianificato che esegue una query TPC-H giornaliera.Compila le altre sezioni della pagina Crea batch come necessario, quindi fai clic su Invia. Per maggiori informazioni, consulta Inviare un carico di lavoro batch.
gcloud
Esegui il seguente comando gcloud CLI
gcloud dataproc batches submit
in locale in una finestra del terminale o in Cloud Shell
per abilitare la risoluzione dei problemi assistita da Gemini su ogni carico di lavoro batch ricorrente di Spark:
gcloud dataproc batches submit COMMAND \
--region=REGION \
--cohort=COHORT \
other arguments ...
Sostituisci quanto segue:
- COMMAND: il tipo di carico di lavoro Spark, come
Spark,PySpark,Spark-SqloSpark-R. - REGION: la regione in cui verrà eseguito il carico di lavoro.
- COHORT: il nome della coorte, che identifica il batch come uno di una serie di carichi di lavoro ricorrenti.
L'analisi assistita da Gemini viene applicata al secondo carico di lavoro e a quelli successivi inviati
con questo nome coorte. Ad esempio, specifica
TPCH Query 1come nome della coorte per un carico di lavoro pianificato che esegue una query TPC-H giornaliera.
API
Includi il nome RuntimeConfig.cohort in una richiesta batches.create per abilitare la risoluzione dei problemi assistita da Gemini su ogni carico di lavoro batch ricorrente. L'analisi basata su Gemini viene applicata al secondo carico di lavoro e a quelli successivi inviati con questo nome coorte. Ad esempio, specifica TPCH-Query1 come nome della coorte
per un carico di lavoro pianificato che esegue una query
TPC-H giornaliera.
Esempio:
...
runtimeConfig:
cohort: TPCH-Query1
...
Risoluzione dei problemi assistita da Gemini per Dataproc Serverless
Le seguenti funzionalità di anteprima per la risoluzione dei problemi assistiti da Gemini sono disponibili nelle pagine di elenco Dettagli batch e Batch nella console Google Cloud.
Scheda Indaga: la scheda Esamina nella pagina Dettagli batch fornisce una sezione Panoramica dell'integrità (anteprima) con i seguenti riquadri per la risoluzione dei problemi assistiti da Gemini:
- Cosa è stato ottimizzato automaticamente? Se hai attivato l'ottimizzazione automatica su uno o più carichi di lavoro, questo riquadro mostra le modifiche più recenti dell'ottimizzazione automatica applicate ai carichi di lavoro in esecuzione, completati e non riusciti.

- Che cosa sta succedendo ora? e Che cosa posso fare? Fai clic su Chiedi a Gemini per richiedere consigli per correggere i carichi di lavoro non riusciti o migliorare i carichi di lavoro riusciti ma lenti.
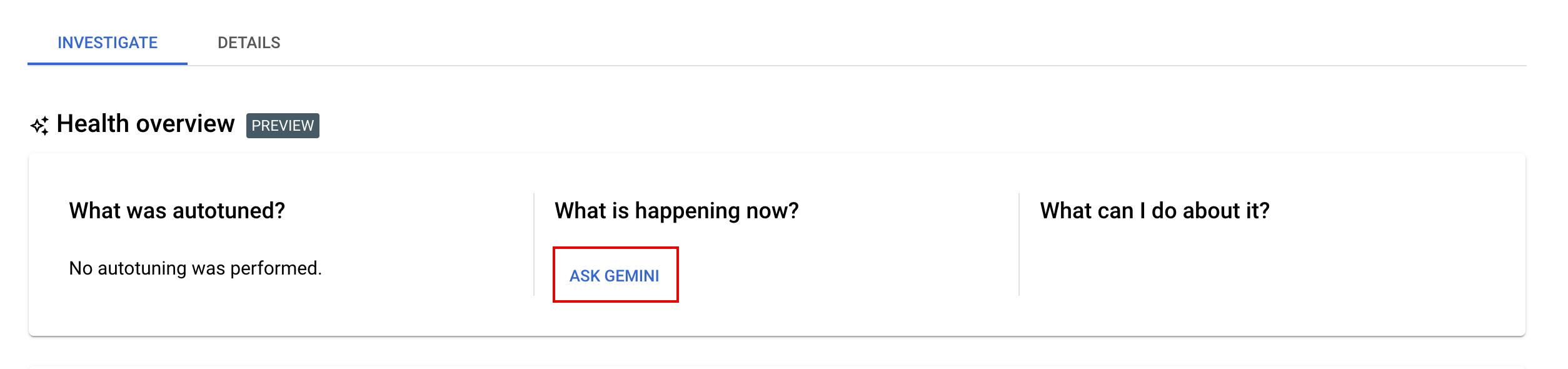
Se fai clic su Chiedi a Gemini, Gemini genera un riepilogo di eventuali errori, anomalie o evidenziazioni dai log dei carichi di lavoro, dalle metriche Spark e dagli eventi Spark. Gemini può anche visualizzare un elenco di passaggi consigliati che puoi seguire per correggere un carico di lavoro non riuscito o migliorare le prestazioni di un carico di lavoro riuscito ma lento.

Colonne per la risoluzione dei problemi assistite da Gemini: nell'ambito della release di anteprima, la pagina dell'elenco dei Batch di Dataproc nella console Google Cloud include le colonne
What was Autotuned,What is happening now?eWhat can I do about it?.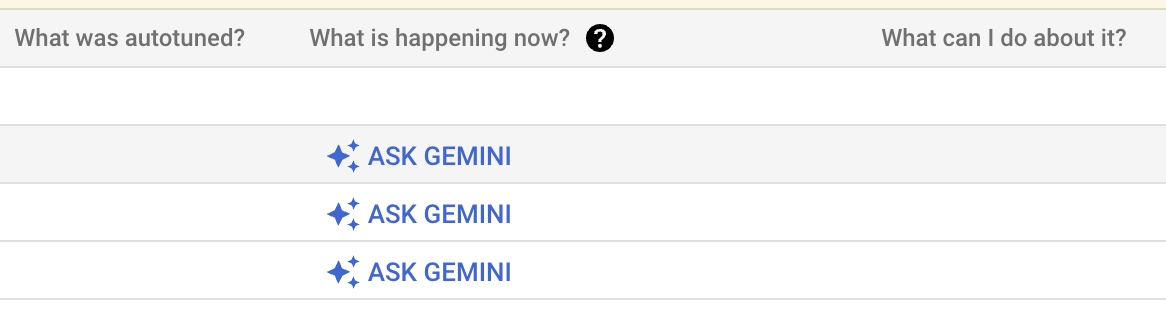
Il pulsante Chiedi a Gemini viene visualizzato e abilitato solo se un batch completato è in stato
Failed,CancelledoSucceeded. Se fai clic su Chiedi a Gemini, Gemini genera un riepilogo di eventuali errori, anomalie o evidenziazioni dai log dei carichi di lavoro, dalle metriche Spark e dagli eventi Spark. Gemini può anche visualizzare un elenco di passaggi consigliati che puoi seguire per correggere un carico di lavoro non riuscito o migliorare le prestazioni di un carico di lavoro riuscito ma lento.
Evidenziazioni delle metriche batch
Come parte della versione di anteprima, la pagina Dettagli batch nella console Google Cloud include grafici che mostrano valori importanti delle metriche dei carichi di lavoro batch. I grafici delle metriche vengono completati con i valori al termine del batch.
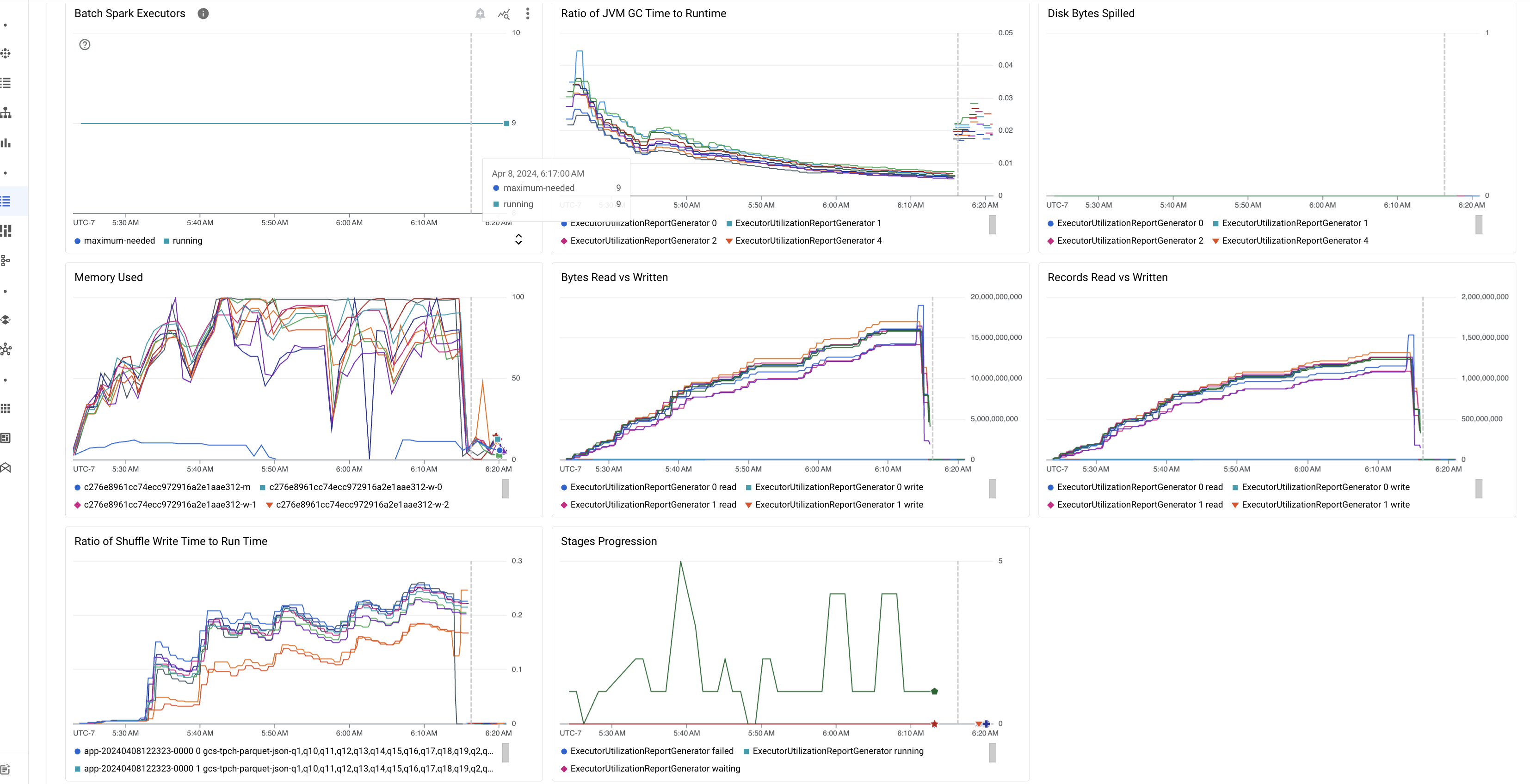
La seguente tabella elenca le metriche del carico di lavoro Spark visualizzate nella pagina Dettagli batch della console Google Cloud e descrive come i valori delle metriche possono fornire insight sullo stato e sulle prestazioni dei carichi di lavoro.
| Metrica | Cosa indica? |
|---|---|
| Metriche a livello di esecutore | |
| Rapporto tra tempo GC e runtime JVM | Questa metrica mostra il rapporto tra il tempo GC (garbage collection) di JVM e il runtime per esecutore. Rapporti elevati possono indicare perdite di memoria all'interno di attività in esecuzione su particolari esecutori o strutture di dati inefficienti, che possono portare a un elevato tasso di abbandono degli oggetti. |
| Byte fuori dal disco | Questa metrica mostra il numero totale di byte del disco distribuiti tra diversi esecutori. Se un esecutore mostra uno sversamento di byte del disco elevati, questo può indicare un disallineamento dei dati. Se la metrica aumenta nel tempo, ciò può indicare la presenza di fasi con pressione o perdita di memoria. |
| Byte letti e scritti | Questa metrica mostra il numero di byte scritti e di byte letti per esecutore. Grandi discrepanze nei byte letti o scritti possono indicare scenari in cui i join replicati portano all'amplificazione dei dati su esecutori specifici. |
| Record letti e scritti | Questa metrica mostra i record letti e scritti per esecutore. La lettura di record a numeri elevati con un numero basso di record scritti può indicare un collo di bottiglia nella logica di elaborazione su esecutori specifici, che comporta la lettura dei record in attesa. Gli esecutori con un ritardo costante nelle letture e nelle scritture possono indicare un conflitto di risorse su quei nodi o inefficienze di codice specifiche degli esecutori. |
| Rapporto tra tempo di scrittura shuffling e tempo di esecuzione | La metrica mostra la quantità di tempo che l'esecutore ha trascorso nel runtime di shuffling rispetto al runtime complessivo. Se questo valore è elevato per alcuni esecutori, potrebbe indicare un disallineamento dei dati o una serializzazione inefficiente dei dati. Puoi identificare le fasi con lunghi tempi di scrittura shuffling nella UI di Spark. Cercare attività outlier all'interno di queste fasi che richiedono più tempo del tempo medio per essere completate. Controlla se gli esecutori con tempi di scrittura shuffling elevati mostrano anche un'attività di I/O su disco elevata. Una serializzazione più efficiente e passaggi di partizionamento aggiuntivi potrebbero essere utili. Le scritture di record molto grandi rispetto alle letture di record possono indicare una duplicazione involontaria dei dati a causa di join inefficienti o trasformazioni errate. |
| Metriche a livello di applicazione | |
| Progressione delle fasi | Questa metrica mostra il numero di fasi nelle fasi non riuscite, in attesa ed in esecuzione. Un numero elevato di fasi non riuscite o di attesa può indicare un disallineamento dei dati. Verifica la presenza di partizioni di dati ed esegui il debug del motivo dell'errore della fase utilizzando la scheda Fasi nell'interfaccia utente di Spark. |
| Esecutori Spark batch | Questa metrica mostra il numero di esecutori che potrebbero essere necessari rispetto al numero di esecutori in esecuzione. Una grande differenza tra gli esecutori obbligatori ed in esecuzione può indicare problemi di scalabilità automatica. |
| Metriche a livello di VM | |
| Memoria utilizzata | Questa metrica mostra la percentuale di memoria VM in uso. Se la percentuale principale è alta, può indicare che il conducente è sotto pressione. Per altri nodi VM, una percentuale elevata può indicare che gli esecutori stanno esaurendo la memoria, il che può portare a un'elevata perdita di disco e a un tempo di esecuzione del carico di lavoro più lento. Utilizza la UI di Spark per analizzare gli esecutori al fine di verificare se ci sono tempi GC elevati e errori nelle attività elevate. Esegui anche il debug del codice Spark per la memorizzazione nella cache di set di dati di grandi dimensioni e la trasmissione non necessaria di variabili. |
Log job
Come parte della release di anteprima, la pagina Dettagli batch nella console Google Cloud elenca i log del job (carico di lavoro batch). I log includono avvisi ed errori filtrati dall'output dei carichi di lavoro e dai log di Spark. Puoi selezionare Gravità dei log, aggiungere un filtro e quindi fare clic sull'icona Visualizza in Esplora log per aprire i log batch selezionati in Esplora log.

Esempio: Esplora log si apre dopo aver scelto Errors dal selettore di gravità nella pagina Dettagli batch nella console Google Cloud.

UI Spark (anteprima)
Se hai registrato il tuo progetto nella funzionalità di anteprima della UI di Spark, puoi visualizzare la UI di Spark nella console Google Cloud senza dover creare un cluster Dataproc PHS (Server di cronologia permanente). La UI di Spark raccoglie i dettagli dell'esecuzione di Spark dai carichi di lavoro batch. Per ulteriori informazioni, consulta la guida dell'utente distribuita ai clienti registrati come parte della release di anteprima dell'interfaccia utente di Spark.