
Effectuer une détection d'anomalies avec un modèle de prévision de séries temporelles multivariées
Pour envoyer des commentaires ou demander de l'aide concernant cette fonctionnalité, envoyez un e-mail à l'adresse [email protected].
Ce tutoriel vous explique comment effectuer les tâches suivantes :
- Créez un modèle de prévision de séries temporelles
ARIMA_PLUS_XREG. - Détecter les anomalies dans les données de séries temporelles en exécutant la fonction
ML.DETECT_ANOMALIESsur le modèle.
Ce tutoriel utilise les tables suivantes de l'ensemble de données public epa_historical_air_quality, qui contient des informations quotidiennes sur la concentration de particules fines PM 2,5, la température et la vitesse du vent, collectées pour plusieurs villes américaines :
epa_historical_air_quality.pm25_nonfrm_daily_summaryepa_historical_air_quality.wind_daily_summaryepa_historical_air_quality.temperature_daily_summary
Autorisations requises
- Pour créer l'ensemble de données, vous devez disposer de l'autorisation IAM
bigquery.datasets.create. Pour créer la ressource de connexion, vous devez disposer des autorisations suivantes :
bigquery.connections.createbigquery.connections.get
Pour créer le modèle, vous avez besoin des autorisations suivantes :
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.connections.delegate
Pour exécuter une inférence, vous devez disposer des autorisations suivantes :
bigquery.models.getDatabigquery.jobs.create
Pour plus d'informations sur les rôles et les autorisations IAM dans BigQuery, consultez la page Présentation d'IAM.
Coûts
Dans ce document, vous utilisez les composants facturables suivants de Google Cloud :
- BigQuery : des frais sont facturés pour les données que vous traitez dans BigQuery.
Obtenez une estimation des coûts en fonction de votre utilisation prévue à l'aide du simulateur de coût.
Pour en savoir plus, consultez la page décrivant les tarifs de BigQuery.
Avant de commencer
- Connectez-vous à votre compte Google Cloud. Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits gratuits pour exécuter, tester et déployer des charges de travail.
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud.
-
Activez l'API BigQuery
-
Dans Google Cloud Console, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
-
Vérifiez que la facturation est activée pour votre projet Google Cloud.
-
Activez l'API BigQuery
Créer un ensemble de données
Vous allez créer un ensemble de données BigQuery pour stocker votre modèle de ML :
Dans la console Google Cloud, accédez à la page "BigQuery".
Dans le volet Explorateur, cliquez sur le nom de votre projet.
Cliquez sur Afficher les actions > Créer un ensemble de données.

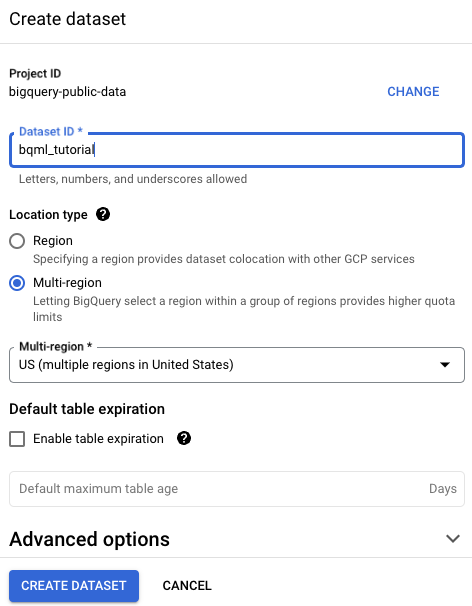
Sur la page Créer un ensemble de données, procédez comme suit :
Dans le champ ID de l'ensemble de données, saisissez
bqml_tutorial.Pour Type d'emplacement, sélectionnez Multirégional, puis sélectionnez US (plusieurs régions aux États-Unis).
Les ensembles de données publics sont stockés dans l'emplacement multirégional
US. Par souci de simplicité, stockez votre ensemble de données dans le même emplacement.Conservez les autres paramètres par défaut, puis cliquez sur Créer un ensemble de données.
Préparer les données d'entraînement
Les données de concentration de particules fines PM2.5, de température et de vitesse du vent sont situées dans des tables distinctes.
Créez la table bqml_tutorial.seattle_air_quality_daily des données d'entraînement en combinant les données de ces tables publiques.
bqml_tutorial.seattle_air_quality_daily contient les colonnes suivantes :
date: date de l'observationPM2.5: concentration moyenne de particules fines PM 2,5 enregistrée chaque jourwind_speed: vitesse moyenne du vent enregistrée chaque jourtemperature: température la plus élevée enregistrée chaque jour
La nouvelle table contient des données quotidiennes enregistrées du 11 août 2009 au 31 janvier 2022.
Accédez à la page BigQuery.
Dans le volet de l'éditeur, exécutez l'instruction SQL suivante :
CREATE TABLE `bqml_tutorial.seattle_air_quality_daily` AS WITH pm25_daily AS ( SELECT avg(arithmetic_mean) AS pm25, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.pm25_nonfrm_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Acceptable PM2.5 AQI & Speciation Mass' GROUP BY date_local ), wind_speed_daily AS ( SELECT avg(arithmetic_mean) AS wind_speed, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.wind_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Wind Speed - Resultant' GROUP BY date_local ), temperature_daily AS ( SELECT avg(first_max_value) AS temperature, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.temperature_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Outdoor Temperature' GROUP BY date_local ) SELECT pm25_daily.date AS date, pm25, wind_speed, temperature FROM pm25_daily JOIN wind_speed_daily USING (date) JOIN temperature_daily USING (date)
Créer le modèle
Créez un modèle de série temporelle multivariée en utilisant les données de bqml_tutorial.seattle_air_quality_daily comme données d'entraînement.
Accédez à la page BigQuery.
Dans le volet de l'éditeur, exécutez l'instruction SQL suivante :
CREATE OR REPLACE MODEL `bqml_tutorial.arimax_model` OPTIONS ( model_type = 'ARIMA_PLUS_XREG', auto_arima=TRUE, time_series_data_col = 'temperature', time_series_timestamp_col = 'date' ) AS SELECT * FROM `bqml_tutorial.seattle_air_quality_daily`;L'exécution de la requête prend plusieurs secondes, après quoi le modèle
arimax_modelapparaît dans l'ensemble de donnéesbqml_tutorialdans le volet Explorateur.Étant donné que la requête utilise une instruction
CREATE MODELpour créer un modèle, il n'y a aucun résultat de requête.
Effectuer une détection d'anomalies sur les données historiques
Lancez la détection d'anomalies sur les données d'historique que vous avez utilisées pour entraîner le modèle.
Accédez à la page BigQuery.
Dans le volet de l'éditeur, exécutez l'instruction SQL suivante :
SELECT * FROM ML.DETECT_ANOMALIES ( MODEL `bqml_tutorial.arimax_model`, STRUCT(0.6 AS anomaly_prob_threshold) ) ORDER BY date ASC;
Les résultats ressemblent à ce qui suit :
+-------------------------+-------------+------------+--------------------+--------------------+---------------------+ | date | temperature | is_anomaly | lower_bound | upper_bound | anomaly_probability | +--------------------------------------------------------------------------------------------------------------------+ | 2009-08-11 00:00:00 UTC | 70.1 | false | 67.65880237416745 | 72.541197625832538 | 0 | +--------------------------------------------------------------------------------------------------------------------+ | 2009-08-12 00:00:00 UTC | 73.4 | false | 71.715603233887791 | 76.597998485552878 | 0.20589853827304627 | +--------------------------------------------------------------------------------------------------------------------+ | 2009-08-13 00:00:00 UTC | 64.6 | true | 67.741606808079425 | 72.624002059744512 | 0.94627126678202522 | +-------------------------+-------------+------------+--------------------+--------------------+---------------------+
Effectuer une détection d'anomalies sur les nouvelles données
Lancez la détection d'anomalies sur les données historiques que vous avez utilisées pour entraîner le modèle.
Accédez à la page BigQuery.
Dans le volet de l'éditeur, exécutez l'instruction SQL suivante :
SELECT * FROM ML.DETECT_ANOMALIES ( MODEL `bqml_tutorial.arimax_model`, STRUCT(0.6 AS anomaly_prob_threshold), ( SELECT * FROM UNNEST( [ STRUCT<date TIMESTAMP, pm25 FLOAT64, wind_speed FLOAT64, temperature FLOAT64> ('2023-02-01 00:00:00 UTC', 8.8166665, 1.6525, 44.0), ('2023-02-02 00:00:00 UTC', 11.8354165, 1.558333, 40.5), ('2023-02-03 00:00:00 UTC', 10.1395835, 1.6895835, 46.5), ('2023-02-04 00:00:00 UTC', 11.439583500000001, 2.0854165, 45.0), ('2023-02-05 00:00:00 UTC', 9.7208335, 1.7083335, 46.0), ('2023-02-06 00:00:00 UTC', 13.3020835, 2.23125, 43.5), ('2023-02-07 00:00:00 UTC', 5.7229165, 2.377083, 47.5), ('2023-02-08 00:00:00 UTC', 7.6291665, 2.24375, 44.5), ('2023-02-09 00:00:00 UTC', 8.5208335, 2.2541665, 40.5), ('2023-02-10 00:00:00 UTC', 9.9086955, 7.333335, 39.5) ] ) ) );Les résultats ressemblent à ce qui suit :
+-------------------------+-------------+------------+--------------------+--------------------+---------------------+------------+------------+ | date | temperature | is_anomaly | lower_bound | upper_bound | anomaly_probability | pm25 | wind_speed | +----------------------------------------------------------------------------------------------------------------------------------------------+ | 2023-02-01 00:00:00 UTC | 44.0 | true | 36.917405956304407 | 41.79980120796948 | 0.890904731626234 | 8.8166665 | 1.6525 | +----------------------------------------------------------------------------------------------------------------------------------------------+ | 2023-02-02 00:00:00 UTC | 40.5 | false | 34.622436643607685 | 40.884690866417984 | 0.53985850962605064 | 11.8354165 | 1.558333 | +--------------------------------------------------------------------------------------------------------------------+-------------------------+ | 2023-02-03 00:00:00 UTC | 46.5 | true | 33.769587937313183 | 40.7478502941026 | 0.97434506593220793 | 10.1395835 | 1.6895835 | +-------------------------+-------------+------------+--------------------+--------------------+---------------------+-------------------------+
Effectuer un nettoyage
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.