
Anomalieerkennung mit einem multivariaten Zeitreihen-Prognosemodell durchführen
Wenn Sie für dieses Feature Feedback geben oder Support anfordern möchten, senden Sie eine E-Mail an [email protected].
In dieser Anleitung werden die folgenden Aufgaben erläutert:
- Erstellen Sie ein
ARIMA_PLUS_XREG-Zeitreihen-Prognosemodell. - Erkennen Sie Anomalien in den Zeitreihendaten, indem Sie die
ML.DETECT_ANOMALIES-Funktion für das Modell ausführen.
In dieser Anleitung werden die folgenden Tabellen aus dem öffentlichen Dataset epa_historical_air_quality verwendet, das tägliche Informationen zu PM-2.5, Temperatur und Windgeschwindigkeiten enthält, die in mehreren Städten in den USA erfasst wurden:
epa_historical_air_quality.pm25_nonfrm_daily_summaryepa_historical_air_quality.wind_daily_summaryepa_historical_air_quality.temperature_daily_summary
Erforderliche Berechtigungen
- Sie benötigen die IAM-Berechtigung
bigquery.datasets.create, um das Dataset zu erstellen. Zum Erstellen der Verbindungsressource benötigen Sie die folgenden Berechtigungen:
bigquery.connections.createbigquery.connections.get
Zum Erstellen des Modells benötigen Sie die folgenden Berechtigungen:
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.connections.delegate
Zum Ausführen von Inferenzen benötigen Sie die folgenden Berechtigungen:
bigquery.models.getDatabigquery.jobs.create
Weitere Informationen zu IAM-Rollen und Berechtigungen in BigQuery finden Sie unter Einführung in IAM.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
- BigQuery: Für die Daten, die Sie in BigQuery verarbeiten, fallen Kosten an.
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Weitere Informationen finden Sie unter BigQuery-Preise.
Hinweise
- Melden Sie sich bei Ihrem Google Cloud-Konto an. Wenn Sie mit Google Cloud noch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
BigQuery API aktivieren.
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
BigQuery API aktivieren.
Dataset erstellen
Erstellen Sie ein BigQuery-Dataset, um Ihr ML-Modell zu speichern:
Rufen Sie in der Google Cloud Console die Seite „BigQuery“ auf.
Klicken Sie im Bereich Explorer auf den Namen Ihres Projekts.
Klicken Sie auf Aktionen ansehen > Dataset erstellen.
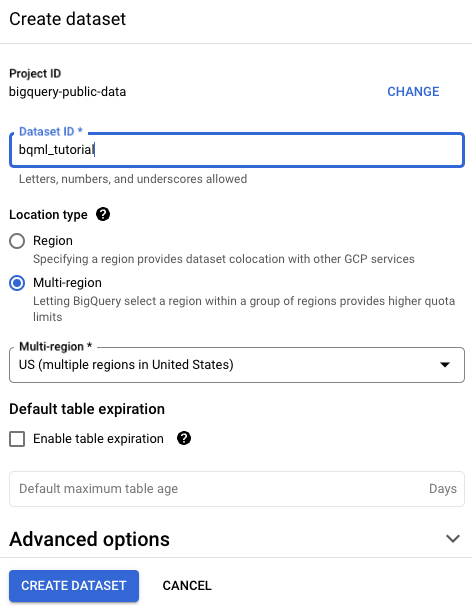
Führen Sie auf der Seite Dataset erstellen die folgenden Schritte aus:
Geben Sie unter Dataset-ID
bqml_tutorialein.Wählen Sie als Standorttyp die Option Mehrere Regionen und dann USA (mehrere Regionen in den USA) aus.
Die öffentlichen Datasets sind am multiregionalen Standort
USgespeichert. Der Einfachheit halber sollten Sie Ihr Dataset am selben Standort speichern.Übernehmen Sie die verbleibenden Standardeinstellungen unverändert und klicken Sie auf Dataset erstellen.
Trainingsdaten vorbereiten
Die Daten zu PM2.5, Temperatur und Windgeschwindigkeit befinden sich in separaten Tabellen.
Erstellen Sie die Tabelle bqml_tutorial.seattle_air_quality_daily mit Trainingsdaten, indem Sie die Daten in diesen öffentlichen Tabellen kombinieren.
bqml_tutorial.seattle_air_quality_daily enthält die folgenden Spalten:
date: das Datum der BeobachtungPM2.5: der durchschnittliche PM2.5-Wert je Tagwind_speed: die durchschnittliche Windgeschwindigkeit je Tagtemperature: Temperatur: die Höchsttemperatur je Tag
Die neue Tabelle enthält Tagesdaten vom 11. August 2009 bis zum 31. Januar 2022.
Rufen Sie die Seite BigQuery auf.
Führen Sie im SQL-Editorbereich die folgende SQL-Anweisung aus:
CREATE TABLE `bqml_tutorial.seattle_air_quality_daily` AS WITH pm25_daily AS ( SELECT avg(arithmetic_mean) AS pm25, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.pm25_nonfrm_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Acceptable PM2.5 AQI & Speciation Mass' GROUP BY date_local ), wind_speed_daily AS ( SELECT avg(arithmetic_mean) AS wind_speed, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.wind_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Wind Speed - Resultant' GROUP BY date_local ), temperature_daily AS ( SELECT avg(first_max_value) AS temperature, date_local AS date FROM `bigquery-public-data.epa_historical_air_quality.temperature_daily_summary` WHERE city_name = 'Seattle' AND parameter_name = 'Outdoor Temperature' GROUP BY date_local ) SELECT pm25_daily.date AS date, pm25, wind_speed, temperature FROM pm25_daily JOIN wind_speed_daily USING (date) JOIN temperature_daily USING (date)
Modell erstellen
Erstellen Sie ein multivariates Zeitreihenmodell. Verwenden Sie dazu die Daten aus bqml_tutorial.seattle_air_quality_daily als Trainingsdaten.
Rufen Sie die Seite BigQuery auf.
Führen Sie im SQL-Editorbereich die folgende SQL-Anweisung aus:
CREATE OR REPLACE MODEL `bqml_tutorial.arimax_model` OPTIONS ( model_type = 'ARIMA_PLUS_XREG', auto_arima=TRUE, time_series_data_col = 'temperature', time_series_timestamp_col = 'date' ) AS SELECT * FROM `bqml_tutorial.seattle_air_quality_daily`;Die Abfrage dauert mehrere Sekunden. Anschließend wird das Modell
arimax_modelimbqml_tutorial-Dataset des Bereichs Explorer angezeigt.Da die Abfrage eine
CREATE MODEL-Anweisung zum Erstellen eines Modells verwendet, gibt es keine Abfrageergebnisse.
Anomalieerkennung für Verlaufsdaten durchführen
Führen Sie die Anomalieerkennung für die Verlaufsdaten aus, mit denen Sie das Modell trainiert haben.
Rufen Sie die Seite BigQuery auf.
Führen Sie im SQL-Editorbereich die folgende SQL-Anweisung aus:
SELECT * FROM ML.DETECT_ANOMALIES ( MODEL `bqml_tutorial.arimax_model`, STRUCT(0.6 AS anomaly_prob_threshold) ) ORDER BY date ASC;
Die Ergebnisse sehen in etwa so aus:
+-------------------------+-------------+------------+--------------------+--------------------+---------------------+ | date | temperature | is_anomaly | lower_bound | upper_bound | anomaly_probability | +--------------------------------------------------------------------------------------------------------------------+ | 2009-08-11 00:00:00 UTC | 70.1 | false | 67.65880237416745 | 72.541197625832538 | 0 | +--------------------------------------------------------------------------------------------------------------------+ | 2009-08-12 00:00:00 UTC | 73.4 | false | 71.715603233887791 | 76.597998485552878 | 0.20589853827304627 | +--------------------------------------------------------------------------------------------------------------------+ | 2009-08-13 00:00:00 UTC | 64.6 | true | 67.741606808079425 | 72.624002059744512 | 0.94627126678202522 | +-------------------------+-------------+------------+--------------------+--------------------+---------------------+
Anomalieerkennung für neue Daten durchführen
Führen Sie die Anomalieerkennung für die Verlaufsdaten aus, mit denen Sie das Modell trainiert haben.
Rufen Sie die Seite BigQuery auf.
Führen Sie im SQL-Editorbereich die folgende SQL-Anweisung aus:
SELECT * FROM ML.DETECT_ANOMALIES ( MODEL `bqml_tutorial.arimax_model`, STRUCT(0.6 AS anomaly_prob_threshold), ( SELECT * FROM UNNEST( [ STRUCT<date TIMESTAMP, pm25 FLOAT64, wind_speed FLOAT64, temperature FLOAT64> ('2023-02-01 00:00:00 UTC', 8.8166665, 1.6525, 44.0), ('2023-02-02 00:00:00 UTC', 11.8354165, 1.558333, 40.5), ('2023-02-03 00:00:00 UTC', 10.1395835, 1.6895835, 46.5), ('2023-02-04 00:00:00 UTC', 11.439583500000001, 2.0854165, 45.0), ('2023-02-05 00:00:00 UTC', 9.7208335, 1.7083335, 46.0), ('2023-02-06 00:00:00 UTC', 13.3020835, 2.23125, 43.5), ('2023-02-07 00:00:00 UTC', 5.7229165, 2.377083, 47.5), ('2023-02-08 00:00:00 UTC', 7.6291665, 2.24375, 44.5), ('2023-02-09 00:00:00 UTC', 8.5208335, 2.2541665, 40.5), ('2023-02-10 00:00:00 UTC', 9.9086955, 7.333335, 39.5) ] ) ) );Die Ergebnisse sehen in etwa so aus:
+-------------------------+-------------+------------+--------------------+--------------------+---------------------+------------+------------+ | date | temperature | is_anomaly | lower_bound | upper_bound | anomaly_probability | pm25 | wind_speed | +----------------------------------------------------------------------------------------------------------------------------------------------+ | 2023-02-01 00:00:00 UTC | 44.0 | true | 36.917405956304407 | 41.79980120796948 | 0.890904731626234 | 8.8166665 | 1.6525 | +----------------------------------------------------------------------------------------------------------------------------------------------+ | 2023-02-02 00:00:00 UTC | 40.5 | false | 34.622436643607685 | 40.884690866417984 | 0.53985850962605064 | 11.8354165 | 1.558333 | +--------------------------------------------------------------------------------------------------------------------+-------------------------+ | 2023-02-03 00:00:00 UTC | 46.5 | true | 33.769587937313183 | 40.7478502941026 | 0.97434506593220793 | 10.1395835 | 1.6895835 | +-------------------------+-------------+------------+--------------------+--------------------+---------------------+-------------------------+
Bereinigen
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.