
계층적 시계열 예측
이 튜토리얼에서는 계층적 시계열을 생성하는 방법을 설명합니다. 이 튜토리얼에서는 동일한 데이터를 사용하여 두 개의 시계열 모델을 만듭니다. 하나는 계층적 예측을 사용하는 시계열 모델이고 다른 하나는 계층적 예측을 사용하지 않는 시계열입니다. 이를 통해 모델에서 반환된 결과를 비교할 수 있습니다.
이 튜토리얼에서는 iowa_liquor.sales.sales 데이터를 사용하여 모델을 학습시킵니다. 이 데이터 세트에는 아이오와주 주류 판매 공개 데이터를 사용하는 다양한 매장의 100만 개가 넘는 주류 제품에 대한 정보가 포함되어 있습니다.
튜토리얼을 진행하기 전에 다중 시계열 예측을 잘 알고 있어야 합니다. 이 주제에 대한 소개는 Google 애널리틱스 데이터에서 다중 시계열 예측 튜토리얼을 완료하세요.
필수 권한
- 데이터 세트를 만들려면
bigquery.datasets.createIAM 권한이 필요합니다. 연결 리소스를 만들려면 다음 권한이 필요합니다.
bigquery.connections.createbigquery.connections.get
모델을 만들려면 다음 권한이 필요합니다.
bigquery.jobs.createbigquery.models.createbigquery.models.getDatabigquery.models.updateDatabigquery.connections.delegate
추론을 실행하려면 다음 권한이 필요합니다.
bigquery.models.getDatabigquery.jobs.create
BigQuery에서 IAM 역할 및 권한에 대한 자세한 내용은 IAM 소개를 참조하세요.
목표
이 가이드에서는 다음을 사용합니다.
CREATE MODEL문: 시계열 모델과 계층적 시계열 모델을 만듭니다.ML.FORECAST함수: 일별 총 판매량을 예측합니다.
비용
이 튜토리얼에서는 다음을 포함하여 Google Cloud의 청구 가능한 구성요소가 사용됩니다.
- BigQuery
- BigQuery ML
BigQuery 비용에 대한 자세한 내용은 BigQuery 가격 책정 페이지를 참조하세요.
BigQuery ML 비용에 대한 자세한 내용은 BigQuery ML 가격 책정을 참조하세요.
시작하기 전에
- Google Cloud 계정에 로그인합니다. Google Cloud를 처음 사용하는 경우 계정을 만들고 Google 제품의 실제 성능을 평가해 보세요. 신규 고객에게는 워크로드를 실행, 테스트, 배포하는 데 사용할 수 있는 $300의 무료 크레딧이 제공됩니다.
-
Google Cloud Console의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
-
BigQuery API 사용 설정
-
Google Cloud Console의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
-
BigQuery API 사용 설정
데이터 세트 생성
ML 모델을 저장할 BigQuery 데이터 세트를 만듭니다.
Google Cloud 콘솔에서 BigQuery 페이지로 이동합니다.
탐색기 창에서 프로젝트 이름을 클릭합니다.
작업 보기 > 데이터 세트 만들기를 클릭합니다.

데이터 세트 만들기 페이지에서 다음을 수행합니다.
데이터 세트 ID에
bqml_tutorial를 입력합니다.위치 유형에 대해 멀티 리전을 선택한 다음 US(미국 내 여러 리전)를 선택합니다.
공개 데이터 세트는
US멀티 리전에 저장됩니다. 편의상 같은 위치에 데이터 세트를 저장합니다.나머지 기본 설정은 그대로 두고 데이터 세트 만들기를 클릭합니다.

계층적 조정
시계열 예측은 주로 원하는 여러 측정기준을 기반으로 분류하거나 집계할 수 있습니다. 이를 계층적 시계열이라고 합니다. 예를 들어, 주별 총 인구를 보여주는 인구 조사 데이터를 도시 및 우편번호별로 분류할 수 있습니다. 반대로 각 국가 또는 대륙의 데이터를 집계할 수도 있습니다.
계층적 예측을 생성하고 조정하는 데 사용할 수 있는 몇 가지 기법이 있습니다. 다음 예시에서는 아이오와주의 주류 판매에 대한 간소화된 계층 구조를 보여줍니다.

최저 수준에서 매장 수준을 표시하고 이어서 우편번호 수준, 시, 카운티, 주가 차례로 표시됩니다. 계층적 예측의 목표는 각 수준에서 모든 예측이 조정되도록 하는 것입니다. 예를 들어 앞의 그림에서는 클라이브와 디모인에 대한 예측이 폴크의 예측에 합산되어야 함을 의미합니다. 마찬가지로 폴크, 린, 스콧의 예측은 아이오와의 예측에 합산되어야 합니다.
각 수준에 대해 조정된 예측을 생성하는 데 사용할 수 있는 몇 가지 일반적인 기법이 있습니다. 그 중 한 가지 기법은 상향식 접근 방식입니다. 이 접근 방식에서는 다른 수준을 합산하기 전에 먼저 계층 구조의 최하위 수준에서 예측이 생성됩니다. 앞의 예시에서는 각 매장에 대한 예측이 다른 수준(먼저 우편번호, 이어서 도시 등)에 대한 예측 모델을 빌드하는 데 사용됩니다.
시계열 모델 만들기
먼저 아이오와주 주류 판매 데이터를 사용하여 시계열 모델을 만듭니다.
다음 GoogleSQL 쿼리는 2015년 폴크, 린, 스콧 카운티에서 판매된 일일 총 병 수를 예측하는 모델을 만듭니다. CREATE MODEL 문은 bqml_tutorial.liquor_forecast이라는 모델을 만들고 학습시킵니다.
#standardSQL
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast`
OPTIONS (
MODEL_TYPE = 'ARIMA_PLUS',
TIME_SERIES_TIMESTAMP_COL = 'date',
TIME_SERIES_DATA_COL = 'total_bottles_sold',
TIME_SERIES_ID_COL = ['store_number', 'zip_code', 'city', 'county'],
HOLIDAY_REGION = 'US')
AS
SELECT
store_number,
zip_code,
city,
county,
date,
SUM(bottles_sold) AS total_bottles_sold
FROM
`bigquery-public-data.iowa_liquor_sales.sales`
WHERE
date BETWEEN DATE('2015-01-01') AND DATE('2015-12-31')
AND county IN ('POLK', 'LINN', 'SCOTT')
GROUP BY store_number, date, city, zip_code, county;
OPTIONS(model_type='ARIMA_PLUS', time_series_timestamp_col='date', ...) 절은 ARIMA 기반 시계열 모델을 만들고 있음을 나타냅니다. 기본적으로 auto_arima=TRUE이므로 auto.ARIMA 알고리즘이 ARIMA_PLUS 모델에서 초매개변수를 자동으로 조정합니다. 이 알고리즘은 후보 모델 십여 개를 접합하고 Akaike 정보 기준(AIC)가 가장 낮은 최적 후보를 선택합니다. holiday_region 옵션을 US로 설정하면 시계열에 미국 공휴일 패턴이 있는 경우 해당 미국 공휴일 시점을 더 정확하게 모델링할 수 있습니다.
CREATE MODEL 쿼리를 실행하여 모델을 만들고 학습시킵니다.
Google Cloud 콘솔에서 BigQuery에서 쿼리 실행 버튼을 클릭합니다.
쿼리 편집기에 다음과 같은 GoogleSQL 쿼리를 입력합니다.
#standardSQL
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast`
OPTIONS (
MODEL_TYPE = 'ARIMA_PLUS',
TIME_SERIES_TIMESTAMP_COL = 'date',
TIME_SERIES_DATA_COL = 'total_bottles_sold',
TIME_SERIES_ID_COL = ['store_number', 'zip_code', 'city', 'county'],
HOLIDAY_REGION = 'US')
AS
SELECT
store_number,
zip_code,
city,
county,
date,
SUM(bottles_sold) AS total_bottles_sold
FROM
`bigquery-public-data.iowa_liquor_sales.sales`
WHERE
date BETWEEN DATE('2015-01-01') AND DATE('2015-12-31')
AND county IN ('POLK', 'LINN', 'SCOTT')
GROUP BY store_number, date, city, zip_code, county;
실행을 클릭합니다.
이 쿼리는 완료하는 데 약 37초가 소요되며 이후에는 모델(
liquor_forecast)이 탐색기 창에 표시됩니다. 이 쿼리에서는CREATE MODEL문을 사용하여 모델을 만들므로 쿼리 결과가 없습니다.
시계열 모델 결과 검사
모델을 만든 후에는 ML.FORECAST 함수를 사용하여 예측 결과를 볼 수 있습니다.
FROM 절에 지정하여 liquor_forecast 모델에 ML.FORECAST 함수를 실행합니다.
기본적으로 이 쿼리는 store_number, zip_code, city, county 열로 식별되는 데이터의 모든 고유 시계열에 대한 예측을 반환합니다.
ML.FORECAST 쿼리를 실행하려면 다음 단계를 사용합니다.
Google Cloud 콘솔에서 BigQuery에서 쿼리 실행 버튼을 클릭합니다.
쿼리 편집기에 다음과 같은 GoogleSQL 쿼리를 입력합니다.
#standardSQL
SELECT *
FROM
ML.FORECAST(
MODEL `bqml_tutorial.liquor_forecast`,
STRUCT(20 AS horizon, 0.8 AS confidence_level))
ORDER BY store_number, county, city, zip_code, forecast_timestamp
실행을 클릭합니다.
쿼리를 실행하는 데 5초 정도 걸립니다. 쿼리가 실행되면 출력에 다음과 같은 결과가 표시됩니다.

첫 번째 시계열에 대한 예측이 어떻게 표시되는지 확인합니다(store_number=2190, zip_code=50314, city=DES MOINES, county=POLK). 나머지 행을 살펴보면 다른 그룹의 예측도 확인할 수 있습니다.
일반적으로 예측은 고유한 시계열마다 생성됩니다. 특정 국가에 대한 예측과 같이 집계 수준에 대한 예측을 생성하려면 계층적 예측을 생성해야 합니다.
계층적 예측으로 시계열 모델 만들기
아이오와주 주류 판매 데이터를 사용하여 계층적 시계열 예측을 만듭니다.
다음 GoogleSQL 쿼리는 2015년 폴크, 린, 스콧 카운티에서 판매된 일일 총 병 수에 대한 계층적 예측을 생성하는 모델을 만듭니다. CREATE MODEL 문은 bqml_tutorial.liquor_forecast_hierarchical이라는 모델을 만들고 학습시킵니다.
#standardSQL
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast_hierarchical`
OPTIONS (
MODEL_TYPE = 'ARIMA_PLUS',
TIME_SERIES_TIMESTAMP_COL = 'date',
TIME_SERIES_DATA_COL = 'total_bottles_sold',
TIME_SERIES_ID_COL = ['store_number', 'zip_code', 'city', 'county'],
HIERARCHICAL_TIME_SERIES_COLS = ['zip_code', 'store_number'],
HOLIDAY_REGION = 'US')
AS
SELECT
store_number,
zip_code,
city,
county,
date,
SUM(bottles_sold) AS total_bottles_sold
FROM
`bigquery-public-data.iowa_liquor_sales.sales`
WHERE
date BETWEEN DATE('2015-01-01') AND DATE('2015-12-31')
AND county IN ('POLK', 'LINN', 'SCOTT')
GROUP BY store_number, date, city, zip_code, county;
HIERARCHICAL_TIME_SERIES_COLS 매개변수는 열 집합을 기준으로 계층적 예측을 만든다는 의미입니다. 이러한 각 열은 롤업되고 집계됩니다. 예를 들어 이전 쿼리에서는 store_number가 롤업되어 각 county, city, zip_code에 대한 예측을 표시합니다. 개별적으로 zip_code 및 store_number도 모두 롤업되어 각 county 및 city에 대한 예측을 표시합니다. 열 순서는 계층 구조의 구조를 정의하므로 중요합니다.
CREATE MODEL 쿼리를 실행하여 모델을 만들고 학습시킵니다.
Google Cloud 콘솔에서 BigQuery에서 쿼리 실행 버튼을 클릭합니다.
쿼리 편집기에 다음과 같은 GoogleSQL 쿼리를 입력합니다.
#standardSQL
CREATE OR REPLACE MODEL `bqml_tutorial.liquor_forecast_hierarchical`
OPTIONS (
MODEL_TYPE = 'ARIMA_PLUS',
TIME_SERIES_TIMESTAMP_COL = 'date',
TIME_SERIES_DATA_COL = 'total_bottles_sold',
TIME_SERIES_ID_COL = ['store_number', 'zip_code', 'city', 'county'],
HIERARCHICAL_TIME_SERIES_COLS = ['zip_code', 'store_number'],
HOLIDAY_REGION = 'US')
AS
SELECT
store_number,
zip_code,
city,
county,
date,
SUM(bottles_sold) AS total_bottles_sold
FROM
`bigquery-public-data.iowa_liquor_sales.sales`
WHERE
date BETWEEN DATE('2015-01-01') AND DATE('2015-12-31')
AND county IN ('POLK', 'LINN', 'SCOTT')
GROUP BY store_number, date, city, zip_code, county;
실행을 클릭합니다.
이 쿼리는 완료하는 데 약 45초가 소요되며 이후에는 모델(
bqml_tutorial.liquor_forecast_hierarchical)이 탐색기 창에 표시됩니다. 이 쿼리에서는CREATE MODEL문을 사용하여 모델을 만들므로 쿼리 결과가 없습니다.
계층적 시계열 모델 결과 검사
Google Cloud 콘솔에서 BigQuery에서 쿼리 실행 버튼을 클릭합니다.
쿼리 편집기에 다음과 같은 GoogleSQL 쿼리를 입력합니다.
#standardSQL SELECT * FROM ML.FORECAST( MODEL `bqml_tutorial.liquor_forecast_hierarchical`, STRUCT(30 AS horizon, 0.8 AS confidence_level)) WHERE city = 'LECLAIRE' ORDER BY county, city, zip_code, store_number, forecast_timestamp
실행을 클릭합니다.
쿼리를 실행하는 데 5초 정도 걸립니다. 쿼리가 실행되면 출력에 다음과 같은 결과가 표시됩니다.

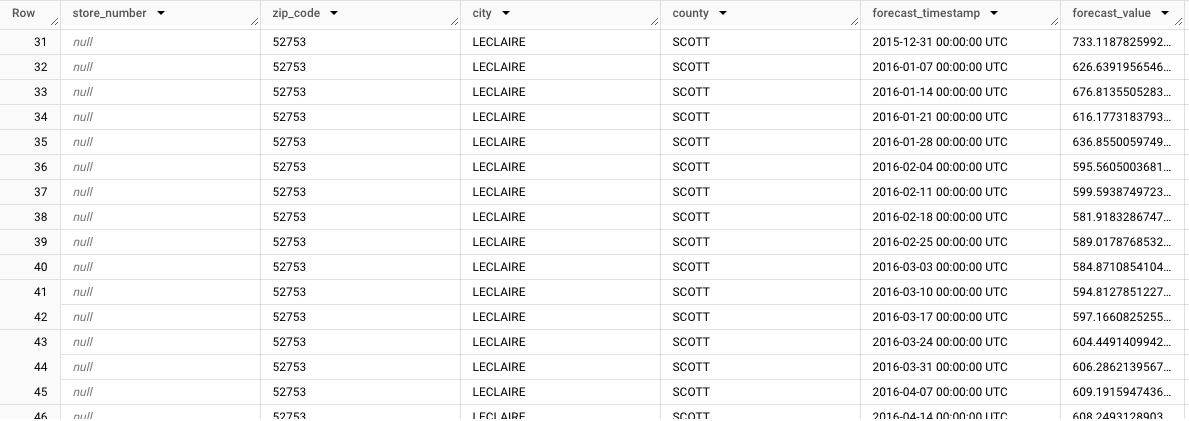
르클레어 시(store_number=NULL, zip_code=NULL, city=LECLAIRE, county=SCOTT)에 대한 집계된 예측이 어떻게 표시되는지 확인하세요. 나머지 행을 살펴보면 다른 하위 그룹의 예측도 확인할 수 있습니다. 예를 들어 다음 이미지는 우편번호 52753(store_number=NULL, zip_code=52753, city=LECLAIRE, county=SCOTT)에 대해 집계된 예측 결과를 보여줍니다.
데이터 세트 삭제
프로젝트를 삭제하면 프로젝트의 데이터 세트와 테이블이 모두 삭제됩니다. 프로젝트를 다시 사용하려면 이 튜토리얼에서 만든 데이터 세트를 삭제할 수 있습니다.
필요한 경우 Google Cloud 콘솔에서 BigQuery 페이지를 엽니다.
앞서 만든 bqml_tutorial 데이터 세트를 탐색에서 선택합니다.
창의 오른쪽에 있는 데이터 세트 삭제를 클릭합니다. 데이터 세트, 테이블, 모든 데이터가 삭제됩니다.
데이터 세트 삭제 대화상자에서 데이터 세트 이름(
bqml_tutorial)을 입력하고 삭제를 클릭하여 삭제 명령어를 확인합니다.
프로젝트 삭제
프로젝트를 삭제하는 방법은 다음과 같습니다.
- Google Cloud 콘솔에서 리소스 관리 페이지로 이동합니다.
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력한 후 종료를 클릭하여 프로젝트를 삭제합니다.
다음 단계
- NYC 도심 자전거 여행 데이터의 단일 쿼리를 사용하여 여러 시계열을 예측하는 방법을 알아보세요.
- ARIMA_PLUS를 가속화하여 몇 시간 내에 시계열 100만 개 예측을 사용 설정하는 방법을 알아보세요.
- 머신러닝 단기집중과정을 참조하여 머신러닝을 알아보세요.
- BigQuery ML 개요는 BigQuery ML 소개를 참조하세요.
- Google Cloud 콘솔에 대한 자세한 내용은 Google Cloud 콘솔 사용을 참조하세요.