
In diesem Dokument wird beschrieben, wie Sie eine in Amazon Elastic Compute Cloud (Amazon EC2) installierte Microsoft SQL Server-Instanz zu einer Microsoft SQL Server-Instanz in Compute Engine in Google Cloud migrieren. Diese Migration basiert nur auf der integrierten Datenbanktechnologie von Microsoft SQL Server. Diese Methode umfasst praktisch keine Ausfallzeit und verwendet eine Always On-Verfügbarkeitsgruppe. Die Always On-Verfügbarkeitsgruppe umfasst AWS und Google Cloud über VPN und ermöglicht die Replikation der Microsoft SQL Server-Datenbank. In diesem Dokument wird davon ausgegangen, dass Sie mit der Netzwerkeinrichtung, Google Cloud, Compute Engine, AWS und Microsoft SQL Server vertraut sind.
Wenn Sie nur die Replikation ausführen möchten, können Sie die Schritte in dieser Anleitung ausführen, dann aber stoppen, nachdem Sie Testdaten hinzugefügt haben, und die Umstellungsschritte auslassen.
Ziele
- Stellen Sie eine Multi-Cloud-Microsoft SQL Server-Always On-Verfügbarkeitsgruppe bereit, die einen Microsoft SQL Server in Amazon EC2 und einen Microsoft SQL Server in Google Cloud in Compute Engine umfasst.
- Richten Sie in Amazon EC2 eine primäre Microsoft SQL-Instanz ein.
- Richten Sie die Microsoft SQL Server-Instanz in Google Cloud als sekundär für den primären Microsoft SQL Server in AWS ein (Ziel der Datenreplikation).
- Schließen Sie die Datenmigration ab, indem Sie den sekundären Microsoft SQL Server in Google Cloud als primären Microsoft SQL Server in Google Cloud festlegen.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
- Compute Engine
- SQL Server-VMs
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Für diese Anleitung sind auch Ressourcen in AWS erforderlich, die Kosten verursachen können.
Hinweis
-
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
-
Die Abrechnung für das Google Cloud-Projekt muss aktiviert sein.
-
Aktivieren Sie Cloud Shell in der Google Cloud Console.
Informationen zur Datenbankmigration
Bei der Datenbankmigration werden die Daten aus einer Quelldatenbank in eine Zieldatenbank verschoben. Im Allgemeinen können Sie eine Teilmenge der Daten migrieren oder ein anderes Schema in der Quell- und Zieldatenbank haben. In dieser Anleitung geht es jedoch um eine homogene Datenbankmigration, bei der die Migration der vollständigen Datenbank ohne Änderungen erforderlich ist. Die Zieldatenbank ist eine Kopie der Quelldatenbank.
Migration der Datenbank ohne Ausfallzeiten
Der Begriff ohne Ausfallzeiten bezieht sich auf die Tatsache, dass die Clients, die auf die Quelldatenbank zugreifen, während der Migration voll funktionsfähig bleiben und nicht unterbrochen werden. Die einzige Ausfallzeit tritt auf, wenn die Clients nach Abschluss der Migration wieder eine Verbindung zur Zieldatenbank herstellen müssen. Auch wenn diese Methode nicht völlig frei von Ausfallzeiten ist, bezieht sich der Begriff auf dieses Szenario mit minimalen Ausfallzeiten.
Eine allgemeine Beschreibung der Datenbankmigration finden Sie unter Datenbankmigration – Konzepte und Prinzipien (Teil 1) und Datenbankmigration – Konzepte und Prinzipien (Teil 2). Diese Artikel bieten einen Überblick über die mögliche Komplexität der Datenbankmigration in verschiedenen Szenarien.
Datenbankmigration mit Microsoft SQL Server-Technologie
Einige Datenbankmigrationstechnologien bieten separate Komponenten und Dienste. Wenn für die Datenbankmigration eine Kopie der Quelldatenbank erforderlich ist, können Sie die integrierte Microsoft SQL Server-Technologie nutzen.
In dieser Anleitung wird die Microsoft SQL Server-Always On-Verfügbarkeitsgruppen-Technologie verwendet, um die Quelldatenbank (primär) mit einer Zieldatenbank (sekundär) zu verbinden. Diese Technologie bietet eine asynchrone Replikation von der primären zur sekundären Datenbank. Da sich die primäre Datenbank in Amazon EC2 und die sekundäre Datenbank in Google Cloud in Compute Engine befindet, führt die Replikation zur Datenbankmigration. Nachdem alle Daten durch eine asynchrone Replikation migriert wurden, wird die sekundäre Datenbank zur primären Replikation hochgestuft und die Clients können für die weitere Verarbeitung wieder eine Verbindung zur neuen primären Datenbank herstellen.
Dieser Ansatz unterstützt explizite Tests durch eine Testreplikation in eine Testdatenbank: Sie können die Replikation starten, eine Weile lang ausführen und dann beenden. Die Testzieldatenbank ist konsistent. Sie können sie zum Testen der Anwendung verwenden. Nach Abschluss des Tests können Sie die Testzieldatenbank löschen und die Replikation für eine Live-Datenbank initiieren.
Architektur der Multi-Cloud-Datenbankmigration
Das folgende Diagramm zeigt die allgemeine Bereitstellungsarchitektur für eine Multi-Cloud-Datenbankmigration:

Das obige Diagramm zeigt die (primäre) SQL Server-Quelldatenbank in AWS als Amazon EC2-Instanz. Das Diagramm zeigt auch die (sekundäre) Zieldatenbank in Google Cloud. Die Datenbanken sind mit einer Always On-Verfügbarkeitsgruppe verbunden. Die Netzwerkverbindung zwischen AWS und Google Cloud wird als gesicherte HA VPN-Verbindung angesehen.
Multi-Cloud-Microsoft SQL Server-Verfügbarkeitsgruppe einrichten
In den folgenden Abschnitten richten Sie zwei Always On-Verfügbarkeitsgruppen mit zwei Knoten ein, in denen sich der primäre Knoten in AWS befindet, und der sekundäre Knoten befindet sich in Google Cloud. Diese Konfiguration wird weiter oben in diesem Dokument unter Architektur der Multi-Cloud-Datenbankmigration beschrieben.
Die folgenden Tabellen enthalten eine Zusammenfassung der Knoten und IP-Adressen, die Sie in dieser Anleitung einrichten. Für jede Datenbank-VM weisen Sie neben der primären IP-Adresse zwei IP-Adressen zu: eine IP-Adresse für den Windows Server-Failover-Cluster (WSFC) und eine IP-Adresse für den Verfügbarkeitsgruppen-Listener.
| Anbieter | Instanz | Primäre IP-Adresse | WSFC- und Verfügbarkeitsgruppen-Listener-IPs | WSFC | Verfügbarkeitsgruppe |
|---|---|---|---|---|---|
| AWS | cluster-sql1 |
192.168.1.4 |
192.168.1.5
|
Name: cluster-dbclus
|
Name: cluster-ag
|
| Google Cloud | cluster-sql2 |
10.1.1.4 |
10.1.1.5
|
| Anbieter | Instanz | Primäre IP-Adresse | – |
|---|---|---|---|
AWS |
dc-windows |
192.168.1.100 |
Domain controller |
In der Anleitung werden diese Namen und IP-Adressen beispielhaft verwendet. Wenn Sie Ihre eigenen Namen und IP-Adressen verwenden möchten, ersetzen Sie die Beispielwerte in der Anleitung.
Voraussetzungen für AWS
Bei AWS sollten Sie zwei virtuelle Maschinen haben, eine mit dem Domaincontroller und eine mit SQL Server. Der in dieser Anleitung verwendete Domaincontroller hat die folgende Konfiguration:
Domain : dbeng.com
Domain controller : Name: dc-windows
Private IP: 192.168.1.100
VPC Subnet : 192.168.1.0/24
SQL Server service account: dbeng\sql_service
Die als Beispiel in dieser Anleitung verwendete SQL Server-VM gehört zu einer Windows Active Directory-Domain in Amazon EC2. Der Server hat zwei sekundäre IP-Adressen, die vom WSFC und vom Verfügbarkeitsgruppen-Listener verwendet werden sollen. Die SQL Server-VM hat folgende Konfiguration:
VM Instance : Name: cluster-sql1
Private IP: 192.168.1.4
Secondary Private IPs: 192.168.1.5, 192.168.1.6
VPC Subnet : 192.168.1.0/24
Sie können das Dienstkonto NT SERVICE\MSSQLSERVER als SQL Server-Dienstkonto verwenden. Während der Einrichtung der Always On-Verfügbarkeitsgruppen gewähren Sie Zugriff auf die Computerkonten (dbeng\cluster-sql1$, dbeng\cluster-sql2$) anstelle des Domainkontos. Der folgende Abschnitt enthält die Befehle zum Konfigurieren der Verfügbarkeitsgruppe.
Voraussetzungen für die Verbindung zwischen AWS und Google Cloud
Richten Sie die folgende Netzwerkverbindung ein, um Ihr AWS-Projekt mit Ihrem Google Cloud-Projekt zu verbinden:
- Richten Sie in den jeweiligen Projekten eine Google Virtual Private Cloud und eine AWS-VPC ein und konfigurieren Sie ein VPN zwischen den VPCs. Informationen zum Einrichten eines VPN zwischen Google Cloud und AWS finden Sie unter Multi-Cloud-VPN und Multi-Zonen-Subnetzwerke – Netzwerkeinrichtung für Multi-Cloud-Datenbankbereitstellungen.
Erstellen Sie in Cloud Shell ein Subnetz in dem Google Cloud-Projekt, in dem Sie die SQL Server-Instanz erstellen. Wenn Sie bereits ein Subnetz haben, können Sie es verwenden. Achten Sie aber darauf, die Firewallregeln im nächsten Schritt einzurichten.
gcloud compute networks create demo-vpc --subnet-mode custom gcloud compute networks subnets create demo-subnet1 \ --network demo-vpc --region us-east4 --range 10.1.1.0/24In dieser Anleitung werden die folgenden Werte verwendet:
- VPC:
demo-vpc - Subnetz:
demo-subnet1; 10.1.1.0/24
Das Subnetz wird auf der Seite VPC-Netzwerke der Google Cloud Console angezeigt.
- VPC:
Erstellen Sie in Ihrem Google Cloud-Projekt eine Firewallregel, um den gesamten Traffic zwischen Ihrem Google Cloud-Subnetz und Ihrem AWS-Subnetz zu öffnen:
gcloud compute firewall-rules create allow-vpn-ports \ --network demo-vpc --allow tcp:1-65535,udp:1-65535,icmp \ --source-ranges 10.1.1.0/24,192.168.1.0/24Die Firewallregel wird auf der Seite Firewall-Richtlinien der Google Cloud Console angezeigt.
Erstellen Sie in Ihrem AWS-Projekt eine Firewallregel in der Sicherheitsgruppe, um den gesamten Traffic zwischen Ihrem Google Cloud-Subnetz und Ihrem AWS-Subnetz zu öffnen, wie im folgenden Screenshot dargestellt:
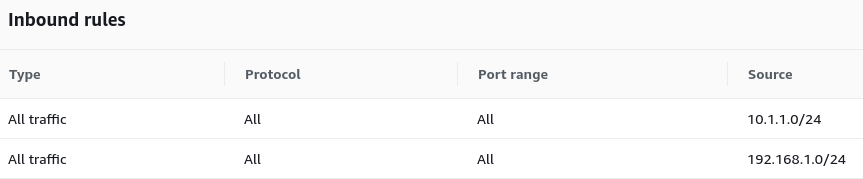
In einer Produktionsumgebung kann es sinnvoll sein, nur die erforderlichen TCP/UDP-Ports zu öffnen. Das Öffnen nur der erforderlichen Ports schränkt potenziell schädlichen Traffic ein und folgt einem Prinzip des minimal Notwendigen.
Instanz in Google Cloud für die Always On-Verfügbarkeitsgruppe erstellen
Diese Anleitung funktioniert mit den folgenden Microsoft SQL Server-Editionen und -Funktionen:
- Version:
- Microsoft SQL Server 2016 Enterprise Edition oder
- Microsoft SQL Server 2017 Enterprise Edition oder
- Microsoft SQL Server 2019 Enterprise Edition oder
- Microsoft SQL Server 2022 Enterprise Edition oder
- Microsoft SQL Server 2016 Standard Edition oder
- Microsoft SQL Server 2017 Standard Edition oder
- Microsoft SQL Server 2019 Standard Edition oder
- Microsoft SQL Server 2022 Standard Edition
- Feature: Always On-Verfügbarkeitsgruppen
In der folgenden Anleitung wird das Image für Microsoft SQL Server 2019 Enterprise Edition verwendet: sql-ent-2019-win-2019. Wenn Sie Microsoft SQL Server 2017, 2016 oder 2022 Enterprise Editions installieren möchten, verwenden Sie stattdessen sql-ent-2017-win-2019, sql-ent-2016-win-2019 bzw. sql-ent-2022-win-2019. Eine Liste aller Images finden Sie auf der Compute Engine-Seite Details zu Betriebssystemen.
In den folgenden Schritten erstellen Sie eine SQL Server-Instanz in Google Cloud für die Verfügbarkeitsgruppe. Die Instanz verwendet die folgende IP-Adresskonfiguration mit Alias-IP-Adressen:
VM Instance: Name: cluster-sql2
Private IP: 10.1.1.4
Secondary Private IPs: 10.1.1.5, 10.1.1.6
Sie erstellen eine Instanz mit dem Namen cluster-sql2 aus öffentlichen SQL Server-Images mit einer Größe von 200 GB Bootlaufwerk und einem n1-highmem-4-Maschinentyp. SQL Server-Instanzen erfordern in der Regel mehr Rechenressourcen als die Domaincontroller-Instanz. Wenn Sie später zusätzliche Rechenressourcen benötigen, können Sie den Maschinentyp dieser Instanzen ändern. Wenn zusätzlicher Speicherplatz erforderlich ist, fügen Sie ein Laufwerk hinzu oder ändern die Größe des nichtflüchtigen Bootlaufwerks. In größeren Verfügbarkeitsgruppen können Sie mehrere Instanzen erstellen.
Die folgenden Schritte enthalten auch das Flag --metadata sysprep-specialize-script-ps1, das während der Instanzerstellung einen Microsoft PowerShell-Befehl ausführt, um das Failover-Clustering-Feature zu installieren.
Erstellen Sie in Cloud Shell eine SQL Server-Instanz in Google Cloud, die dieselbe Betriebssystemversion wie in AWS verwendet:
gcloud compute instances create cluster-sql2 --machine-type n1-highmem-4 \ --boot-disk-type pd-ssd --boot-disk-size 200GB \ --image-project windows-sql-cloud --image-family sql-ent-2019-win-2019 \ --zone us-east4-a \ --network-interface "subnet=demo-subnet1,private-network-ip=10.1.1.4,aliases=10.1.1.5;10.1.1.6" \ --can-ip-forward \ --metadata sysprep-specialize-script-ps1="Install-WindowsFeature Failover-Clustering -IncludeManagementTools;"Legen Sie einen Windows-Nutzernamen und ein Passwort fest, bevor Sie eine Verbindung zur Instanz herstellen.
Wenn Sie das Remote Desktop Protocol (RDP) auf Ihrem Laptop verwenden, erstellen Sie eine Firewallregel, die den Zugriff auf die Instanz ermöglicht.
Stellen Sie über RDP eine Verbindung zur Google Cloud-Instanz her und öffnen Sie eine PowerShell mit erweiterten Rechten (als Administrator ausgeführt).
In dieser Anleitung konfigurieren Sie ein lokales DNS für die Verwendung des Domaincontrollers in AWS (
192.168.1.100), damit keine weitere VM in Google Cloud erstellt wird. Für Produktionsarbeitslasten empfehlen wir die Verwendung eines Domaincontrollers (primär oder sekundär) in Google Cloud, um die Authentifizierung über den VPN-Tunnel zu vermeiden.In der PowerShell mit erweiterten Rechten sollten Sie den Domaincontroller
192.168.1.100anpingen können:ping 192.168.1.100Wenn der Ping-Befehl fehlschlägt, prüfen Sie, dass die Firewall und der VPN-Tunnel ordnungsgemäß zwischen AWS und Google Cloud konfiguriert wurden. Weitere Informationen finden Sie weiter oben in diesem Dokument unter Voraussetzungen für die Verbindung.
Da der Server ursprünglich mit DHCP eingerichtet wurde, ändern Sie die Instanz so, dass statische IP-Adressen verwendet werden:
netsh interface ip set address name=Ethernet static 10.1.1.4 255.255.255.0 10.1.1.1 1Nach dem Ausführen des vorherigen Befehls wird die Verbindung getrennt. Stellen Sie die Verbindung wieder in RDP her.
Konfigurieren Sie das lokale DNS für die Verwendung des Domaincontrollers in AWS und öffnen Sie die lokalen Firewallports für SQL Server. Wenn Sie die Firewall-Ports öffnen, kann der SQL Server eine Verbindung zu Remote-SQL-Servern herstellen.
netsh interface ip set dns Ethernet static 192.168.1.100 netsh advfirewall firewall add rule name="Open Port 5022 for Availability Groups" dir=in action=allow protocol=TCP localport=5022 netsh advfirewall firewall add rule name="Open Port 1433 for SQL Server" dir=in action=allow protocol=TCP localport=1433Fügen Sie die Instanz der Windows-Domain hinzu:
Add-Computer -DomainName "dbeng.com" -Credential "dbeng.com\Administrator" -Restart -ForceMit diesem Befehl werden Sie aufgefordert, die Anmeldedaten des Domainadministrators einzugeben. Wenn der Befehl ausgeführt wurde, startet die Instanz wieder.
Wenn der Befehl nicht ausgeführt wird, prüfen Sie, ob Sie ihn als Administrator ausführen.
Verwenden Sie das Konto
dbeng\Administrator, um eine Verbindung zur Instanz über RDP herzustellen.Legen Sie das SQL Server-Dienstkonto fest:
- Öffnen Sie den Konfigurationsmanager SQL Server 2019.
- Klicken Sie auf dem Tab SQL Server-Dienste mit der rechten Maustaste auf SQL Server (MSSQLSERVER) und klicken Sie dann auf Eigenschaften.
- Richten Sie das Konto
dbeng\sql_serviceein und legen ein Passwort fest. - Starten Sie SQL Server neu.
Benennen Sie die SQL Server-Instanz so um, dass sie dem Computernamen entspricht, und starten Sie SQL Server neu:
Invoke-Sqlcmd -Query "EXEC sp_dropserver @@SERVERNAME, @droplogins='droplogins'" Invoke-Sqlcmd -Query "EXEC sp_addserver '$env:COMPUTERNAME', local" Stop-Service -Name "MSSQLServer" -Force Start-Service -Name "MSSQLServer"
Als Nächstes konfigurieren Sie die Instanz in AWS.
Instanz in AWS konfigurieren
In dieser Anleitung wird davon ausgegangen, dass Sie Folgendes in AWS konfiguriert haben:
- Die SQL Server-Instanz ist Teil der Active Directory-Domain.
- Das lokale DNS funktioniert ordnungsgemäß und der Name des Remote-Servers in Google Cloud (
cluster-sql2.dbeng.com)kann in eine IP-Adresse übersetzt werden. - Firewallregeln werden zwischen den Subnetzen in AWS und Google Cloud geöffnet.
So konfigurieren Sie cluster-sql1 in AWS:
- Stellen Sie über RDP eine Verbindung zu AWS her (
cluster-sql1). - Öffnen Sie eine PowerShell mit erweiterten Rechten (wird als Administrator ausgeführt).
Installieren Sie Windows Failover Clustering, falls es noch nicht installiert ist.
Install-WindowsFeature Failover-Clustering -IncludeManagementToolsBei diesem Befehl ist ein Neustart erforderlich, falls die Funktion noch nicht installiert war. Fahren Sie nach dem Neustart mit dem nächsten Schritt fort.
Öffnen Sie die lokalen Firewallports für die SQL Server-Instanz in AWS:
netsh advfirewall firewall add rule name="Open Port 5022 for Availability Groups" dir=in action=allow protocol=TCP localport=5022 netsh advfirewall firewall add rule name="Open Port 1433 for SQL Server" dir=in action=allow protocol=TCP localport=1433 netsh advfirewall firewall add rule name="ICMP Allow incoming V4 echo request" protocol="icmpv4:8,any" dir=in action=allowBenennen Sie die SQL Server-Instanz so um, dass sie dem Computernamen entspricht, und starten Sie SQL Server neu:
Invoke-Sqlcmd -Query "EXEC sp_dropserver @@SERVERNAME, @droplogins='droplogins'" Invoke-Sqlcmd -Query "EXEC sp_addserver '$env:COMPUTERNAME', local" Stop-Service -Name "MSSQLServer" -Force Start-Service -Name "MSSQLServer"Bestätigen Sie, dass die Instanz in AWS eine Verbindung zur Instanz in Google Cloud herstellen kann, wenn der Remote-Instanzname verwendet wird. Führen Sie die folgenden Befehle aus einem Domainkonto aus, das Zugriff auf den SQL Server gewährt hat, um die Verbindung zu testen.
Netzwerkverbindung testen:
ping -4 cluster-sql2.dbeng.comDie Ausgabe sieht so aus:
RESULTS: Pinging cluster-sql2.dbeng.com [10.1.1.4] with 32 bytes of data: Reply from 10.1.1.4: bytes=32 time=3ms TTL=127 Reply from 10.1.1.4: bytes=32 time=2ms TTL=127 Reply from 10.1.1.4: bytes=32 time=2ms TTL=127 Reply from 10.1.1.4: bytes=32 time=2ms TTL=127Testen Sie die Windows-Authentifizierung beim Remote-Server:
sqlcmd -E -S cluster-sql2.dbeng.com -Q "SELECT 'CONNECTED'"Die Ausgabe sieht so aus:
RESULTS: -------------------------------------------------------------------------- CONNECTED (1 rows affected)
Wenn Sie keine Verbindung herstellen können, prüfen Sie, ob das DNS ordnungsgemäß funktioniert und ob die Firewallregeln zwischen den AWS- und Google Cloud-Subnetzen geöffnet sind.
Überprüfen, ob die Google Cloud-Instanz der Verfügbarkeitsgruppe beitreten kann
- Verwenden Sie das Konto
dbeng\Administrator, um über RDP (cluster-sql2) eine Verbindung zur Google Cloud-Instanz herzustellen. - Öffnen Sie eine PowerShell mit erweiterten Rechten (wird als Administrator ausgeführt).
Bestätigen Sie, dass die Instanz in Google Cloud bei Verwendung des Instanznamens eine Verbindung zur Instanz in AWS herstellen kann. Führen Sie zum Testen der Verbindung die folgenden Befehle über ein Domainkonto aus, das Verbindungszugriff auf den SQL Server gewährt hat.
Netzwerkverbindung testen:
ping -4 cluster-sql1.dbeng.comDie Ausgabe sieht so aus:
RESULTS: Pinging CLUSTER-SQL1.dbeng.com [192.168.1.4] with 32 bytes of data: Reply from 192.168.1.4: bytes=32 time=3ms TTL=127 Reply from 192.168.1.4: bytes=32 time=2ms TTL=127 Reply from 192.168.1.4: bytes=32 time=3ms TTL=127 Reply from 192.168.1.4: bytes=32 time=2ms TTL=127Testen Sie die Windows-Authentifizierung beim Remote-Server:
sqlcmd -E -S cluster-sql1 -Q "SELECT 'CONNECTED'"Die Ausgabe sieht so aus:
RESULTS: ------------------------------------------------------------ CONNECTED (1 rows affected)Wenn Sie keine Verbindung herstellen können, prüfen Sie, ob das DNS ordnungsgemäß funktioniert und ob die Firewallregeln zwischen den AWS- und Google Cloud-Subnetzen geöffnet sind.
Erstellen Sie Ordner unter
C:\SQLDataundC:\SQLLog. Die Datenbankdaten und Logdateien verwenden diese Ordner.New-Item "C:\SQLData" –type directory New-Item "C:\SQLLog" –type directoryErstellen Sie unter
C:\SQLBackupeinen Ordner und eine Windows-Freigabe unter\\cluster-sql2\SQLBackup, um die Sicherung von der AWS-Instanz zu übertragen. Sie können jede andere Netzwerkfreigabe verwenden, die für beide Server verfügbar ist.New-Item "C:\SQLBackup" –type directory New-SmbShare -Name "SQLBackup" -Path "C:\SQLBackup" -FullAccess "dbeng.com\cluster-sql1$","dbeng.com\cluster-sql2$","NT SERVICE\MSSQLSERVER","authenticated users","dbeng.com\sql_service"
Die Instanzen sind nun für die Verfügbarkeitsgruppe bereit. Da Sie nur zwei Instanzen haben, konfigurieren Sie im nächsten Abschnitt einen Dateifreigabezeugen, um im Zweifelsfall eine ausschlaggebende Stimme zu haben und ein Quorum zu erreichen.
Dateifreigabenzeuge erstellen
Wenn Sie für das Failover-Szenario eine ausschlaggebende Stimme bereitstellen und ein Quorum erreichen möchten, können Sie einen Dateifreigabezeugen hinzufügen. Für diese Anleitung erstellen Sie den Dateifreigabezeugen in der Domain-Controller-VM. In einer Produktionsumgebung würden Sie den Dateifreigabezeugen auf jedem Server in Ihrer Active Directory-Domain erstellen.
- Verwenden Sie das
dbeng\Administratorum über RDP eine Verbindung zur Domaincontroller-VM,dc-windows, herzustellen. - Öffnen Sie eine PowerShell mit erweiterten Rechten (wird als Administrator ausgeführt).
Erstellen Sie für den Dateifreigabenzeugen ein Verzeichnis:
New-Item "C:\QWitness" –type directoryGeben Sie das Verzeichnis frei.
New-SmbShare -Name "QWitness" -Path "C:\QWitness" -Description "SQL File Share Witness" -FullAccess "dbeng.com\Administrator", "dbeng.com\cluster-sql1$", "dbeng.com\cluster-sql2$"Verwenden Sie
dbeng.com\Administrator, um über RDP sowohl mitcluster-sql1als auch mitcluster-sql2eine Verbindung herzustellen.Prüfen Sie, ob Sie über beide Server auf das freigegebene Verzeichnis zugreifen können:
dir \\dc-windows\QWitnessWenn Sie nicht auf das freigegebene Verzeichnis zugreifen können, versuchen Sie, die Netzwerkverbindung auf dem Knoten zu ändern und den WINS-Server so einzurichten, dass er mit dem Domainserver übereinstimmt. Die Änderung der Netzwerkverbindung kann einige Sekunden dauern. Im folgenden Screenshot sehen Sie die aktualisierten WINS-Einstellungen:
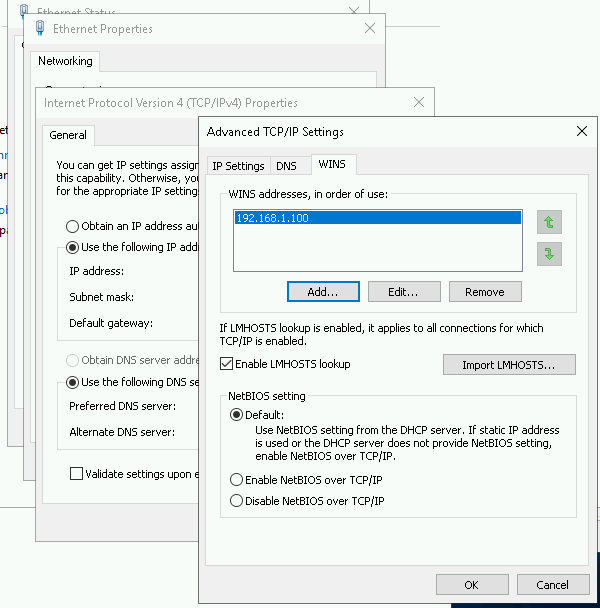
Alles ist nun für die Verfügbarkeitsgruppe bereit. Als Nächstes konfigurieren Sie das Failover-Clustering.
Failover-Clustering konfigurieren
In diesem Abschnitt konfigurieren Sie den WSFC und aktivieren Always On-Hochverfügbarkeit für beide Instanzen. Führen Sie alle folgenden Konfigurationsbefehle von der Instanz in AWS aus.
- Stellen Sie über RDP eine Verbindung zur AWS-Instanz her (
cluster-sql1). - Öffnen Sie eine PowerShell mit erweiterten Rechten (wird als Administrator ausgeführt).
Legen Sie Variablen für Ihre Clusterumgebung fest. Geben Sie für dieses Beispiel die folgenden Variablen an:
$node1 = "cluster-sql1.dbeng.com" $node2 = "cluster-sql2.dbeng.com" $nameWSFC = "cluster-dbclus" #Name of cluster $ipWSFC1 = "192.168.1.5" #IP address of cluster in subnet 1 (AWS) $ipWSFC2 = "10.1.1.5" #IP address of cluster in subnet 2 (Google Cloud)Erstellen Sie den Failovercluster. (Der Befehl kann eine Weile dauern):
New-Cluster -Name $nameWSFC -Node $node1, $node2 -NoStorage -StaticAddress $ipWSFC1, $ipWSFC2 Set-ClusterQuorum -FileShareWitness \\dc-windows\QWitnessAktivieren Sie Always On-Hochverfügbarkeit auf Knoten 1. Wenn Sie Always On noch nicht aktiviert haben, wird bei diesen Befehlen SQL Server neu gestartet.
Enable-SqlAlwaysOn -ServerInstance $node1 -ForceAktivieren Sie Always On-Hochverfügbarkeit auf Knoten 2. Diese Befehle beenden den SQL Server-Dienst, bevor SQL Always On aktiviert wird. Sie können daher den folgenden Fehler ignorieren:
Enable-SqlAlwaysOn : StopService failed for Service 'MSSQLSERVER'.Get-Service -ComputerName $node2 -Name "MSSQLServer" | Stop-Service -Force Enable-SqlAlwaysOn -ServerInstance $node2 -Force Get-Service -ComputerName $node2 -Name "MSSQLServer" | Start-ServiceErstellen Sie Ordner unter
C:\SQLDataundC:\SQLLog. Verwenden Sie diese Ordner für die Datenbankdaten- und Logdateien. Wenn Ihr Server bereits eine Datenbank mit dieser Ordnerstruktur hat, können Sie diesen Schritt überspringen. Wenn Sie sich nicht sicher sind, führen Sie die Befehle aus und ignorieren Sie alle Fehlermeldungen zu bereits vorhandenen Ordnern.New-Item "C:\SQLData" –type directory New-Item "C:\SQLLog" –type directory
Der Failover Cluster-Manager ist fertig. Als Nächstes erstellen Sie die Verfügbarkeitsgruppe.
Verfügbarkeitsgruppe erstellen
In diesem Abschnitt erstellen Sie eine Testdatenbank in AWS (cluster-sql1) und konfigurieren sie so, dass sie mit einer neuen Verfügbarkeitsgruppe arbeitet. Alternativ können Sie eine vorhandene Datenbank für die Verfügbarkeitsgruppe angeben.
- Stellen Sie über RDP eine Verbindung zur AWS-Instanz her (
cluster-sql1). - Öffnen Sie eine PowerShell mit erweiterten Rechten (wird als Administrator ausgeführt).
Erstellen Sie unter
C:\SQLBackupeinen Ordner, um eine Sicherung der Datenbank zu speichern. Die Sicherung ist erforderlich, bevor Sie die Verfügbarkeitsgruppe für eine neue Datenbank einrichten können.New-Item "C:\SQLBackup" –type directoryWenn Sie noch keine Datenbank konfiguriert haben, führen Sie SQL Server Management Studio aus und erstellen eine Testdatenbank in der AWS-Instanz (
cluster-sql1):CREATE DATABASE TestDB ON PRIMARY (NAME = 'TestDB_Data', FILENAME='C:\SQLData\TestDB_Data.mdf', SIZE = 256MB, MAXSIZE = UNLIMITED, FILEGROWTH = 256MB ) LOG ON (NAME = 'TestDB_Log', FILENAME='C:\SQLLog\TestDB_Log.ldf', SIZE = 256MB, MAXSIZE = UNLIMITED, FILEGROWTH = 256MB ) GO USE [TestDB] Exec dbo.sp_changedbowner @loginame = 'sa', @map = false; ALTER DATABASE [TestDB] SET RECOVERY FULL; GO BACKUP DATABASE TestDB to disk = 'C:\SQLBackup\TestDB-backup.bak' WITH INIT GOWählen Sie in Microsoft SQL Server Management Studio die Option Abfrage > SQLCMD-Modus aus.
SQL Server Management Studio bietet einen Assistenten zum Erstellen der Verfügbarkeitsgruppen. In dieser Anleitung verwenden Sie stattdessen SQL-Befehle, damit Sie Probleme, die beim Herstellen der Verbindung über verschiedene Cloud-Anbieter auftreten können, leichter beheben können. Sie können den Assistenten für Verfügbarkeitsgruppen ausführen und mit dem nächsten Schritt fortfahren, um die Synchronisierung der Verfügbarkeitsgruppe zu prüfen.
Führen Sie die folgenden Abfragen im SQLCDM-Modus aus. Wenn Sie eine bereits vorhandene Datenbank verwenden, ersetzen Sie
TestDBdurch den Namen Ihrer Datenbank.Erstellen Sie im ersten Knoten einen Endpunkt und gewähren Sie die Berechtigung für den Endpunkt:
:Connect CLUSTER-SQL1 IF NOT EXISTS (SELECT state FROM sys.endpoints WHERE name = N'Hadr_endpoint') BEGIN CREATE ENDPOINT [Hadr_endpoint] AS TCP (LISTENER_PORT = 5022) FOR DATA_MIRRORING (ROLE = WITNESS, ENCRYPTION = REQUIRED ALGORITHM AES) END GO IF (SELECT state FROM sys.endpoints WHERE name = N'Hadr_endpoint') <> 0 BEGIN ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED END GO use [master] GO IF SUSER_ID('DBENG\sql_service') IS NULL CREATE LOGIN [DBENG\sql_service] FROM WINDOWS GO GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [DBENG\sql_service] GOAktivieren Sie im ersten Knoten die erweiterte Ereignissitzung
AlwaysOn_health. Für die Verfügbarkeitsgruppen ist die erweiterte Ereignissitzung erforderlich.:Connect CLUSTER-SQL1 IF EXISTS(SELECT * FROM sys.server_event_sessions WHERE name='AlwaysOn_health') BEGIN ALTER EVENT SESSION [AlwaysOn_health] ON SERVER WITH (STARTUP_STATE=ON); END IF NOT EXISTS(SELECT * FROM sys.dm_xe_sessions WHERE name='AlwaysOn_health') BEGIN ALTER EVENT SESSION [AlwaysOn_health] ON SERVER STATE=START; END GOErstellen Sie im zweiten Knoten einen Endpunkt und gewähren Sie die Berechtigung für den Endpunkt:
:Connect CLUSTER-SQL2 IF NOT EXISTS (SELECT state FROM sys.endpoints WHERE name = N'Hadr_endpoint') BEGIN CREATE ENDPOINT [Hadr_endpoint] AS TCP (LISTENER_PORT = 5022) FOR DATA_MIRRORING (ROLE = WITNESS, ENCRYPTION = REQUIRED ALGORITHM AES) END GO IF (SELECT state FROM sys.endpoints WHERE name = N'Hadr_endpoint') <> 0 BEGIN ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED END GO use [master] GO IF SUSER_ID('DBENG\sql_service') IS NULL CREATE LOGIN [DBENG\sql_service] FROM WINDOWS GO GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [DBENG\sql_service] GOAktivieren Sie im zweiten Knoten die erweiterte Ereignissitzung
AlwaysOn_health. Für die Verfügbarkeitsgruppen ist die erweiterte Ereignissitzung erforderlich.:Connect CLUSTER-SQL2 IF EXISTS(SELECT * FROM sys.server_event_sessions WHERE name='AlwaysOn_health') BEGIN ALTER EVENT SESSION [AlwaysOn_health] ON SERVER WITH (STARTUP_STATE=ON); END IF NOT EXISTS(SELECT * FROM sys.dm_xe_sessions WHERE name='AlwaysOn_health') BEGIN ALTER EVENT SESSION [AlwaysOn_health] ON SERVER STATE=START; END GOErstellen Sie im ersten Knoten die Verfügbarkeitsgruppe:
:Connect CLUSTER-SQL1 USE [master] GO --DROP AVAILABILITY GROUP [cluster-ag]; GO CREATE AVAILABILITY GROUP [cluster-ag] WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY, DB_FAILOVER = OFF, DTC_SUPPORT = NONE) FOR DATABASE [TestDB] REPLICA ON N'CLUSTER-SQL1' WITH (ENDPOINT_URL = N'TCP://CLUSTER-SQL1.dbeng.com:5022', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SEEDING_MODE = MANUAL), N'CLUSTER-SQL2' WITH (ENDPOINT_URL = N'TCP://cluster-sql2.dbeng.com:5022', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, BACKUP_PRIORITY = 50, SEEDING_MODE = MANUAL); GOFügen Sie den zweiten Knoten der neu erstellten Verfügbarkeitsgruppe hinzu:
:Connect CLUSTER-SQL2 ALTER AVAILABILITY GROUP [cluster-ag] JOIN; GOErstellen Sie im ersten Knoten eine Datenbanksicherung:
:Connect CLUSTER-SQL1 BACKUP DATABASE [TestDB] TO DISK = N'\\CLUSTER-SQL2\SQLBackup\TestDB.bak' WITH COPY_ONLY, FORMAT, INIT, SKIP, REWIND, NOUNLOAD, COMPRESSION, STATS = 5 GOStellen Sie die Datenbanksicherung auf dem zweiten Knoten wieder her:
:Connect CLUSTER-SQL2 RESTORE DATABASE [TestDB] FROM DISK = N'\\CLUSTER-SQL2\SQLBackup\TestDB.bak' WITH NORECOVERY, NOUNLOAD, STATS = 5 GOErstellen Sie im ersten Knoten eine Transaktionslogsicherung:
:Connect CLUSTER-SQL1 BACKUP LOG [TestDB] TO DISK = N'\\CLUSTER-SQL2\SQLBackup\TestDB.trn' WITH NOFORMAT, INIT, NOSKIP, REWIND, NOUNLOAD, COMPRESSION, STATS = 5 GOStellen Sie die Sicherung des Transaktionslogs im zweiten Knoten wieder her:
:Connect CLUSTER-SQL2 RESTORE LOG [TestDB] FROM DISK = N'\\CLUSTER-SQL2\SQLBackup\TestDB.trn' WITH NORECOVERY, NOUNLOAD, STATS = 5 GO
Um sicherzustellen, dass die Synchronisierung keine Fehler enthält, führen Sie die folgende Abfrage aus und prüfen Sie, ob die Spalte
connected_state_descden WertCONNECTEDenthält::Connect CLUSTER-SQL2 select r.replica_server_name, r.endpoint_url, rs.connected_state_desc, rs.last_connect_error_description, rs.last_connect_error_number, rs.last_connect_error_timestamp from sys.dm_hadr_availability_replica_states rs join sys.availability_replicas r on rs.replica_id=r.replica_id where rs.is_local=1Wenn in der Spalte
connected_state_descdie FehlermeldungAn error occurred while receiving data: '24(The program issued a command but the command length is incorrect)'angezeigt wird, führen Sie den folgenden Befehl aus, um den Fehler zu beheben::Connect CLUSTER-SQL1 IF SUSER_ID('DBENG\CLUSTER-SQL2$') IS NULL CREATE LOGIN [DBENG\CLUSTER-SQL2$] FROM WINDOWS GO GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [DBENG\CLUSTER-SQL2$] GO :Connect CLUSTER-SQL2 IF SUSER_ID('DBENG\CLUSTER-SQL1$') IS NULL CREATE LOGIN [DBENG\CLUSTER-SQL1$] FROM WINDOWS GO GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [DBENG\CLUSTER-SQL1$] GOFühren Sie die vorherige Abfrage noch einmal aus, um sicherzustellen, dass der Synchronisierungsfehler nicht mehr auftritt. Möglicherweise müssen Sie einige Minuten warten, bis der Fehler behoben ist. Wenn der Fehler weiterhin auftritt, lesen Sie die Informationen unter Fehlerbehebung bei der Konfiguration von Always On-Verfügbarkeitsgruppen (SQL Server).
Schließen Sie die Einrichtung der Verfügbarkeitsgruppe ab:
:Connect CLUSTER-SQL2 ALTER DATABASE [TestDB] SET HADR AVAILABILITY GROUP = [cluster-ag] GO ALTER DATABASE [TestDB] SET HADR RESUME; GOÜberprüfen Sie, ob die Verfügbarkeitsgruppe synchronisiert wird:
Klicken Sie in SQL Server Management Studio unter Always On-Hochverfügbarkeit > Verfügbarkeitsgruppen mit der rechten Maustaste auf die Verfügbarkeitsgruppe und wählen Sie dann Dashboard anzeigen aus.
Überprüfen, ob der primäre Synchronisierungsstatus Synchronisiert und der sekundäre Synchronisierungsstatus Synchronisieren ist, wie im folgenden Screenshot zu sehen:

Wenn Sie einen Listener hinzufügen möchten, klicken Sie unter Always On-Hochverfügbarkeit > Verfügbarkeitsgruppen >
cluster-ag (Primary)> Verfügbarkeitsgruppen-Listener mit der rechten Maustaste auf den Namen der Verfügbarkeitsgruppe und wählen Sie Listener Hinzufügen:Geben Sie im Dialogfeld Neuer Listener für Verfügbarkeitsgruppe die folgenden Parameter für den Listener an:
- Listener DNS Name (Listener-DNS-Name):
ag-listener - Port:
1433 - Netzwerkmodus:
Static IP
- Listener DNS Name (Listener-DNS-Name):
Fügen Sie zwei Subnetz- und IP-Adressfelder hinzu. In diesem Beispiel verwenden Sie die folgenden Subnetz- und IP-Adresspaare. Diese Paare sind die IP-Adressen, die Sie zusätzlich zur primären IP-Adresse auf den VMs der SQL-Dienstinstanz erstellt haben:
- Geben Sie für das erste Paar folgende Werte ein:
- Subnetz:
192.168.1.0/24 - IPv4-Adresse:
192.168.1.6
- Subnetz:
- Geben Sie für das zweite Paar folgende Werte ein:
- Subnetz:
10.1.1.0/24 - IPv4-Adresse:
10.1.1.6
- Subnetz:
- Geben Sie für das erste Paar folgende Werte ein:
Wenn Sie alle Subnetz- und IP-Adresspaare hinzugefügt haben, klicken Sie auf OK.
Stellen Sie eine Verbindung zu SQL Server her und verwenden Sie
ag-listener.dbeng.comals Namen für die SQL Server-Datenbank anstelle des Namens der Instanzen. Diese Verbindung verweist auf die aktuell aktive Instanz.- Klicken Sie im Objekt-Explorer auf Verbinden und wählen Sie Datenbankmodul aus.
- Geben Sie im Dialogfeld Mit Server verbinden im Feld Servername den Namen des Listeners
ag-listener.dbeng.comein. Klicken Sie nach dem Hinzufügen des Servernamens auf Verbinden. Die neue Verbindung wird im Objekt-Explorer gezeigt wie im folgenden Screenshot gezeigt:
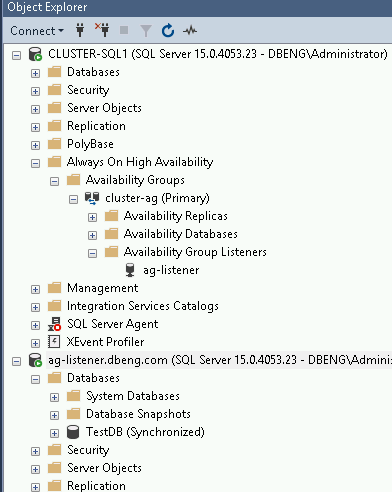
Wenn Sie über RDP mit
cluster-sql2verbunden sind, können Sie diesen Schritt optional wiederholen, um die Verbindung herzustellen.
Testdaten hinzufügen
In diesem Abschnitt fügen Sie der TestDB-Datenbank in cluster-sql1 eine Testtabelle und einige Testdaten hinzu und überprüfen dann die Datenreplikation.
Erstellen Sie in
cluster-sql1eine Tabelle mit dem NamenPersons::Connect CLUSTER-SQL1 USE TestDB; CREATE TABLE Persons ( PersonID int, LastName varchar(255), FirstName varchar(255), PRIMARY KEY (PersonID) );Fügen Sie einige Zeilen hinzu:
:Connect CLUSTER-SQL1 USE TestDB; INSERT INTO Persons (PersonId, LastName, FirstName) VALUES (1, 'Velasquez', 'Ava'); INSERT INTO Persons (PersonId, LastName, FirstName) VALUES (2, 'Delaxcrux', 'Paige');Wenn Sie die Enterprise Edition verwenden, aktivieren Sie den Lesezugriff auf das Lesereplikat (
cluster-sql2), damit Sie überprüfen können, ob die Replikation stattfindet. Die Standard Edition unterstützt keinen Lesezugriff auf das Lesereplikat. Wenn Sie die Standard Edition verwenden, fahren Sie mit dem nächsten Abschnitt fort, um die Umstellung auf Google Cloud auszuführen.:Connect CLUSTER-SQL1 ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON N'CLUSTER-SQL2' WITH (SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL)) GOFragen Sie in der Enterprise Edition die Tabelle in
cluster-sql2ab, um zu prüfen, ob der Tabelleninhalt repliziert wurde::Connect CLUSTER-SQL2 SELECT * FROM TestDB.dbo.Persons;
Nachdem nun die Daten aus cluster-sql1 in cluster-sql2 repliziert wurden, führen Sie die Umstellung aus. Wenn Sie nur die Replikation ausführen möchten, können Sie die folgenden Abschnitte überspringen und nicht die Umstellung oder den Fallback ausführen. Wenn Sie die Ressourcen, die Sie zur Replikation verwendet haben, nicht behalten möchten, können Sie Kosten vermeiden. Führen Sie dazu die Schritte zur Bereinigung am Ende dieser Anleitung aus.
Umstellung auf Google Cloud ausführen
Für ein konsistentes Dataset muss jeder Client, der in cluster-sql1 schreibt, angehalten werden, damit alle Daten vor der Umstellung in cluster-sql2 repliziert werden können.
Um Konsistenz zu gewährleisten, müssen alle Daten vollständig repliziert werden. In diesem Abschnitt können Sie eine vollständige Datenreplikation erreichen, wenn Sie den Verfügbarkeitsmodus in SYNCHRONOUS_COMMIT ändern. Diese Änderung gewährleistet eine vollständige Replikation von cluster-sql1 in cluster-sql2.
Führen Sie den folgenden SQL-Befehl in
cluster-sql1aus, um den Verfügbarkeitsmodus beider Knoten für den synchronen Commit zu ändern. Nur indem Sie beide Knoten auf synchronen Commit setzen, können Sie verhindern, dass Daten verloren gehen.:Connect CLUSTER-SQL1 ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON N'CLUSTER-SQL1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON N'CLUSTER-SQL2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT) GOCluster-sql2kann jetzt zum primären Knoten werden. Stellen Sie eine Verbindung zucluster-sql2her und legen Sie es als primären Knoten fest::Connect CLUSTER-SQL2 ALTER AVAILABILITY GROUP [cluster-ag] FAILOVER; GOÄndern Sie den Verfügbarkeitsmodus in beiden Knoten in asynchronen Commit. Da
cluster-sql2der primäre Knoten ist, führen Sie incluster-sql2die folgenden SQL-Befehle aus::Connect CLUSTER-SQL2 ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON N'CLUSTER-SQL1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GO ALTER AVAILABILITY GROUP [cluster-ag] MODIFY REPLICA ON N'CLUSTER-SQL2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT) GOSie können jetzt
cluster-sql2als Hauptknoten für die Anwendungen verwenden.cluster-sql1ist die sekundäre Instanz, die asynchron repliziert wird.Da
cluster-sql2jetzt der primäre Knoten ist, fragen Sie die Tabelle incluster-sql2ab, um zu prüfen, ob der Tabelleninhalt repliziert wurde::Connect CLUSTER-SQL2 SELECT * FROM TestDB.dbo.Persons;Die Ausgabe entspricht den Testdaten, die Sie zuvor in dieser Anleitung in die Tabelle eingefügt haben.
Für eine weitere Replikationsprüfung können Sie eine neue Tabelle erstellen und eine einzelne Zeile auf dem neuen primären Knoten einfügen. Wenn die Tabelle und ihre Zeile auf dem sekundären Knoten angezeigt werden, wissen Sie, dass die Replikation funktioniert.
Fallback
Manchmal müssen Sie vom neuen primären Knoten zum ursprünglichen primären Knoten zurückwechseln. Wenn Sie dem Abschnitt Umstellung auf Google Cloud früher in dieser Anleitung gefolgt sind, haben Sie den vorherigen primären Knoten (cluster-sql1) zum sekundären Knoten des neuen primären Knotens (cluster-sql2) gemacht.
Führen Sie zum Abschließen eines Fallbacks die Schritte zum Ausführen der Umstellung auf Google Cloud aus und ersetzen Sie die folgenden Werte:
- Ersetzen Sie den ursprünglichen primären Knoten (
cluster-sql1) durch den neuen primären Knoten (cluster-sql2). - Ersetzen Sie den ursprünglichen sekundären Knoten (
cluster-sql2) durch den neuen sekundären Knoten (cluster-sql1).
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
So vermeiden Sie, dass Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen in Rechnung gestellt werden:
Projekt in Google Cloud löschen
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
Projekt in AWS löschen
Da Sie in AWS Ressourcen erstellt und verwendet haben, fallen weiterhin Kosten an. Damit keine weiteren Kosten anfallen, sollten Sie diese Ressourcen in AWS löschen.
Nächste Schritte
- Dokumentation und Lösungen für SQL Server ansehen.
- Referenzarchitekturen, Diagramme und Best Practices zu Google Cloud kennenlernen. Weitere Informationen zu Cloud Architecture Center