
Dokumen di bagian Framework Arsitektur Google Cloud: Keandalan ini memberikan detail tentang pemberitahuan terkait SLO.
Pendekatan yang keliru untuk memperkenalkan sistem kemampuan observasi baru seperti SLO adalah dengan menggunakan sistem tersebut untuk sepenuhnya mengganti sistem sebelumnya. Sebaliknya, Anda akan melihat SLO sebagai sistem pelengkap. Misalnya, daripada menghapus pemberitahuan yang sudah ada, sebaiknya jalankan pemberitahuan tersebut secara paralel dengan pemberitahuan SLO yang diperkenalkan di sini. Dengan pendekatan ini, Anda dapat menemukan pemberitahuan lama mana yang bersifat prediktif dari pemberitahuan SLO, yang diaktifkan secara paralel dengan pemberitahuan SLO Anda, dan pemberitahuan mana yang tidak pernah diaktifkan.
Prinsip SRE adalah memberi tahu berdasarkan gejala, bukan penyebab. SLO, pada dasarnya adalah pengukuran gejala. Saat mengadopsi pemberitahuan SLO, Anda mungkin menemukan bahwa pemberitahuan gejala diaktifkan bersama pemberitahuan lainnya. Jika Anda menemukan bahwa pemberitahuan berbasis penyebab yang lama diaktifkan tanpa SLO atau gejala, hal ini sebaiknya dinonaktifkan sepenuhnya, diubah menjadi pemberitahuan tiket, atau dicatat dalam log untuk referensi di lain waktu.
Untuk informasi selengkapnya, lihat Workbook SRE, Bab 5.
Laju pengeluaran SLO
Laju pengeluaran SLO adalah pengukuran seberapa cepat pemadaman layanan mengekspos pengguna terhadap error dan menghabiskan anggaran error. Dengan mengukur laju pengeluaran, Anda dapat menentukan waktu hingga layanan melanggar SLO-nya. Pemberitahuan berdasarkan laju pengeluaran SLO adalah pendekatan yang berharga. Ingat bahwa SLO Anda didasarkan pada durasi, yang mungkin cukup lama (minggu atau bahkan bulan). Namun, tujuannya adalah untuk dengan cepat mendeteksi kondisi yang menyebabkan pelanggaran SLO sebelum pelanggaran tersebut benar-benar terjadi.
Tabel berikut menunjukkan waktu yang diperlukan untuk melampaui tujuan jika 100% permintaan gagal pada interval tertentu, dengan asumsi kueri per detik (QPS) adalah konstan. Misalnya, jika Anda memiliki SLO 99,9% yang diukur selama 30 hari, Anda dapat menahan 43,2 menit periode nonaktif penuh selama 30 hari tersebut. Misalnya, periode nonaktif dapat terjadi sekaligus, atau memerlukan beberapa insiden.
| Tujuan | 90 hari | 30 hari | 7 hari | 1 hari |
|---|---|---|---|---|
| 90% | 9 hari | 3 hari | 16,8 jam | 2,4 jam |
| 99% | 21,6 jam | 7,2 jam | 1,7 jam | 14,4 menit |
| 99,9% | 2,2 jam | 43,2 menit | 10,1 menit | 1,4 menit |
| 99,99% | 13 menit | 4,3 menit | 1 menit | 8,6 detik |
| 99,999% | 1,3 menit | 25,9 detik | 6 detik | 0,9 detik |
Dalam praktiknya, Anda tidak dapat membeli insiden pemadaman 100% jika ingin mencapai persentase keberhasilan yang tinggi. Namun, banyak sistem terdistribusi yang dapat mengalami kegagalan atau menurun dengan baik. Di kasus semacam itu, Anda tetap perlu mengetahui apakah manusia perlu turun tangan, bahkan dalam kegagalan parsial. Pemberitahuan SLO memberi Anda cara untuk menentukannya.
Kapan harus memberi tahu
Pertanyaan penting adalah kapan harus bertindak berdasarkan laju pengeluaran SLO Anda. Biasanya, jika anggaran error Anda habis dalam waktu 24 jam, waktunya untuk meminta seseorang memperbaiki masalahnya sekarang.
Mengukur tingkat kegagalan tidak selalu mudah. Serangkaian error kecil mungkin terlihat mengerikan pada saat itu, tetapi ternyata hanya berlangsung sebentar dan memiliki dampak yang tidak penting pada SLO Anda. Demikian pula, jika sistem sedikit rusak dalam waktu yang lama, error ini dapat menyebabkan pelanggaran SLO.
Idealnya, tim Anda akan bereaksi terhadap sinyal ini sehingga Anda menghabiskan hampir semua anggaran error (tetapi tidak melebihinya) selama jangka waktu tertentu. Jika Anda membelanjakan terlalu banyak, Anda dapat melanggar SLO Anda. Jika pembelanjaan terlalu sedikit, Anda tidak mengambil risiko yang cukup atau mungkin akan menguras tenaga tim Anda.
Anda memerlukan cara untuk menentukan kapan sistem mengalami kerusakan yang cukup sehingga perlu intervensi oleh manusia. Bagian berikut membahas beberapa pendekatan terhadap pertanyaan tersebut.
Pengeluaran cepat
Salah satu jenis pengeluaran SLO adalah fast SLO burn karena menghabiskan anggaran error Anda dengan cepat dan menuntut Anda untuk campur tangan untuk menghindari pelanggaran SLO.
Misalnya layanan Anda beroperasi secara normal pada 1.000 kueri per detik (QPS), dan Anda ingin mempertahankan ketersediaan 99% seperti yang diukur selama tujuh hari seminggu. Anggaran error Anda adalah sekitar 6 juta error yang diizinkan (dari sekitar 600 juta permintaan). Misalnya, jika Anda memiliki waktu 24 jam sebelum anggaran error habis, batas tersebut dibatasi sekitar 70 error per detik atau 252.000 error dalam satu jam. Parameter ini didasarkan pada aturan umum bahwa insiden yang dapat di-pageable harus memakai setidaknya 1% dari anggaran error triwulanan.
Anda dapat memilih untuk mendeteksi tingkat error ini sebelum satu jam berlalu. Misalnya, setelah mengamati rasio 70 error per detik selama 15 menit, Anda dapat memutuskan untuk memanggil teknisi panggilan, seperti yang ditunjukkan dalam diagram berikut.
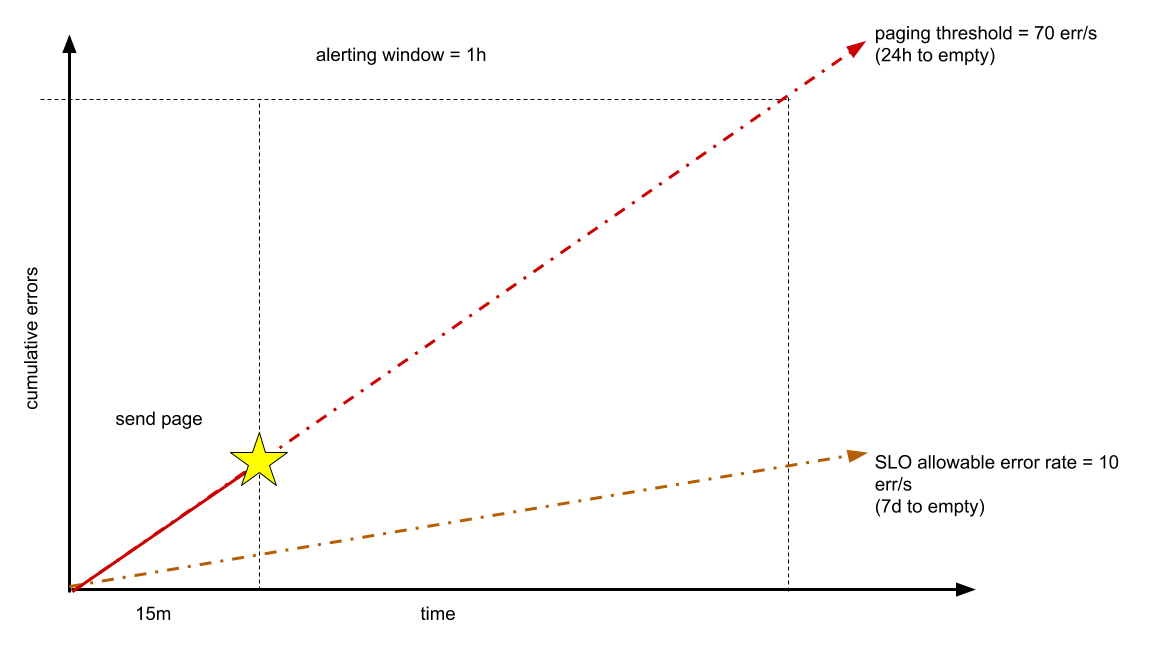
Idealnya, masalah akan diselesaikan sebelum Anda menghabiskan satu jam dari anggaran 24 jam Anda. Memilih untuk mendeteksi rasio ini dalam periode yang lebih singkat (misalnya, satu menit) cenderung terlalu rentan terhadap error. Jika waktu deteksi target Anda kurang dari 15 menit, jumlah ini dapat disesuaikan.
Pengeluaran lambat
Jenis laju pengeluaran lainnya adalah pengeluaran lambat. Misalkan Anda memperkenalkan bug yang memakan anggaran error mingguan pada hari kelima atau keenam, atau anggaran bulanan pada minggu kedua? Apa respons terbaik Anda?
Dalam hal ini, Anda mungkin memperkenalkan pemberitahuan slow SLO burn yang memungkinkan Anda mengetahui bahwa Anda akan menghabiskan seluruh anggaran error sebelum periode pemberitahuan berakhir. Tentu saja, pemberitahuan tersebut mungkin menampilkan banyak positif palsu (PP). Misalnya, mungkin sering ada kondisi ketika error terjadi sebentar, tetapi pada tingkat yang cepat menghabiskan anggaran error Anda. Dalam kasus ini, kondisinya adalah positif palsu (PP) karena hanya berlangsung dalam waktu singkat dan tidak mengancam anggaran error Anda dalam jangka panjang. Ingat, tujuannya bukan untuk menghilangkan semua sumber kesalahan; tetap dalam rentang yang dapat diterima agar tidak melebihi anggaran error. Sebaiknya hindari mengingatkan manusia untuk mengintervensi peristiwa yang tidak secara sah mengancam anggaran error Anda.
Sebaiknya beri tahu antrean tiket (bukan paging atau pengiriman email) untuk peristiwa pengeluaran lambat. Peristiwa pengeluaran lambat bukanlah keadaan darurat, tetapi memerlukan perhatian manusia sebelum anggaran berakhir. Pemberitahuan ini tidak boleh berupa email ke daftar tim, yang dengan cepat menjadi mengganggu jika diabaikan. Tiket harus dapat dilacak, ditetapkan, dan ditransfer. Tim harus mengembangkan laporan untuk muatan tiket, tingkat penutupan, kemampuan untuk ditindaklanjuti, dan duplikat. Tiket yang berlebihan dan tidak dapat ditindaklanjuti adalah contoh toil yang bagus.
Penggunaan pemberitahuan SLO secara tepat dapat memerlukan waktu dan bergantung pada budaya dan ekspektasi tim Anda. Ingatlah bahwa Anda dapat menyesuaikan pemberitahuan SLO dari waktu ke waktu. Anda juga dapat memiliki beberapa metode pemberitahuan, dengan berbagai jendela pemberitahuan, bergantung pada kebutuhan Anda.
Pemberitahuan latensi
Selain pemberitahuan ketersediaan, Anda juga dapat memiliki pemberitahuan latensi. Dengan SLO latensi, Anda mengukur persentase permintaan yang tidak memenuhi target latensi. Dengan model ini, Anda dapat menggunakan model pemberitahuan yang sama dengan yang digunakan untuk mendeteksi pengeluaran anggaran error yang cepat atau lambat.
Seperti yang disebutkan sebelumnya tentang SLO latensi median, sepenuhnya setengah permintaan Anda dapat keluar dari SLO. Dengan kata lain, pengguna dapat mengalami latensi buruk selama berhari-hari sebelum Anda mendeteksi dampaknya pada anggaran error jangka panjang. Sebagai gantinya, layanan harus menentukan tujuan latensi tail dan tujuan latensi standar. Sebaiknya gunakan persentil ke-90 historis untuk menentukan persentil ke-99 standar dan ke-99 untuk tail. Setelah menetapkan target ini, Anda dapat menentukan SLO berdasarkan jumlah permintaan yang Anda harapkan untuk diterima di setiap kategori latensi dan berapa banyak permintaan yang terlalu lambat. Pendekatan ini adalah konsep yang sama dengan anggaran error dan harus diperlakukan sama. Dengan demikian, Anda mungkin akan mendapatkan pernyataan seperti "90% permintaan akan ditangani dalam latensi standar dan 99,9% dalam target latensi tail". Target ini memastikan sebagian besar pengguna mengalami latensi standar dan tetap memungkinkan Anda melacak jumlah permintaan yang lebih lambat dari target latensi tail.
Beberapa layanan mungkin memiliki runtime yang diharapkan memiliki varian yang sangat tinggi. Misalnya, Anda mungkin memiliki ekspektasi performa yang sangat berbeda untuk membaca dari sistem datastore dibandingkan dengan menulis ke sistem. Daripada menghitung setiap kemungkinan harapan, Anda dapat memperkenalkan bucket performa runtime, seperti yang ditampilkan dalam tabel berikut. Pendekatan ini menganggap bahwa jenis permintaan ini dapat diidentifikasi dan telah dikategorikan ke dalam setiap bucket. Anda tidak boleh mengategorikan permintaan dengan cepat.
| Situs yang ditampilkan kepada pengguna | |
|---|---|
| Bucket | Runtime maksimum yang diharapkan |
| Melihat | 1 detik |
| Tulis / perbarui | 3 detik |
| Sistem pemrosesan data | |
|---|---|
| Bucket | Runtime maksimum yang diharapkan |
| Kecil | 10 detik |
| Sedang | 1 menit |
| Besar | 5 menit |
| Paling Besar | 1 jam |
| Super Besar | 8 jam |
Dengan mengukur sistem seperti saat ini, Anda dapat memahami berapa lama waktu biasanya untuk menjalankan permintaan ini. Sebagai contoh, pertimbangkan sistem untuk memproses upload video. Jika video berdurasi sangat panjang, waktu pemrosesannya diperkirakan akan memakan waktu lebih lama. Kita dapat menggunakan durasi video dalam hitungan detik untuk mengategorikan pekerjaan ini ke dalam bucket, seperti yang ditampilkan dalam tabel berikut. Tabel ini mencatat jumlah permintaan per bucket serta berbagai persentil untuk distribusi runtime selama seminggu.
| Durasi video | Jumlah permintaan yang diukur dalam satu minggu | 10% | 90% | 99,95% |
|---|---|---|---|---|
| Kecil | 0 | - | - | - |
| Sedang | 1.9 juta | 864 milidetik | 17 detik | 86 detik |
| Besar | 25 juta | 1.8 detik | 52 detik | 9.6 menit |
| Paling Besar | 4.3 juta | 2 detik | 43 detik | 23.8 menit |
| Super Besar | 81,000 | 36 detik | 1.2 menit | 41 menit |
Dari analisis tersebut, Anda dapat memperoleh beberapa parameter untuk pemberitahuan:
- fast_typical: Maksimal 10% permintaan lebih cepat dari saat ini. Jika terlalu banyak permintaan yang lebih cepat dari waktu ini, target Anda mungkin salah, atau sesuatu tentang sistem Anda mungkin telah berubah.
- slow_typical: Setidaknya 90% permintaan lebih cepat dari saat ini. Batas ini mendorong SLO latensi utama Anda. Parameter ini menunjukkan apakah sebagian besar permintaan cukup cepat.
- slow_tail: Setidaknya 99,95% permintaan lebih cepat dari saat ini. Batas ini memastikan bahwa tidak ada terlalu banyak permintaan lambat.
- deadline: Titik saat waktu pemrosesan RPC pengguna atau latar belakang habis dan gagal (batas yang biasanya sudah di-hard code ke dalam sistem). Permintaan ini sebenarnya tidak akan lambat tetapi sebenarnya akan gagal dengan error dan sebagai gantinya dihitung terhadap SLO ketersediaan Anda.
Pedoman dalam menentukan bucket adalah menjaga bucket fast_typical, slow_typical, dan slow_tail dalam urutan magnitudo satu sama lain. Panduan ini memastikan Anda tidak memiliki bucket yang terlalu luas. Sebaiknya Anda tidak mencoba mencegah tumpang-tindih atau celah di antara bucket.
| Bucket | fast_typical | slow_typical | slow_tail | deadline |
|---|---|---|---|---|
| Kecil | 100 milidetik | 1 detik | 10 detik | 30 seconds |
| Sedang | 600 milidetik | 6 detik | 60 detik (1 menit) | 300 detik |
| Besar | 3 detik | 30 seconds | 300 detik (5 menit) | 10 menit |
| Paling Besar | 30 seconds | 6 menit | 60 menit (1 jam) | 3 jam |
| Super Besar | 5 menit | 50 menit | 500 menit (8 jam) | 12 jam |
Tindakan ini menghasilkan aturan seperti api.method: SMALL => [1s, 10s].
Dalam hal ini, sistem pelacakan SLO akan melihat permintaan, menentukan bucket-nya (mungkin dengan menganalisis nama metode atau URI-nya dan membandingkan namanya dengan tabel pencarian), lalu memperbarui statistik berdasarkan runtime permintaan tersebut. Jika perlu waktu 700 milidetik, berarti proses ini berada dalam target slow_typical. Jika 3
detik, ID ini berada dalam slow_tail. Jika berdurasi 22 detik, berarti melebihi
slow_tail, tetapi belum menjadi error.
Dalam hal kepuasan pengguna, Anda dapat menganggap latensi tail yang hilang sebagai hal yang sama dengan tidak tersedia. (Artinya, responsnya sangat lambat sehingga harus dianggap sebagai kegagalan.) Oleh karena itu, sebaiknya gunakan persentase yang sama dengan yang Anda gunakan untuk ketersediaan, misalnya:
Apa yang Anda anggap sebagai latensi standar adalah terserah Anda. Beberapa tim di Google menganggap 90% sebagai target yang baik. Hal ini terkait dengan analisis Anda dan cara Anda memilih durasi untuk slow_typical. Contoh:
Pemberitahuan yang disarankan
Dengan panduan ini, tabel berikut menyertakan kumpulan dasar pemberitahuan SLO yang disarankan.
| SLO | Periode pengukuran | Laju pengeluaran | Tindakan |
|---|---|---|---|
|
Ketersediaan, pengeluaran cepat Latensi umum Latensi tail |
Periode 1 jam | Kurang dari 24 jam menuju pelanggaran SLO | Halaman seseorang |
|
Ketersediaan, pengeluaran lambat Latensi umum, pengeluaran lambat Latensi akhir, pengeluaran lambat |
Periode 7 hari | Lebih dari 24 jam menuju pelanggaran SLO | Buat tiket |
Pemberitahuan SLO adalah keterampilan yang memerlukan waktu untuk dikembangkan. Durasi di bagian ini adalah saran; Anda dapat menyesuaikannya dengan kebutuhan dan tingkat presisi. Memasukkan pemberitahuan ke periode pengukuran atau pengeluaran anggaran error mungkin akan membantu, atau Anda dapat menambahkan lapisan pemberitahuan lain antara proses pengeluaran cepat dan pengeluaran lambat.