
Untuk memastikan bahwa kasus penggunaan konsumen data terpenuhi, produk data dalam mesh data harus didesain dan dibangun dengan hati-hati. Desain produk data dimulai dengan definisi cara konsumen data akan menggunakan produk tersebut, dan cara produk tersebut kemudian diekspos kepada konsumen. Produk data dalam mesh data dibangun di atas penyimpanan data (misalnya, data warehouse domain atau data lake). Saat membuat produk data dalam mesh data, ada beberapa faktor utama yang sebaiknya Anda pertimbangkan selama proses ini. Pertimbangan ini dijelaskan dalam dokumen ini.
Dokumen ini merupakan bagian dari rangkaian yang menjelaskan cara menerapkan mesh data di Google Cloud. Dokumen ini mengasumsikan bahwa Anda telah membaca dan memahami konsep yang dideskripsikan dalam Arsitektur dan fungsi dalam mesh data dan Membuat Mesh Data terdistribusi dan modern menggunakan Google Cloud.
Seri ini memiliki bagian-bagian sebagai berikut:
- Arsitektur dan fungsi dalam mesh data
- Mendesain platform data layanan mandiri untuk mesh data
- Membangun produk data dalam mesh data (dokumen ini)
- Menemukan dan menggunakan produk data dalam mesh data
Saat membuat produk data dari data warehouse domain, sebaiknya produser data mendesain antarmuka analisis (konsumsi) dengan cermat untuk produk tersebut. Antarmuka konsumsi ini merupakan serangkaian jaminan untuk parameter kualitas data dan operasional, beserta model dukungan dan dokumentasi produk. Biaya perubahan antarmuka konsumsi biasanya tinggi karena produser data dan kemungkinan beberapa konsumen data perlu mengubah proses dan aplikasi yang mereka gunakan. Mengingat konsumen data kemungkinan besar berada di unit organisasi yang terpisah dengan produser data, mengoordinasi perubahan dapat menjadi sulit.
Bagian berikut memberikan informasi latar belakang tentang hal yang harus Anda pertimbangkan saat membuat warehouse domain, menentukan antarmuka konsumsi, dan mengekspos antarmuka tersebut ke konsumen data.
Membuat data warehouse domain
Tidak ada perbedaan mendasar antara membangun data warehouse mandiri dan membangun data warehouse domain yang menjadi tempat tim produser data membuat produk data. Satu-satunya perbedaan nyata antara keduanya adalah bahwa membangun data warehouse domain mengekspos subset datanya melalui antarmuka konsumsi.
Dalam banyak data warehouse, data mentah yang diserap dari sumber data operasional melewati proses pengayaan dan verifikasi kualitas data (seleksi). Dalam data lake yang dikelola Dataplex, data pilihan biasanya disimpan di zona pilihan yang sudah ditetapkan. Saat seleksi selesai, subset data harus siap untuk konsumsi eksternal ke domain melalui beberapa jenis antarmuka. Untuk menentukan antarmuka konsumsi tersebut, organisasi harus menyediakan serangkaian alat untuk tim domain yang baru mengadopsi pendekatan mesh data. Alat ini memungkinkan produser data membuat produk data baru secara mandiri. Untuk mengetahui praktik yang direkomendasikan, lihat Mendesain platform data layanan mandiri.
Selain itu, produk data harus memenuhi persyaratan tata kelola data yang ditetapkan secara terpusat. Persyaratan ini memengaruhi kualitas data, ketersediaan data, dan pengelolaan siklus proses. Karena persyaratan ini membangun kepercayaan konsumen data pada produk data dan mendorong penggunaannya, manfaat penerapan persyaratan ini sepadan dengan upaya dalam mendukungnya.
Menentukan antarmuka konsumsi
Sebaiknya produser data menggunakan beberapa jenis antarmuka, bukan hanya menentukan satu atau dua antarmuka. Setiap jenis antarmuka dalam analisis data memiliki keunggulan dan kekurangan, dan tidak ada satu jenis antarmuka yang unggul dalam semuanya. Saat produser data menilai kesesuaian setiap jenis antarmuka, mereka harus mempertimbangkan hal berikut:
- Kemampuan untuk menjalankan pemrosesan data yang diperlukan.
- Skalabilitas untuk mendukung kasus penggunaan konsumen data saat ini dan di masa mendatang.
- Performa yang diperlukan oleh konsumen data.
- Biaya pengembangan dan pemeliharaan.
- Biaya menjalankan antarmuka.
- Dukungan oleh bahasa dan alat yang digunakan organisasi Anda.
- Dukungan untuk penyimpanan dan komputasi yang terpisah.
Misalnya, jika persyaratan bisnis adalah dapat menjalankan kueri analisis pada set data berukuran petabyte, satu-satunya antarmuka praktis adalah tampilan BigQuery. Namun, jika persyaratannya adalah menyediakan data streaming mendekati real-time, antarmuka berdasarkan Pub/Sub lebih sesuai.
Banyak dari antarmuka ini tidak mengharuskan Anda menyalin atau mereplikasi data yang ada. Sebagian besarnya juga memungkinkan Anda memisahkan penyimpanan dan komputasi yang merupakan fitur penting dari alat analisis Google Cloud. Konsumen data yang terekspos melalui antarmuka ini memproses data menggunakan resource komputasi yang tersedia untuk mereka. Produser data tidak perlu melakukan penyediaan infrastruktur tambahan.
Ada berbagai macam antarmuka konsumsi. Antarmuka berikut adalah yang paling umum digunakan dalam mesh data dan dibahas di bagian berikut:
- Tampilan dan fungsi yang diotorisasi
- API baca langsung
- Data sebagai aliran
- API akses data
- Looker blocks
- Model machine learning (ML)
Daftar antarmuka dalam dokumen ini tidak lengkap. Ada juga opsi lain yang dapat Anda pertimbangkan untuk antarmuka konsumsi Anda (misalnya, Analytics Hub). Namun, antarmuka lain tersebut berada di luar cakupan dokumen ini.
Tampilan dan fungsi yang diotorisasi
Sebanyak mungkin, produk data harus diekspos melalui tampilan yang diotorisasi dan fungsi yang diotorisasi, termasuk fungsi bernilai tabel. Set data yang diotorisasi menyediakan cara yang mudah untuk mengizinkan beberapa tampilan secara otomatis. Menggunakan tampilan yang diberi diotorisasi akan mencegah akses langsung ke tabel dasar, dan memungkinkan Anda mengoptimalkan tabel dan kueri dasar terhadap tabel tersebut, tanpa memengaruhi penggunaan tampilan tersebut oleh konsumen. Konsumen antarmuka ini menggunakan SQL untuk membuat kueri data. Diagram berikut mengilustrasikan penggunaan set data yang diotorisasi sebagai antarmuka konsumsi.
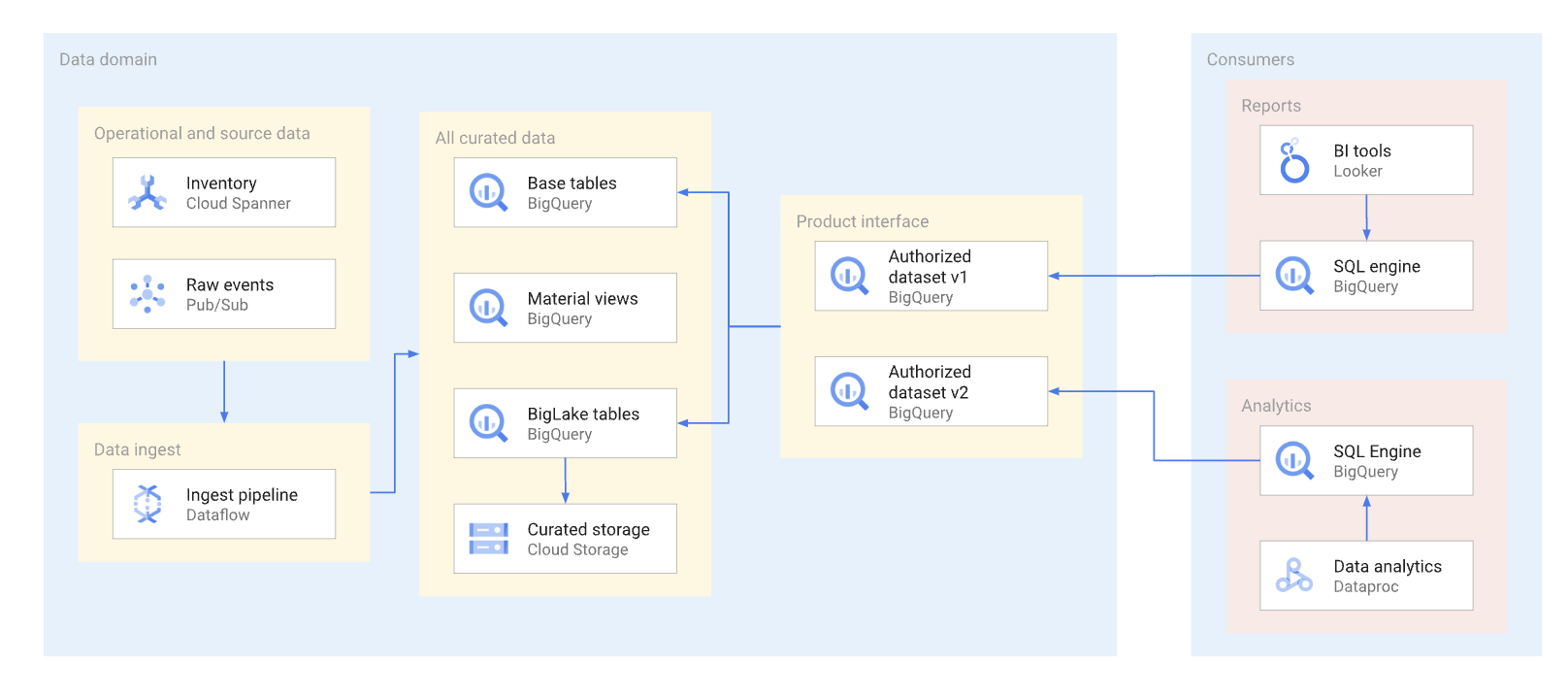
Set data dan tampilan yang diotorisasi membantu memudahkan pembuatan versi antarmuka. Seperti yang ditunjukkan dalam diagram berikut, ada dua pendekatan pembuatan versi utama yang dapat dilakukan produser data:

Pendekatan-pendekatan tersebut dapat dirangkum sebagai berikut:
- Pembuatan versi set data: Dalam pendekatan ini, Anda akan membuat versi nama set data.
Anda tidak membuat versi tampilan dan fungsi di dalam set data. Anda mempertahankan
nama yang sama untuk tampilan dan fungsi, apa pun versinya. Misalnya,
versi pertama set data penjualan ditentukan dalam set data bernama
sales_v1dengan dua tampilan,catalogdanorders. Untuk versi keduanya, set data penjualan telah diganti namanya menjadisales_v2, dan tampilan sebelumnya dalam set data mempertahankan nama sebelumnya, tetapi memiliki skema baru. Versi set data kedua mungkin juga memiliki tampilan baru yang ditambahkan ke dalamnya, atau dapat menghapus salah satu tampilan sebelumnya. - Melihat pembuatan versi: Dalam pendekatan ini, tampilan di dalam set data
memiliki versi, bukan set data itu sendiri. Contohnya, set data penjualan menyimpan nama
sales, apa pun versinya. Namun, nama tabel virtual di dalam set data berubah untuk mencerminkan setiap versi baru tabel virtual (seperticatalog_v1,catalog_v2,orders_v1,orders_v2, danorders_v3).
Pendekatan pembuatan versi terbaik untuk organisasi Anda bergantung pada kebijakan organisasi dan jumlah tabel virtual yang dirender dan tidak digunakan lagi dengan update pada data pokok. Pembuatan versi set data sangat baik saat update produk utama diperlukan dan sebagian besar tabel virtual harus berubah. Pembuatan versi tampilan menyebabkan lebih sedikit tabel virtual yang bernama identik di set data yang berbeda, tetapi dapat mengarah pada ambiguitas, contohnya, cara mengetahui apakah penggabungan antar-set data berfungsi dengan benar. Pendekatan hybrid bisa menjadi kompromi yang baik. Dalam pendekatan hybrid, perubahan skema yang kompatibel diizinkan dalam satu set data, dan perubahan yang tidak kompatibel memerlukan set data baru.
Pertimbangan tabel BigLake
Tabel virtual yang diotorisasi tidak hanya dapat dibuat di tabel BigQuery, tetapi juga di tabel BigLake. Tabel BigLake dapat digunakan konsumen untuk mengkueri data yang tersimpan di Cloud Storage menggunakan antarmuka BigQuery SQL. Tabel BigLake mendukung kontrol akses terperinci tanpa mengharuskan konsumen data memiliki izin baca untuk bucket Cloud Storage yang mendasarinya.
Produsen data harus mempertimbangkan hal berikut untuk tabel BigLake:
- Desain format file dan tata letak data memengaruhi performa kueri. Format berbasis kolom, contohnya, Parquet atau ORC, umumnya berperforma jauh lebih baik untuk kueri analisis daripada format JSON atau CSV
- Tata letak berpartisi Hive memungkinkan Anda memangkas partisi dan mempercepat kueri yang menggunakan kolom partisi.
- Jumlah file dan performa kueri yang diinginkan untuk ukuran file juga harus diperhitungkan dalam tahap desain.
Jika kueri yang menggunakan tabel BigLake tidak memenuhi persyaratan perjanjian tingkat layanan (SLA) untuk antarmuka dan tidak dapat disesuaikan, sebaiknya lakukan tindakan berikut:
- Untuk data yang harus diekspos kepada konsumen data, konversikan data tersebut ke penyimpanan BigQuery.
- Tentukan ulang tabel virtual yang diotorisasi untuk menggunakan tabel BigQuery.
Umumnya, pendekatan ini tidak menyebabkan gangguan pada konsumen data atau memerlukan perubahan pada kueri mereka. Kueri di penyimpanan BigQuery dapat dioptimalkan menggunakan teknik yang tidak mungkin dilakukan pada tabel BigLake. Contohnya, dengan penyimpanan BigQuery, konsumen dapat membuat kueri tampilan terwujud yang memiliki partisi dan pengelompokan berbeda dari tabel dasar, dan mereka dapat menggunakan BigQuery BI Engine.
API baca langsung
Meskipun umumnya kami tidak merekomendasikan agar produser data memberi konsumen data akses baca langsung ke tabel dasar, terkadang akan lebih praktis untuk mengizinkan akses tersebut karena alasan seperti performa dan biaya. Dalam kasus tersebut, Anda harus ekstra hati-hati untuk memastikan kestabilan skema tabel
Ada dua cara untuk mengakses data secara langsung di warehouse pada umumnya. Produsen data dapat menggunakan BigQuery Storage Read API, atau Cloud Storage JSON atau XML API. Diagram berikut mengilustrasikan dua contoh konsumen yang menggunakan API ini. Satu adalah kasus penggunaan machine learning (ML), dan satunya lagi adalah tugas pemrosesan data.
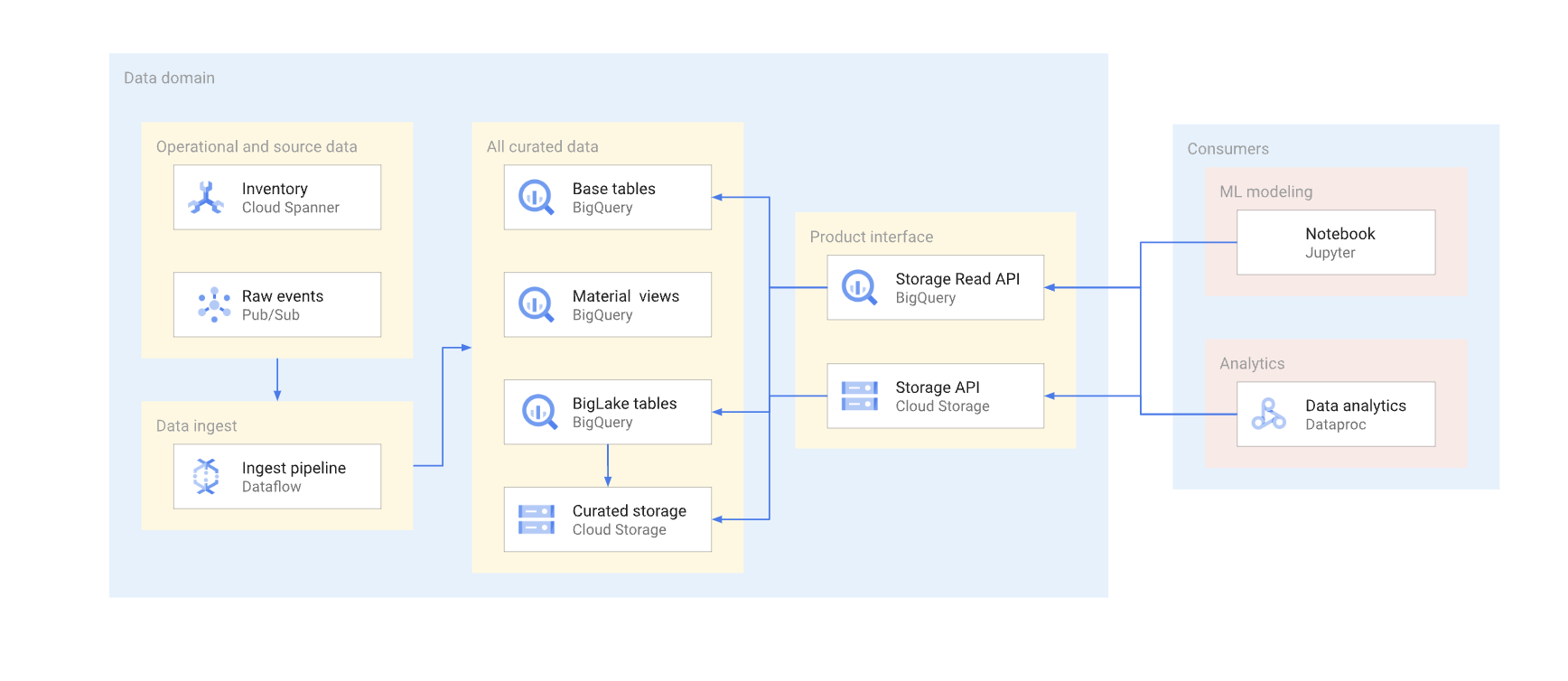
Pembuatan versi antarmuka direct-read merupakan langkah yang kompleks. Biasanya, produser data harus membuat tabel lain dengan skema berbeda. Mereka juga harus mempertahankan dua versi tabel, sampai semua konsumen data dari versi yang tidak digunakan lagi bermigrasi ke versi baru. Jika konsumen dapat menoleransi gangguan pembuatan ulang tabel dan beralih ke skema baru, duplikasi data dapat dihindari. Jika perubahan skema dapat kompatibel dengan versi lama, migrasi tabel dasar dapat dihindari. Contohnya, Anda tidak perlu memigrasikan tabel dasar jika hanya kolom baru yang ditambahkan dan data dalam kolom tersebut diisi ulang untuk semua baris.
Berikut adalah ringkasan perbedaan antara Storage Read API dan Cloud Storage API. Secara umum, jika memungkinkan, sebaiknya pembuat data menggunakan BigQuery API untuk aplikasi analisis.
Storage Read API: Storage Read API dapat digunakan untuk membaca data di tabel BigQuery dan untuk membaca tabel BigLake. API ini mendukung pemfilteran dan kontrol akses yang mendetail serta dapat menjadi opsi yang baik untuk analisis data atau konsumen ML yang stabil.
Cloud Storage API: Produsen data mungkin perlu berbagi bucket Cloud Storage tertentu secara langsung dengan konsumen data. Misalnya, produser data dapat berbagi bucket jika konsumen data tidak dapat menggunakan antarmuka SQL karena alasan tertentu, atau bucket memiliki format data yang tidak didukung oleh Storage Read API.
Secara umum, kami tidak merekomendasikan produser data mengizinkan akses langsung melalui API penyimpanan karena akses langsung tidak memungkinkan pemfilteran dan kontrol akses yang mendetail. Namun, pendekatan akses langsung bisa menjadi pilihan yang tepat untuk set data stabil berukuran kecil (gigabyte).
Mengizinkan Pub/Sub mengakses bucket akan memudahkan konsumen data untuk menyalin data ke dalam project dan memprosesnya di sana. Secara umum, kami tidak merekomendasikan penyalinan data jika dapat dihindari. Beberapa salinan data akan meningkatkan biaya penyimpanan, dan menambah overhead pemeliharaan serta pelacakan silsilah.
Data sebagai aliran
Domain dapat mengekspos data streaming dengan memublikasikan data tersebut ke topik Pub/Sub. Subscriber yang ingin menggunakan data membuat langganan untuk memanfaatkan pesan yang dipublikasikan ke topik tersebut. Setiap subscriber menerima dan menggunakan data secara independen. Diagram berikut menunjukkan contoh aliran data tersebut.

Dalam diagram, penyerapan pipeline membaca peristiwa secara mentah, memperkaya (menyeleksinya), dan menyimpan data hasil seleksi ini ke penyimpanan data analisis (tabel dasar BigQuery). Pada saat yang sama, pipeline memublikasikan peristiwa yang diperkaya ke topik khusus. Topik ini digunakan oleh beberapa subscriber, yang masing-masing berpotensi memfilter peristiwa ini untuk hanya mendapatkan peristiwa yang relevan dengan mereka. Pipeline juga menggabungkan dan memublikasikan acara statistik ke topiknya sendiri untuk diproses oleh konsumen data lain.
Berikut adalah contoh kasus penggunaan langganan Pub/Sub:
- Acara yang diperkaya, seperti memberikan informasi profil lengkap pelanggan bersama dengan data tentang pesanan pelanggan tertentu.
- Notifikasi agregasi yang mendekati real-time, seperti statistik pesanan total selama 15 menit terakhir.
- Pemberitahuan tingkat bisnis, seperti membuat pemberitahuan jika volume pesanan turun 20% dibandingkan dengan periode serupa pada hari sebelumnya.
- Notifikasi perubahan data (serupa dalam konsep dengan notifikasi)pengambilan data perubahanseperti perubahan status pesanan tertentu.
Format data yang digunakan produsen data untuk pesan Pub/Sub memengaruhi biaya dan cara pemrosesan pesan tersebut. Untuk aliran data bervolume tinggi dalam arsitektur data mesh, format Avro atau Protobuf merupakan opsi yang tepat. Jika produsen data menggunakan format ini, mereka dapat menetapkan skema untuk topik Pub/Sub. Skema ini membantu memastikan bahwa konsumen menerima pesan yang dibentuk dengan baik.
Karena struktur data streaming dapat terus berubah, pembuatan versi antarmuka ini memerlukan koordinasi antara produsen data dan konsumen data. Ada beberapa pendekatan umum yang dapat dilakukan produsen data, yaitu sebagai berikut:
- Topik baru dibuat setiap kali struktur pesan berubah. Topik
ini sering kali memiliki skema Pub/Sub yang eksplisit. Konsumen data
yang memerlukan antarmuka baru dapat mulai menggunakan data baru. Versi pesan tersirat oleh nama topik, contohnya,
click_events_v1. Format pesan diketik dengan ketat. Tidak ada variasi pada format pesan antarpesan dalam topik yang sama. Kekurangan dari pendekatan ini adalah mungkin ada konsumen data yang tidak dapat beralih ke langganan baru. Dalam hal ini, produsen data harus terus memublikasikan acara ke semua topik aktif selama beberapa waktu, dan konsumen data yang berlangganan topik tersebut harus menghadapi kesenjangan dalam alur pesan, atau menghapus duplikat pesan-pesannya. - Data selalu dipublikasikan ke topik yang sama. Namun, struktur
pesan dapat berubah. Atribut pesan Pub/Sub (terpisah dari payload) menentukan versi pesan. Contoh,
v=1.0. Pendekatan ini menghilangkan kebutuhan untuk menangani kesenjangan atau duplikat; namun, semua konsumen data harus siap menerima pesan dengan jenis baru. Produsen data juga tidak dapat menggunakan skema topik Pub/Sub untuk pendekatan ini. - Pendekatan hybrid. Skema pesan dapat memiliki bagian data arbitrer yang dapat digunakan untuk kolom baru. Pendekatan ini dapat memberikan keseimbangan yang wajar antara memiliki data yang diketik dengan kuat, dan perubahan versi yang sering dan kompleks.
API akses data
Produsen data dapat membuat API khusus untuk secara langsung mengakses tabel dasar di data warehouse. Biasanya, produsen ini mengekspos API khusus ini sebagai REST atau gRPC API, dan men-deploy-nya di Cloud Run atau cluster Kubernetes. Gateway API seperti Apigee dapat menyediakan fitur tambahan lainnya, seperti throttling traffic atau lapisan cache. Fungsi-fungsi ini berguna saat mengekspos API akses data kepada konsumen di luar organisasi Google Cloud. Kandidat potensial untuk data akses API adalah kueri serentak yang sensitif terhadap latensi dan tinggi Keduanya menghasilkan hasil yang relatif kecil dalam satu API dan dapat di-cache secara efektif.
Contoh API khusus untuk akses data adalah sebagai berikut:
- Tampilan gabungan pada metrik SLA dari tabel atau produk.
- Top 10 menampilkan data teratas (yang kemungkinan di-cache) dari tabel tertentu.
- Sebuah dataset statistik tabel (jumlah total baris, atau distribusi data dalam kolom kunci).
Pedoman dan tata kelola apa pun yang dimiliki oleh organisasi terkait mem-build API aplikasi juga berlaku untuk API khusus yang dibuat oleh produsen data. Pedoman dan tata kelola organisasi harus mencakup masalah seperti hosting, pemantauan, kontrol akses, dan pembuatan versi.
Kekurangan dari API khusus adalah bahwa produsen data bertanggung jawab atas infrastruktur tambahan yang diperlukan untuk menghosting antarmuka ini, serta coding dan pemeliharaan API khusus. Sebaiknya produsen data menyelidiki opsi lain sebelum memutuskan untuk membuat API akses data khusus. Sebagai contoh, produsen data dapat menggunakan BigQuery BI Engine untuk mengurangi latensi respons dan meningkatkannya serentak.
Looker Blocks
Untuk produk seperti Looker, yang banyak digunakan dalam alat business intelligence (BI), mungkin akan membantu untuk menjaga seperangkat widget alat khusus BI. Karena tim produsen data mengetahui model data dasar yang digunakan dalam domain, tim tersebut adalah yang paling tepat untuk membuat dan menjaga kumpulan visualisasi yang telah di-build.
Dalam kasus Looker, visualisasi ini dapat berupa kumpulan Looker Blocks (model data LookML telah di-build). Looker Blooks dapat dengan mudah digabungkan ke dasbor yang dihosting oleh konsumen.
Model ML
Karena tim yang bekerja di domain data memiliki pemahaman dan pengetahuan yang mendalam tentang data mereka, mereka sering kali merupakan tim terbaik untuk membangun dan memelihara model ML yang dilatih berdasarkan data domain. Model-model ML ini dapat diekspos melalui beberapa antarmuka yang berbeda, termasuk yang berikut:
- Model-model ML BigQuery dapat di-deploy dalam dataset khusus dan dibagikan dengan konsumen data untuk prediksi batch BigQuery.
- Model-model BigQuery ML dapat diekspor ke Vertex AI untuk digunakan dalam prediksi online.
Pertimbangan lokasi data untuk antarmuka pemakaian
Pertimbangan penting saat produsen data menentukan antarmuka konsumsi untuk produk data adalah lokasi data. Secara umum, untuk meminimalkan biaya, data harus diproses di region yang sama dengan tempat penyimpanannya. Pendekatan ini membantu mencegah biaya traffic keluar data lintas region. Pendekatan ini juga memiliki latensi konsumsi data terendah. Oleh karena itu, data yang disimpan di lokasi multi-regional lokasi BigQuery biasanya menjadi kandidat terbaik untuk diekspos sebagai produk data.
Namun, karena alasan performa, data yang disimpan di Cloud Storage dan diekspos melalui tabel BigLake atau API baca langsung harus disimpan di bucket regional.
Jika data yang diekspos dalam satu produk berada di satu region dan perlu digabungkan dengan data di domain lain di region lain, konsumen data harus mempertimbangkan batasan berikut:
- Kueri lintas region yang menggunakan BigQuery SQL tidak didukung. Jika metode pemakaian utama untuk data ini adalah BigQuery SQL, semua tabel dalam kueri harus berada di lokasi yang sama.
- Komitmen tarif tetap BigQuery bersifat regional. Jika sebuah project hanya menggunakan komitmen tarif tetap di satu region tetapi mengkueri produk data di region lain, harga sesuai permintaan akan berlaku.
- Konsumen data dapat menggunakan API baca langsung untuk membaca data dari region lain. Namun, biaya keluar jaringan lintas regional akan berlaku, dan konsumen data kemungkinan besar akan mengalami latensi untuk transfer data yang besar.
Data yang sering diakses di berbagai region dapat direplikasi ke
region-region tersebut untuk mengurangi biaya dan latensi dari kueri yang ditanggung oleh konsumen
produk. Sebagai contoh, dataset BigQuery dapat disalin ke region lain. Namun, data hanya boleh disalin jika diperlukan. Sebaiknya
produsen data hanya menyediakan sebagian data produk
yang tersedia untuk beberapa region saat Anda menyalin data. Pendekatan ini membantu
meminimalkan latensi dan biaya replikasi. Pendekatan ini dapat mengakibatkan kebutuhan
untuk menyediakan beberapa versi antarmuka konsumsi dengan region lokasi
data yang secara eksplisit disebutkan. Sebagai contoh, tampilan yang diotorisasi BigQuery dapat ekspos melalui penamaan seperti sales_eu_v1 dan sales_us_v1.
Antarmuka aliran data yang menggunakan topik Pub/Sub tidak memerlukan logika replikasi tambahan untuk menggunakan pesan di region yang berbeda dengan region di mana pesan tersebut disimpan. Namun, dengan penambahan lintas region biaya traffic keluar diterapkan dalam kasus ini.
Mengekspos antarmuka konsumsi kepada konsumen data
Bagian ini membahas cara membuat antarmuka konsumsi dapat ditemukan oleh calon konsumen. Data Catalog adalah layanan terkelola sepenuhnya yang dapat digunakan oleh organisasi untuk menyediakan layanan penemuan data dan pengelolaan metadata. Produsen data harus membuat antarmuka konsumsi produk datanya dapat ditelusuri dan menganotasinya dengan metadata yang sesuai agar konsumen produk dapat mengaksesnya dengan cara layanan mandiri. Rab
Bagian berikut membahas cara setiap jenis antarmuka ditentukan sebagai entri Data Catalog.
Antarmuka SQL berbasis BigQuery
Metadata teknis, seperti nama tabel atau skema tabel yang sepenuhnya memenuhi syarat, secara otomatis didaftarkan untuk tampilan yang diotorisasi, tampilan BigLake, dan tabel BigQuery yang tersedia melalui Storage Read API. Sebaiknya pembuat data juga memberikan informasi tambahan dalam dokumentasi produk data untuk membantu konsumen data. Sebagai contoh, untuk membantu pengguna menemukan dokumentasi produk untuk melakukan entri data produser data menambahkan URL ke salah satu tag yang telah diterapkan ke entri Produser juga dapat memberikan informasi berikut:
- Kumpulan kolom yang dikelompokkan, yang harus digunakan dalam filter kueri.
- Nilai enumerasi untuk kolom yang memiliki jenis enumerasi logis, jika jenisnya tidak diberikan sebagai bagian dari deskripsi kolom.
- Gabungan yang didukung dengan tabel lain.
Aliran data
Topik Pub/Sub secara otomatis didaftarkan dengan Data Catalog. Namun, produser data harus mendeskripsikan skema dalam dokumentasi produk data.
Cloud Storage API
Data Catalog mendukung definisi entri file Cloud Storage dan skemanya. Jika kumpulan file data lake dikelola oleh Dataplex, kumpulan file tersebut akan otomatis terdaftar di Data Catalog Kumpulan file yang tidak terkait dengan Dataplex ditambahkan menggunakan pendekatan yang berbeda.
Antarmuka lainnya
Anda dapat menambahkan antarmuka lain yang tidak memiliki dukungan bawaan dari Data Catalog dengan membuat entri kustom.
Langkah selanjutnya
- Lihat penerapan referensi arsitektur mesh data.
- Pelajari lebih lanjut tentang BigQuery.
- Baca tentang Dataplex.
- Untuk arsitektur referensi, diagram, dan praktik terbaik lainnya, jelajahi Pusat Arsitektur Cloud.