March 2023
·
12 Reads

This page lists the scientific contributions of an author, who either does not have a ResearchGate profile, or has not yet added these contributions to their profile.
It was automatically created by ResearchGate to create a record of this author's body of work. We create such pages to advance our goal of creating and maintaining the most comprehensive scientific repository possible. In doing so, we process publicly available (personal) data relating to the author as a member of the scientific community.
If you're a ResearchGate member, you can follow this page to keep up with this author's work.
If you are this author, and you don't want us to display this page anymore, please let us know.
March 2023
·
12 Reads
July 2017
·
22 Reads
·
2 Citations
Big Data and Information Analytics
December 2016
·
524 Reads
·
18 Citations
Demand forecasting is one of the important inputs for a successful restaurant yield and revenue management system. Sales forecasting is crucial for an independent restaurant and for restaurant chains as well. In this chapter a comprehensive literature review and classification of restaurant sales and consumer demand techniques are presented. Sales prediction is very complex due to the impact of internal and external environment. However, a reliable sales forecasting methodology can improve the quality of business strategy. A range of methodologies and models for forecasting are given in the literature. These techniques are categorized here into seven categories, also including hybrid models. The methodology for different kinds of analytical methods is briefly described, the advantages and drawbacks are discussed, and relevant set of papers is selected. Conclusions and comments are also made on future research directions.
December 2016
·
48 Reads
·
15 Citations
MapReduce is an important programming model for processing in distributed environments. Compared to other distributed programming models, MapReduce reduces communication overheads between computers and improves fault tolerance. However, the MapReduce model does not allow for automatic synchronization between jobs. A large number of data analytics algorithms use a recursive divide-and-conquer approach, which inherently allows for parallelism at each level of recursion. However, it is often difficult to parallelize such algorithms using the traditional MapReduce model if the process requires synchronization. In this paper we introduce Parent-Child MapReduce, a version of the MapReduce programming model that allows for MapReduce tasks to be created dynamically and synchronized in a hierarchical parent-child fashion. Using the Parallel FP-Growth (PFP) algorithm for mining frequent patterns as a reference, we show that Parent-Child MapReduce can be used to parallelize recursive divide-and-conquer algorithms using the MapReduce model and that this can lead to significant speed ups in the computational speed of such algorithms. Our evaluation shows that we can achieve 68% (or 3 times) performance gain when used with PFP.
October 2016
·
3,759 Reads
·
33 Citations
Demand forecasting is one of the important inputs for a successful restaurant yield and revenue management system. Sales forecasting is crucial for an independent restaurant and for restaurant chains as well. In the paper a comprehensive literature review and classification of restaurant sales and consumer demand techniques are presented. A range of methodologies and models for forecasting are given in the literature. These techniques are categorized here into seven categories, also included hybrid models. The methodology for different kind of analytical methods is briefly described, the advantages and drawbacks are discussed, and relevant set of papers is selected. Conclusions and comments are also made on future research directions.
October 2016
·
70 Reads
·
6 Citations
In the Canadian Province of Ontario, electricity consumers pay a surcharge for electricity called the Global Adjustment (GA). For large consumers, having the ability to predict the top 5 daily energy demand hours of the year, called 5 Coincident Peaks (5CPs), can save millions of dollars in GA costs, and help decrease peak energy usage. This paper presents a Naive Bayesian classification model for predicting the 5CPs. The model classifies hourly energy demand as being a 5CP hour or not. The model was tested using hourly energy demand for the province of Ontario over a 21 year period (1995–2015). Classifying a day as a 5CP hour containing day yielded a mean precision and recall of 0.49 (0.18) and 0.88 (0.23) (Standard deviation is in brackets), respectively. Targeting the 5CP hours to within three candidate hours of potential 5CP containing days yielded a mean precision and recall of 0.47 (0.19) and 0.83 (0.22), respectively.
September 2016
·
86 Reads
·
6 Citations
Within e-learning environment and research, adaptive learning systems (ALS) can provide an adaptive learning environment that intelligently adapts to a user's needs by presenting suitable information, instructional materials, feedback, and recommendations based on the user's unique individual characteristics and situation. This chapter discusses three main contributions of data mining to adaptive learning systems (ALS), including prediction, classification, and recommendation. One of the most special features of ALS is the user model that represents essential personalized information about each user. The ALS model consists of the storage module, the user model module, the reasoning module, and the management module. The reasoning module's main functions are to support student learning activities. This module is responsible for filtering knowledge points (KP's) filtering, searching and organizing learning resources, generating a learning program, and updating the user model and the knowledge base.
April 2016
·
68 Reads
·
2 Citations
JMIR Diabetes
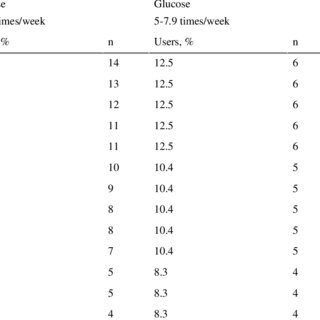
Background: Complications from type 2 diabetes mellitus can be prevented when patients perform health behaviors such as vigorous exercise and glucose-regulated diet. The use of smartphones for tracking such behaviors has demonstrated success in type 2 diabetes management while generating repositories of analyzable digital data, which, when better understood, may help improve care. Data mining methods were used in this study to better understand self-monitoring patterns using smartphone tracking software. Objective: Associations were evaluated between the smartphone monitoring of health behaviors and HbA1c reductions in a patient subsample with type 2 diabetes who demonstrated clinically significant benefits after participation in a randomized controlled trial. Methods: A priori association-rule algorithms, implemented in the C language, were applied to app-discretized use data involving three primary health behavior trackers (exercise, diet, and glucose monitoring) from 29 participants who achieved clinically significant HbA1c reductions. Use was evaluated in relation to improved HbA1c outcomes. Results: Analyses indicated that nearly a third (9/29, 31%) of participants used a single tracker, half (14/29, 48%) used two primary trackers, and the remainder (6/29, 21%) of the participants used three primary trackers. Decreases in HbA1c were observed across all groups (0.97-1.95%), but clinically significant reductions were more likely with use of one or two trackers rather than use of three trackers (OR 0.18, P=.04). Conclusions: Data mining techniques can reveal relevant coherent behavior patterns useful in guiding future intervention structure. It appears that focusing on using one or two trackers, in a symbolic function, was more effective (in this sample) than regular use of all three trackers.
February 2016
·
54 Reads
·
1 Citation
Pattern Analysis and Applications
The image feature used for classification is a crucial part of a character recognition system. To achieve a high accuracy of offline handwriting recognition, the feature should capture the essence of differences including the differences between different characters and the differences between different drawings of the same character. In this paper, we present a novel image feature called direction histogram (DH) and a feature extraction algorithm called bag of histogram (BoH). Unlike the traditional pre-defined feature, DH was designed based on the nature of language and the variation of writing styles. DH is, therefore, a global feature that represents pixel density in all directions around each center. BoH was introduced as it tolerates to thickness and curve variation and ignores the curve connectivity (if any). Fifty-two datasets, each containing 30 drawings of 80 Thai characters, are used for training our neural network, and the original, thick, and distorted handwriting datasets are used for testing. The recognition system with our proposed DH and BoH feature extraction algorithm yielded higher recognition accuracy compared to the convolutional neural network.
August 2015
·
21 Reads
·
3 Citations
... The task is to predict the ozone level eight hours ahead of time. The PAKDD2009 stream [54] consists of private label credit card application records and the task is to decide whether a given application should be approved. Forest Covertype (Covtype) stream [55] contains the cartographic information about the forest of 30 × 30-meter cells and the task is to predict the cover type for a given cell. ...
January 2009
Lecture Notes in Computer Science
... Many reviews such as [24,50,52], and research works such as [18,38] on text-to-picture systems highlight the following issues: ...
July 2017
Big Data and Information Analytics
... Previous research also illustrated that FP tree-like algorithms performed better than Apriori-like algorithm based on distributed, parallel computing, and Hadoop techniques, as well as other algorithms based on the wellknown framework Apache Spark, such as PFP (parallelize the FP-Growth) algorithm [6] based on Hadoop, PIFP-Growth (parallelized incremental FP-Growth) [7], R-PFP (recursive-PFP) [8], MR-PFP (MapReduce-based parallel frequent pattern growth) [9], PBFP-Growth (parallel block FP-Growth algorithm) [10], MISFP-growth (multiple item support frequent patterns) [11], BigFIM (big frequent itemset mining) [12], and S-FPG (Spark FP-Growth) [13]. Some research proposed approaches to mining frequent itemsets from secondary memory when the database or the data structures used in the mining are too large to fit in the main memory [2], [14]. ...
December 2016
... Adaptive learning works by following a learner's progress through an eLearning course, dynamically altering the modules and content they are presented with so they are challenged without frustration (Liu, & Cercone, 2016). At the same time, the learning path can be optimised to ensure that learners are only being presented with material they have already mastered (Janati & Maach, 2017). ...
September 2016
... Kollmann [33] Manual -Manual Manual Manual -N. Wayne [34] Manual -Manual Manual --E. J. Jeon [22] Automatic -Manual Manual Manual Support-G. ...
April 2016
JMIR Diabetes
... Machine learning and statistical models are frequently employed for demand forecasting of restaurants and food products [16]. Arunraj et al. [9] developed a forecasting method based on statistical modeling. ...
October 2016
... Leveraging short-term load forecasts, Jiang et al. (2014) adopted a probabilistic approach for estimating the probability of the next day containing the highest hourly demand of a year. A Naive Bayesian classification model was proposed for classifying whether an hour is a 5CP (top 5 coincident peaks of a year) hour (Ryu et al., 2016). Liu and Brown (2019a) proposed a convolutional neural network (CNN) classification model to predict 24 h ahead whether a day is a 5CP day. ...
October 2016
... More Avoiding food waste accurate forecasting is pivotal for effective production and inventory management (Goonan et al., 2014). Although many in the industry still rely on these judgmental techniques (Lasek et al., 2016), ML offers an unbiased, adaptive solution for deriving forecasts from sales data (Tsoumakas, 2019). Linear models, such as autoregressive integrated moving average and its variants, have traditionally been used for time-series data in economics and tourism (Song et al., 2019;Bang et al., 2019). ...
December 2016
... In An and Huang (2013), probabilistic latent semantic analysis was used to cluster and rerank documents to boost the novelty. In An and Cercone (2014), different techniques used in TREC Genomics track were analyzed to show how complementary these techniques were to each other. ...
April 2014
... In [8], a detailed description of assistive technology products available are presented. In [9], a computer system architecture design and ...
July 2013
Frontiers in Artificial Intelligence and Applications