From its founding, Android has been guided by principles of openness, transparency, safety, and choice. Android gives you the freedom to choose which device best fits your needs, while also providing the flexibility to download apps from a variety of sources, including preloaded app stores such as the Google Play Store or the Galaxy Store; third-party app stores; and direct downloads from the Internet.Keeping users safe in an open ecosystem takes sophisticated defenses. That’s why Android provides multiple layers of protections, powered by AI and backed by a large dedicated security & privacy team, to help to protect our users from security threats while continually making the platform more resilient. We also provide our users with numerous built-in protections like Google Play Protect, the world’s most widely deployed threat detection service, which actively scans over 125 billion apps on devices every day to monitor for harmful behavior. That said, our data shows that a disproportionate amount of bad actors take advantage of select APIs and distribution channels in this open ecosystem.
Elevating app security in an open ecosystem
While users have the flexibility to download apps from many sources, the safety of an app can vary depending on the download source. Google Play, for example, carries out rigorous operational reviews to ensure app safety, including proper high-risk API use and permissions handling. Other app stores may also follow established policies and procedures that help reduce risks to users and their data. These protections often include requirements for developers to declare which permissions their apps use and how developers plan to use app data. Conversely, standalone app distribution sources like web browsers, messaging apps or file managers – which we commonly refer to as Internet-sideloading – do not offer the same rigorous requirements and operational reviews. Our data demonstrates that users who download from these sources today face unusually high security risks due to these missing protections.
We recently launched enhanced Google Play Protect real-time scanning to help better protect users against novel malicious Internet-sideloaded apps. This enhancement is designed to address malicious apps that leverage various methods, such as AI, to avoid detection. This feature, now deployed on Android devices with Google Play Services in India, Thailand, Singapore and Brazil, has already made a significant impact on user safety.
As a result of the real-time scanning enhancement, Play Protect has identified 515,000 new malicious apps and issued more than 3.1 million warnings or blocks of those apps. Play Protect is constantly improving its detection capabilities with each identified app, allowing us to strengthen our protections for the entire Android ecosystem.
A new pilot to combat financial fraud
Cybercriminals continue to invest in advanced financial fraud scams, costing consumers more than $1 trillion in losses. According to the 2023 Global State of Scams Report by the Global Anti-Scam Alliance, 78 percent of mobile users surveyed experienced at least one scam in the last year. Of those surveyed, 45 percent said they’re experiencing more scams in the last 12 months. The Global Scam Report also found that scams were most often initiated by sending scam links via various messaging platforms to get users to install malicious apps and very often paired with a phone call posing to be from a valid entity.
Scammers frequently employ social engineering tactics to deceive mobile users. Using urgent pretenses that often involve a risk to a user’s finances or an opportunity for quick wealth, cybercriminals convince users to disable security safeguards and ignore proactive warnings for potential malware, scams, and phishing. We’ve seen a large percentage of users ignore, or are tricked into dismissing, these proactive Android platform warnings and proceed with installing malicious apps. This can lead to users ultimately disclosing their security codes, passwords, financial information and/or transferring funds unknowingly to a fraudster.
To help better protect Android users from these financial fraud attacks, we are piloting enhanced fraud protection with Google Play Protect. As part of a continued strategic partnership with the Cyber Security Agency of Singapore (CSA), we will launch this first pilot in Singapore in the coming weeks to help keep Android users safe from mobile financial fraud.
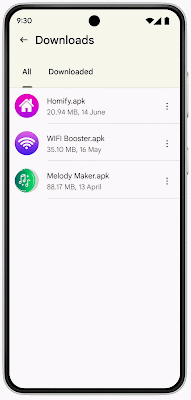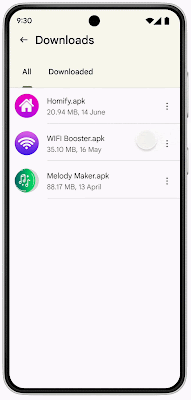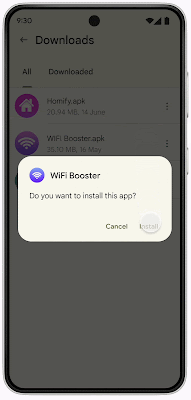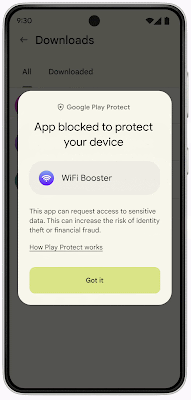
This enhanced fraud protection will analyze and automatically block the installation of apps that may use sensitive permissions frequently abused for financial fraud when the user attempts to install the app from an Internet-sideloading source (web browsers, messaging apps or file managers). This enhancement will inspect the permissions the app declared in real-time and specifically look for four permission requests: RECEIVE_SMS, READ_SMS, BIND_Notifications, and Accessibility. These permissions are frequently abused by fraudsters to intercept one-time passwords via SMS or notifications, as well as spy on screen content. Based on our analysis of major fraud malware families that exploit these sensitive permissions, we found that over 95 percent of installations came from Internet-sideloading sources.
During the upcoming pilot, when a user in Singapore attempts to install an application from an Internet-sideloading source and any of these four permissions are declared, Play Protect will automatically block the installation with an explanation to the user.
Collaborating to combat mobile fraud
This enhanced fraud protection has undergone testing by the Singapore government and will be rolling out to Android devices with Google Play services.
“The fight against online scams is a dynamic one. As cybercriminals refine their methods, we must collaborate and innovate to stay ahead, “ said Mr Chua Kuan Seah, Deputy Chief Executive of CSA. “Through such partnerships with technology players like Google, we are constantly improving our anti-scam defenses to protect Singaporeans online and safeguard their digital assets.”
Together with CSA, we will be closely monitoring the results of the pilot program to assess its impact and make adjustments as needed. We will also support CSA by continuing to assist with malware detection and analysis, sharing malware insights and techniques, and creating user and developer education resources.
How developers can prepareFor developers distributing apps that may be affected by this pilot, please take the time to review the device permissions your app is requesting and ensure you’re following developer best practices. Your app should only request permissions that the app needs to complete an action and ensure it does not violate the Mobile Unwanted Software principles. Always ensure that your app does not engage in behavior that could be considered potentially harmful or malware.
If you find that your app is affected by the app protection pilot you can refer to our updated developer guidance for Play Protect warnings for tips on how to help fix potential issues with your app and instructions for filing an appeal if needed.
Check out the video below to learn more.
Our commitment to protecting Android users
We believe industry collaboration is essential to protect users from mobile security threats and fraud. Piloting these new protections will help us stay ahead of new attacks and evolve our solutions to defeat scammers and their expanding fraud attempt. We have an unwavering commitment to protecting our users around the world and look forward to continuing to partner with governments, ecosystem partners and other stakeholders to improve user protections.
Back in 2021, we announced that Google was joining the Rust Foundation. At the time, Rust was already in wide use across Android and other Google products. Our announcement emphasized our commitment to improving the security reviews of Rust code and its interoperability with C++ code. Rust is one of the strongest tools we have to address memory safety security issues. Since that announcement, industry leaders and government agencies have echoed our sentiment.
We are delighted to announce that Google has provided a grant of $1 million to the Rust Foundation to support efforts that will improve the ability of Rust code to interoperate with existing legacy C++ codebases. We’re also furthering our existing commitment to the open-source Rust community by aggregating and publishing audits for Rust crates that we use in open-source Google projects. These contributions, along with our previous interoperability contributions, have us excited about the future of Rust.
“Based on historical vulnerability density statistics, Rust has proactively prevented hundreds of vulnerabilities from impacting the Android ecosystem. This investment aims to expand the adoption of Rust across various components of the platform.” – Dave Kleidermacher, Google Vice President of Engineering, Android Security & Privacy
While Google has seen the most significant growth in the use of Rust in Android, we’re continuing to grow its use across more applications, including clients and server hardware.
“While Rust may not be suitable for all product applications, prioritizing seamless interoperability with C++ will accelerate wider community adoption, thereby aligning with the industry goals of improving memory safety.” – Royal Hansen, Google Vice President of Safety & Security
The Rust tooling and ecosystem already support interoperability with Android and with continued investment in tools like cxx, autocxx, bindgen, cbindgen, diplomat, and crubit, we are seeing regular improvements in the state of Rust interoperability with C++. As these improvements have continued, we’ve seen a reduction in the barriers to adoption and accelerated adoption of Rust. While that progress across the many tools continues, it is often only expanded incrementally to support the particular needs of a given project or company.
In order to accelerate both Rust adoption at Google as well as more broadly across the industry, we are eager to invest in and collaborate on any needed ABI changes, tooling and build system support, wrapper libraries, or other areas identified.
We are excited to support this work through the Rust Foundation’s Interop Initiative and in collaboration with the Rust project to ensure that any additions made are suitable and address the challenges of Rust adoption that projects using C++ face. Improving memory safety across the software industry is one of the key technology challenges of our time, and we invite others across the community and industry to join us in working together to secure the open source ecosystem for everyone.
Learn more about the Rust Foundation’s Interop Initiative by reading their recent announcement.
This week, the United Nations convened member states to continue its years-long negotiations on the UN Cybercrime Treaty, titled “Countering the Use of Information and Communications Technologies for Criminal Purposes.”
As more aspects of our lives intersect with the digital sphere, law enforcement around the world has increasingly turned to electronic evidence to investigate and disrupt criminal activity. Google takes the threat of cybercrime very seriously, and dedicates significant resources to combating it. When governments send Google legal orders to disclose user data in connection with their investigations, we carefully review those orders to make sure they satisfy applicable laws, international norms, and Google’s policies. We also regularly report the number of these orders in our Transparency Report.
To ensure that transnational legal demands are issued consistent with rule of law, we have long called for an international framework for digital evidence that includes robust due process protections, respects human rights (including the right to free expression), and aligns with existing international norms. This is particularly important in the case of transnational criminal investigations, where the legal protections in one jurisdiction may not align with those in others.
Such safeguards aren’t just important to ensuring free expression and human rights, they are also critical to protecting web security. Too often, as we know well from helping stand up the Security Researcher Legal Defense Fund, individuals working to advance cybersecurity for the public good end up facing criminal charges. The Cybercrime Treaty should not criminalize the work of legitimate cybersecurity researchers and penetration testers, which is designed to protect individual systems and the web as a whole.
UN Member States have an opportunity to strengthen global cybersecurity by adopting a treaty that encourages the criminalization of the most egregious and systemic activities — on which all parties can agree — while adopting a framework for sharing digital evidence that is transparent, grounded in the rule of law, based on pre-existing international frameworks like the Universal Declaration on Human Rights, and aligned with principles of necessity and proportionality. At the same time, Member States should avoid attempts to criminalize activities that raise significant freedom of expression issues, or that actually undercut the treaty’s goal of reducing cybercrime. That will require strengthening critical guardrails and protections.
We urge Member States to heed calls from civil society groups to address critical gaps in the Treaty and revise the text to protect users and security professionals — not endanger the security of the web.
The AI world moves fast, so we’ve been hard at work keeping security apace with recent advancements. One of our approaches, in alignment with Google’s Secure AI Framework (SAIF), is using AI itself to automate and streamline routine and manual security tasks, including fixing security bugs. Last year we wrote about our experiences using LLMs to expand vulnerability testing coverage, and we’re excited to share some updates.
Today, we’re releasing our fuzzing framework as a free, open source resource that researchers and developers can use to improve fuzzing’s bug-finding abilities. We’ll also show you how we’re using AI to speed up the bug patching process. By sharing these experiences, we hope to spark new ideas and drive innovation for a stronger ecosystem security.
Last August, we announced our framework to automate manual aspects of fuzz testing (“fuzzing”) that often hindered open source maintainers from fuzzing their projects effectively. We used LLMs to write project-specific code to boost fuzzing coverage and find more vulnerabilities. Our initial results on a subset of projects in our free OSS-Fuzz service were very promising, with code coverage increased by 30% in one example. Since then, we’ve expanded our experiments to more than 300 OSS-Fuzz C/C++ projects, resulting in significant coverage gains across many of the project codebases. We’ve also improved our prompt generation and build pipelines, which has increased code line coverage by up to 29% in 160 projects.
How does that translate to tangible security improvements? So far, the expanded fuzzing coverage offered by LLM-generated improvements allowed OSS-Fuzz to discover two new vulnerabilities in cJSON and libplist, two widely used projects that had already been fuzzed for years. As always, we reported the vulnerabilities to the project maintainers for patching. Without the completely LLM-generated code, these two vulnerabilities could have remained undiscovered and unfixed indefinitely.
Fuzzing is fantastic for finding bugs, but for security to improve, those bugs also need to be patched. It’s long been an industry-wide struggle to find the engineering hours needed to patch open bugs at the pace that they are uncovered, and triaging and fixing bugs is a significant manual toll on project maintainers. With continued improvements in using LLMs to find more bugs, we need to keep pace in creating similarly automated solutions to help fix those bugs. We recently announced an experiment doing exactly that: building an automated pipeline that intakes vulnerabilities (such as those caught by fuzzing), and prompts LLMs to generate fixes and test them before selecting the best for human review.
This AI-powered patching approach resolved 15% of the targeted bugs, leading to significant time savings for engineers. The potential of this technology should apply to most or all categories throughout the software development process. We’re optimistic that this research marks a promising step towards harnessing AI to help ensure more secure and reliable software.
Since we’ve now open sourced our framework to automate manual aspects of fuzzing, any researcher or developer can experiment with their own prompts to test the effectiveness of fuzz targets generated by LLMs (including Google’s VertexAI or their own fine-tuned models) and measure the results against OSS-Fuzz C/C++ projects. We also hope to encourage research collaborations and to continue seeing other work inspired by our approach, such as Rust fuzz target generation.
If you’re interested in using LLMs to patch bugs, be sure to read our paper on building an AI-powered patching pipeline. You’ll find a summary of our own experiences, some unexpected data about LLM’s abilities to patch different types of bugs, and guidance for building pipelines in your own organizations.
Helping Pixel owners upgrade to the easier, safer way to sign in
Your phone contains a lot of your personal information, from financial data to photos. Pixel phones are designed to help protect you and your data, and make security and privacy as easy as possible. This is why the Pixel team has been especially excited about passkeys—the easier, safer alternative to passwords.
Passkeys are safer because they’re unique to each account, and are more resistant against online attacks such as phishing. They’re easier to use because there’s nothing for you to remember: when it’s time to sign in, using a passkey is as simple as unlocking your device with your face or fingerprint, or your PIN/pattern/password.
Google is working to accelerate passkey adoption. We’ve launched support for passkeys on Google platforms such as Android and Chrome, and recently we announced that we’re making passkeys a default option across personal Google Accounts. We’re also working with our partners across the industry to make passkeys available on more websites and apps.
Recently, we took things a step further. As part of last December’s Pixel Feature Drop, we introduced a new feature to Google Password Manager: passkey upgrades. With this new feature, Google Password Manager will let you discover which of your accounts support passkeys, and help you upgrade with just a few taps.
This new passkey upgrade experience is now available on Pixel phones (starting from Pixel 5a) as well as Pixel Tablet. Google Password manager will incorporate these updates for other platforms in the future.
Welcome back to our latest update on MiraclePtr, our project to protect against use-after-free vulnerabilities in Google Chrome. If you need a refresher, you can read our previous blog post detailing MiraclePtr and its objectives.
We are thrilled to announce that since our last update, we have successfully enabled MiraclePtr for more platforms and processes:
Furthermore, we have changed security guidelines to downgrade MiraclePtr-protected issues by one severity level!
First let’s focus on its security impact. Our analysis is based on two primary information sources: incoming vulnerability reports and crash reports from user devices. Let's take a closer look at each of these sources and how they inform our understanding of MiraclePtr's effectiveness.
Chrome vulnerability reports come from various sources, such as:
For the purposes of this analysis, we focus on vulnerabilities that affect platforms where MiraclePtr was enabled at the time the issues were reported. We also exclude bugs that occur inside a sandboxed renderer process. Since the initial launch of MiraclePtr in 2022, we have received 168 use-after-free reports matching our criteria.
What does the data tell us? MiraclePtr effectively mitigated 57% of these use-after-free vulnerabilities in privileged processes, exceeding our initial estimate of 50%. Reaching this level of effectiveness, however, required additional work. For instance, we not only rewrote class fields to use MiraclePtr, as discussed in the previous post, but also added MiraclePtr support for bound function arguments, such as Unretained pointers. These pointers have been a significant source of use-after-frees in Chrome, and the additional protection allowed us to mitigate 39 more issues.
Unretained
Moreover, these vulnerability reports enable us to pinpoint areas needing improvement. We're actively working on adding support for select third-party libraries that have been a source of use-after-free bugs, as well as developing a more advanced rewriter tool that can handle transformations like converting std::vector<T*> into std::vector<raw_ptr<T>>. We've also made several smaller fixes, such as extending the lifetime of the task state object to cover several issues in the “this pointer” category.
std::vector<T*>
std::vector<raw_ptr<T>>
this
Crash reports offer a different perspective on MiraclePtr's effectiveness. As explained in the previous blog post, when an allocation is quarantined, its contents are overwritten with a special bit pattern. If the allocation is used later, the pattern will often be interpreted as an invalid memory address, causing a crash when the process attempts to access memory at that address. Since the dereferenced address remains within a small, predictable memory range, we can distinguish MiraclePtr crashes from other crashes.
Although this approach has its limitations — such as not being able to obtain stack traces from allocation and deallocation times like AddressSanitizer does — it has enabled us to detect and fix vulnerabilities. Last year, six critical severity vulnerabilities were identified in the default setup of Chrome Stable, the version most people use. Impressively, five of the six were discovered while investigating MiraclePtr crash reports! One particularly interesting example is CVE-2022-3038. The issue was discovered through MiraclePtr crash reports and fixed in Chrome 105. Several months later, Google's Threat Analysis Group discovered an exploit for that vulnerability used in the wild against clients of a different Chromium-based browser that hadn’t shipped the fix yet.
To further enhance our crash analysis capabilities, we've recently launched an experimental feature that allows us to collect additional information for MiraclePtr crashes, including stack traces. This effectively shortens the average crash report investigation time.
MiraclePtr enables us to have robust protection against use-after-free bug exploits, but there is a performance cost associated with it. Therefore, we have conducted experiments on each platform where we have shipped MiraclePtr, which we used in our decision-making process.
The main cost of MiraclePtr is memory. Specifically, the memory usage of the browser process increased by 5.5-8% on desktop platforms and approximately 2% on Android. Yet, when examining the holistic memory usage across all processes, the impact remains within a moderate 1-3% range to lower percentiles only.
The main cause of the additional memory usage is the extra size to allocate the reference count. One might think that adding 4 bytes to each allocation wouldn’t be a big deal. However, there are many small allocations in Chrome, so even the 4B overhead is not negligible. Moreover, PartitionAlloc also uses pre-defined allocation bucket sizes, so this extra 4B pushes certain allocations (particularly power-of-2 sized) into a larger bucket, e.g. 4096B → 5120B.
We also considered the performance cost. We verified that there were no regressions to the majority of our top-level performance metrics, including all of the page load metrics, like Largest Contentful Paint, First Contentful Paint and Cumulative Layout Shift. We did find a few regressions, such as a 10% increase in the 99th percentile of the browser process main thread contention metric, a 1.5% regression in First Input Delay on ChromeOS, and a 1.5% regression in tab startup time on Android. The main thread contention metric tries to estimate how often a user input can be delayed and so for example on Windows this was a change from 1.6% to 1.7% at the 99th percentile only. These are all minor regressions. There has been zero change in daily active usage, and we do not anticipate these regressions to have any noticeable impact on users.
In summary, MiraclePtr has proven to be effective in mitigating use-after-free vulnerabilities and enhancing the overall security of the Chrome browser. While there are performance costs associated with the implementation of MiraclePtr, our analysis suggests that the benefits in terms of security improvements far outweigh these. We are committed to continually refining and expanding the feature to cover more areas. For example we are working to add coverage to third-party libraries used by the GPU process, and we plan to enable BRP on the renderer process. By sharing our findings and experiences, we hope to contribute to the broader conversation surrounding browser security and inspire further innovation in this crucial area.
Android’s defense-in-depth strategy applies not only to the Android OS running on the Application Processor (AP) but also the firmware that runs on devices. We particularly prioritize hardening the cellular baseband given its unique combination of running in an elevated privilege and parsing untrusted inputs that are remotely delivered into the device.
This post covers how to use two high-value sanitizers which can prevent specific classes of vulnerabilities found within the baseband. They are architecture agnostic, suitable for bare-metal deployment, and should be enabled in existing C/C++ code bases to mitigate unknown vulnerabilities. Beyond security, addressing the issues uncovered by these sanitizers improves code health and overall stability, reducing resources spent addressing bugs in the future.
As we outlined previously, security research focused on the baseband has highlighted a consistent lack of exploit mitigations in firmware. Baseband Remote Code Execution (RCE) exploits have their own categorization in well-known third-party marketplaces with a relatively low payout. This suggests baseband bugs may potentially be abundant and/or not too complex to find and exploit, and their prominent inclusion in the marketplace demonstrates that they are useful.
Baseband security and exploitation has been a recurring theme in security conferences for the last decade. Researchers have also made a dent in this area in well-known exploitation contests. Most recently, this area has become prominent enough that it is common to find practical baseband exploitation trainings in top security conferences.
Acknowledging this trend, combined with the severity and apparent abundance of these vulnerabilities, last year we introduced updates to the severity guidelines of Android’s Vulnerability Rewards Program (VRP). For example, we consider vulnerabilities allowing Remote Code Execution (RCE) in the cellular baseband to be of CRITICAL severity.
Common classes of vulnerabilities can be mitigated through the use of sanitizers provided by Clang-based toolchains. These sanitizers insert runtime checks against common classes of vulnerabilities. GCC-based toolchains may also provide some level of support for these flags as well, but will not be considered further in this post. We encourage you to check your toolchain’s documentation.
Two sanitizers included in Undefined Behavior Sanitizer (UBSan) will be our focus – Integer Overflow Sanitizer (IntSan) and BoundsSanitizer (BoundSan). These have been widely deployed in Android userspace for years following a data-driven approach. These two are well suited for bare-metal environments such as the baseband since they do not require support from the OS or specific architecture features, and so are generally supported for all Clang targets.
IntSan causes signed and unsigned integer overflows to abort execution unless the overflow is made explicit. While unsigned integer overflows are technically defined behavior, it can often lead to unintentional behavior and vulnerabilities – especially when they’re used to index into arrays.
As both intentional and unintentional overflows are likely present in most code bases, IntSan may require refactoring and annotating the code base to prevent intentional or benign overflows from trapping (which we consider a false positive for our purposes). Overflows which need to be addressed can be uncovered via testing (see the Deploying Sanitizers section)
BoundSan inserts instrumentation to perform bounds checks around some array accesses. These checks are only added if the compiler cannot prove at compile time that the access will be safe and if the size of the array will be known at runtime, so that it can be checked against. Note that this will not cover all array accesses as the size of the array may not be known at runtime, such as function arguments which are arrays.
As long as the code is correctly written C/C++, BoundSan should produce no false positives. Any violations discovered when first enabling BoundSan is at least a bug, if not a vulnerability. Resolving even those which aren’t exploitable can greatly improve stability and code quality.
Adopting modern mitigations also means adopting (and maintaining) modern toolchains. The benefits of this go beyond utilizing sanitizers however. Maintaining an old toolchain is not free and entails hidden opportunity costs. Toolchains contain bugs which are addressed in subsequent releases. Newer toolchains bring new performance optimizations, valuable in the highly constrained bare-metal environment that basebands operate in. Security issues can even exist in the generated code of out-of-date compilers.
Maintaining a modern up-to-date toolchain for the baseband entails some costs in terms of maintenance, especially at first if the toolchain is particularly old, but over time the benefits, as outlined above, outweigh the costs.
Both BoundSan and IntSan have a measurable performance overhead. Although we were able to significantly reduce this overhead in the past (for example to less than 1% in media codecs), even very small increases in CPU load can have a substantial impact in some environments.
Enabling sanitizers over the entire codebase provides the most benefit, but enabling them in security-critical attack surfaces can serve as a first step in an incremental deployment. For example:
In the particular case of 2G, the best strategy is to disable the stack altogether by supporting Android’s “2G toggle”. However, 2G is still a necessary mobile access technology in certain parts of the world and some users might need to have this legacy protocol enabled.
Having a clear plan for deployment of sanitizers saves a lot of time and effort. We think of the deployment process as having three stages:
We also introduce two modes in which sanitizers should be run: diagnostics mode and trapping mode. These will be discussed in the following sections, but briefly: diagnostics mode recovers from violations and provides valuable debug information, while trapping mode actively mitigates vulnerabilities by trapping execution on violations.
To successfully ship these sanitizers, any benign integer overflows must be made explicit and accidental out-of-bounds accesses must be addressed. These will have to be uncovered through testing. The higher the code coverage your tests provide, the more issues you can uncover at this stage and the easier deployment will be later on.
To diagnose violations uncovered in testing, sanitizers can emit calls to runtime handlers with debug information such as the file, line number, and values leading to the violation. Sanitizers can optionally continue execution after a violation has occurred, allowing multiple violations to be discovered in a single test run. We refer to using the sanitizers in this way as running them in “diagnostics mode”. Diagnostics mode is not intended for production as it provides no security benefits and adds high overhead.
Diagnostics mode for the sanitizers can be set using the following flags:
-fsanitize=signed-integer-overflow,unsigned-integer-overflow,bounds -fsanitize-recover=all
Since Clang does not provide a UBSan runtime for bare-metal targets, a runtime will need to be defined and provided at link time:
// integer overflow handlers __ubsan_handle_add_overflow(OverflowData *data, ValueHandle lhs, ValueHandle rhs) __ubsan_handle_sub_overflow(OverflowData *data, ValueHandle lhs, ValueHandle rhs) __ubsan_handle_mul_overflow(OverflowData *data, ValueHandle lhs, ValueHandle rhs) __ubsan_handle_divrem_overflow(OverflowData *data, ValueHandle lhs, ValueHandle rhs) __ubsan_handle_negate_overflow(OverflowData *data, ValueHandle old_val) // boundsan handler __ubsan_handle_out_of_bounds_overflow(OverflowData *data, ValueHandle old_val)
As an example, see the default Clang implementation; the Linux Kernels implementation may also be illustrative.
With the runtime defined, enable the sanitizer over the entire baseband codebase and run all available tests to uncover and address any violations. Vulnerabilities should be patched, and overflows should either be refactored or made explicit through the use of checked arithmetic builtins which do not trigger sanitizer violations. Certain functions which are expected to have intentional overflows (such as cryptographic functions) can be preemptively excluded from sanitization (see next section).
Aside from uncovering security vulnerabilities, this stage is highly effective at uncovering code quality and stability bugs that could result in instability on user devices.
Once violations have been addressed and tests are no longer uncovering new violations, the next stage can begin.
Once shallow violations have been addressed, benchmarks can be run and the overhead from the sanitizers (performance, code size, memory footprint) can be measured.
Measuring overhead must be done using production flags – namely “trapping mode”, where violations cause execution to abort. The diagnostics runtime used in the first stage carries significant overhead and is not indicative of the actual performance sanitizer overhead.
Trapping mode can be enabled using the following flags:
-fsanitize=signed-integer-overflow,unsigned-integer-overflow,bounds -fsanitize-trap=all
Most of the overhead is likely due to a small handful of “hot functions”, for example those with tight long-running loops. Fine-grained per-function performance metrics (similar to what Simpleperf provides for Android), allows comparing metrics before and after sanitizers and provides the easiest means to identify hot functions. These functions can either be refactored or, after manual inspection to verify that they are safe, have sanitization disabled.
Sanitizers can be disabled either inline in the source or through the use of ignorelists and the -fsanitize-ignorelist flag.
The physical layer code, with its extremely tight performance margins and lower chance of exploitable vulnerabilities, may be a good candidate to disable sanitization wholesale if initial performance seems prohibitive.
With overhead minimized and shallow bugs resolved, the final stage is enabling the sanitizers in trapping mode to mitigate vulnerabilities.
We strongly recommend a long period of internal soak in pre-production with test populations to uncover any remaining violations not discovered in testing. The more thorough the test coverage and length of the soak period, the less risk there will be from undiscovered violations.
As above, the configuration for trapping mode is as follows:
Having infrastructure in place to collect bug reports which result from any undiscovered violations can help minimize the risk they present.
The benefits from deploying sanitizers in your existing code base are tangible, however ultimately they address only the lowest hanging fruit and will not result in a code base free of vulnerabilities. Other classes of memory safety vulnerabilities remain unaddressed by these sanitizers. A longer term solution is to begin transitioning today to memory-safe languages such as Rust.
Rust is ready for bare-metal environments such as the baseband, and we are already using it in other bare-metal components in Android. There is no need to rewrite everything in Rust, as Rust provides a strong C FFI support and easily interfaces with existing C codebases. Just writing new code in Rust can rapidly reduce the number of memory safety vulnerabilities. Rewrites should be limited/prioritized only for the most critical components, such as complex parsers handling untrusted data.
The Android team has developed a Rust training meant to help experienced developers quickly ramp up Rust fundamentals. An entire day for bare-metal Rust is included, and the course has been translated to a number of different languages.
While the Rust compiler may not explicitly support your bare-metal target, because it is a front-end for LLVM, any target supported by LLVM can be supported in Rust through custom target definitions.
As the high-level operating system becomes a more difficult target for attackers to successfully exploit, we expect that lower level components such as the baseband will attract more attention. By using modern toolchains and deploying exploit mitigation technologies, the bar for attacking the baseband can be raised as well. If you have any questions, let us know – we’re here to help!
Systems such as Gmail, YouTube and Google Play rely on text classification models to identify harmful content including phishing attacks, inappropriate comments, and scams. These types of texts are harder for machine learning models to classify because bad actors rely on adversarial text manipulations to actively attempt to evade the classifiers. For example, they will use homoglyphs, invisible characters, and keyword stuffing to bypass defenses.
To help make text classifiers more robust and efficient, we’ve developed a novel, multilingual text vectorizer called RETVec (Resilient & Efficient Text Vectorizer) that helps models achieve state-of-the-art classification performance and drastically reduces computational cost. Today, we’re sharing how RETVec has been used to help protect Gmail inboxes.
Strengthening the Gmail Spam Classifier with RETVec
Figure 1. RETVec-based Gmail Spam filter improvements.
Over the past year, we battle-tested RETVec extensively inside Google to evaluate its usefulness and found it to be highly effective for security and anti-abuse applications. In particular, replacing the Gmail spam classifier’s previous text vectorizer with RETVec allowed us to improve the spam detection rate over the baseline by 38% and reduce the false positive rate by 19.4%. Additionally, using RETVec reduced the TPU usage of the model by 83%, making the RETVec deployment one of the largest defense upgrades in recent years. RETVec achieves these improvements by sporting a very lightweight word embedding model (~200k parameters), allowing us to reduce the Transformer model’s size at equal or better performance, and having the ability to split the computation between the host and TPU in a network and memory efficient manner.
RETVec Benefits
RETVec achieves these improvements by combining a novel, highly-compact character encoder, an augmentation-driven training regime, and the use of metric learning. The architecture details and benchmark evaluations are available in our NeurIPS 2023 paper and we open-source RETVec on Github.
Due to its novel architecture, RETVec works out-of-the-box on every language and all UTF-8 characters without the need for text preprocessing, making it the ideal candidate for on-device, web, and large-scale text classification deployments. Models trained with RETVec exhibit faster inference speed due to its compact representation. Having smaller models reduces computational costs and decreases latency, which is critical for large-scale applications and on-device models.
Figure 1. RETVec architecture diagram.
Models trained with RETVec can be seamlessly converted to TFLite for mobile and edge devices, as a result of a native implementation in TensorFlow Text. For web application model deployment, we provide a TensorflowJS layer implementation that is available on Github and you can check out a demo web page running a RETVec-based model.
Figure 2. Typo resilience of text classification models trained from scratch using different vectorizers.
RETVec is a novel open-source text vectorizer that allows you to build more resilient and efficient server-side and on-device text classifiers. The Gmail spam filter uses it to help protect Gmail inboxes against malicious emails.
If you would like to use RETVec for your own use cases or research, we created a tutorial to help you get started.
This research was conducted by Elie Bursztein, Marina Zhang, Owen Vallis, Xinyu Jia, and Alexey Kurakin. We would like to thank Gengxin Miao, Brunno Attorre, Venkat Sreepati, Lidor Avigad, Dan Givol, Rishabh Seth and Melvin Montenegro and all the Googlers who contributed to the project.