For more than a decade, memory safety vulnerabilities have consistently represented more than 65% of vulnerabilities across products, and across the industry. On Android, we’re now seeing something different - a significant drop in memory safety vulnerabilities and an associated drop in the severity of our vulnerabilities.
Looking at vulnerabilities reported in the Android security bulletin, which includes critical/high severity vulnerabilities reported through our vulnerability rewards program (VRP) and vulnerabilities reported internally, we see that the number of memory safety vulnerabilities have dropped considerably over the past few years/releases. From 2019 to 2022 the annual number of memory safety vulnerabilities dropped from 223 down to 85.
This drop coincides with a shift in programming language usage away from memory unsafe languages. Android 13 is the first Android release where a majority of new code added to the release is in a memory safe language.
While correlation doesn’t necessarily mean causation, it’s interesting to note that the percent of vulnerabilities caused by memory safety issues seems to correlate rather closely with the development language that’s used for new code. This matches the expectations published in our blog post 2 years ago about the age of memory safety vulnerabilities and why our focus should be on new code, not rewriting existing components. Of course there may be other contributing factors or alternative explanations. However, the shift is a major departure from industry-wide trends that have persisted for more than a decade (and likely longer) despite substantial investments in improvements to memory unsafe languages.We continue to invest in tools to improve the safety of our C/C++. Over the past few releases we’ve introduced the Scudo hardened allocator, HWASAN, GWP-ASAN, and KFENCE on production Android devices. We’ve also increased our fuzzing coverage on our existing code base. Vulnerabilities found using these tools contributed both to prevention of vulnerabilities in new code as well as vulnerabilities found in old code that are included in the above evaluation. These are important tools, and critically important for our C/C++ code. However, these alone do not account for the large shift in vulnerabilities that we’re seeing, and other projects that have deployed these technologies have not seen a major shift in their vulnerability composition. We believe Android’s ongoing shift from memory-unsafe to memory-safe languages is a major factor.
In Android 12 we announced support for the Rust programming language in the Android platform as a memory-safe alternative to C/C++. Since then we’ve been scaling up our Rust experience and usage within the Android Open Source Project (AOSP).As we noted in the original announcement, our goal is not to convert existing C/C++ to Rust, but rather to shift development of new code to memory safe languages over time.
In Android 13, about 21% of all new native code (C/C++/Rust) is in Rust. There are approximately 1.5 million total lines of Rust code in AOSP across new functionality and components such as Keystore2, the new Ultra-wideband (UWB) stack, DNS-over-HTTP3, Android’s Virtualization framework (AVF), and various other components and their open source dependencies. These are low-level components that require a systems language which otherwise would have been implemented in C++.
To date, there have been zero memory safety vulnerabilities discovered in Android’s Rust code.
We don’t expect that number to stay zero forever, but given the volume of new Rust code across two Android releases, and the security-sensitive components where it’s being used, it’s a significant result. It demonstrates that Rust is fulfilling its intended purpose of preventing Android’s most common source of vulnerabilities. Historical vulnerability density is greater than 1/kLOC (1 vulnerability per thousand lines of code) in many of Android’s C/C++ components (e.g. media, Bluetooth, NFC, etc). Based on this historical vulnerability density, it’s likely that using Rust has already prevented hundreds of vulnerabilities from reaching production.
Operating system development requires accessing resources that the compiler cannot reason about. For memory-safe languages this means that an escape hatch is required to do systems programming. For Java, Android uses JNI to access low-level resources. When using JNI, care must be taken to avoid introducing unsafe behavior. Fortunately, it has proven significantly simpler to review small snippets of C/C++ for safety than entire programs. There are no pure Java processes in Android. It’s all built on top of JNI. Despite that, memory safety vulnerabilities are exceptionally rare in our Java code.
Rust likewise has the unsafe{} escape hatch which allows interacting with system resources and non-Rust code. Much like with Java + JNI, using this escape hatch comes with additional scrutiny. But like Java, our Rust code is proving to be significantly safer than pure C/C++ implementations. Let’s look at the new UWB stack as an example.
There are exactly two uses of unsafe in the UWB code: one to materialize a reference to a Rust object stored inside a Java object, and another for the teardown of the same. Unsafe was actively helpful in this situation because the extra attention on this code allowed us to discover a possible race condition and guard against it.
In general, use of unsafe in Android’s Rust appears to be working as intended. It’s used rarely, and when it is used, it’s encapsulating behavior that’s easier to reason about and review for safety.
Mobile devices have limited resources and we’re always trying to make better use of them to provide users with a better experience (for example, by optimizing performance, improving battery life, and reducing lag). Using memory unsafe code often means that we have to make tradeoffs between security and performance, such as adding additional sandboxing, sanitizers, runtime mitigations, and hardware protections. Unfortunately, these all negatively impact code size, memory, and performance.
Using Rust in Android allows us to optimize both security and system health with fewer compromises. For example, with the new UWB stack we were able to save several megabytes of memory and avoid some IPC latency by running it within an existing process. The new DNS-over-HTTP/3 implementation uses fewer threads to perform the same amount of work by using Rust’s async/await feature to process many tasks on a single thread in a safe manner.
The number of vulnerabilities reported in the bulletin has stayed somewhat steady over the past 4 years at around 20 per month, even as the number of memory safety vulnerabilities has gone down significantly. So, what gives? A few thoughts on that.
Memory safety vulnerabilities disproportionately represent our most severe vulnerabilities. In 2022, despite only representing 36% of vulnerabilities in the security bulletin, memory-safety vulnerabilities accounted for 86% of our critical severity security vulnerabilities, our highest rating, and 89% of our remotely exploitable vulnerabilities. Over the past few years, memory safety vulnerabilities have accounted for 78% of confirmed exploited “in-the-wild” vulnerabilities on Android devices.
Many vulnerabilities have a well defined scope of impact. For example, a permissions bypass vulnerability generally grants access to a specific set of information or resources and is generally only reachable if code is already running on the device. Memory safety vulnerabilities tend to be much more versatile. Getting code execution in a process grants access not just to a specific resource, but everything that that process has access to, including attack surface to other processes. Memory safety vulnerabilities are often flexible enough to allow chaining multiple vulnerabilities together. The high versatility is perhaps one reason why the vast majority of exploit chains that we have seen use one or more memory safety vulnerabilities.With the drop in memory safety vulnerabilities, we’re seeing a corresponding drop in vulnerability severity.
Despite most of the existing code in Android being in C/C++, most of Android’s API surface is implemented in Java. This means that Java is disproportionately represented in the OS’s attack surface that is reachable by apps. This provides an important security property: most of the attack surface that’s reachable by apps isn’t susceptible to memory corruption bugs. It also means that we would expect Java to be over-represented when looking at non-memory safety vulnerabilities. It’s important to note however that types of vulnerabilities that we’re seeing in Java are largely logic bugs, and as mentioned above, generally lower in severity. Going forward, we will be exploring how Rust’s richer type system can help prevent common types of logic bugs as well.
With the vulnerability types we’re seeing now, Google’s ability to detect and prevent misuse is considerably better. Apps are scanned to help detect misuse of APIs before being published on the Play store and Google Play Protect warns users if they have abusive apps installed.
Migrating away from C/C++ is challenging, but we’re making progress. Rust use is growing in the Android platform, but that’s not the end of the story. To meet the goals of improving security, stability, and quality Android-wide, we need to be able to use Rust anywhere in the codebase that native code is required. We’re implementing userspace HALs in Rust. We’re adding support for Rust in Trusted Applications. We’ve migrated VM firmware in the Android Virtualization Framework to Rust. With support for Rust landing in Linux 6.1 we’re excited to bring memory-safety to the kernel, starting with kernel drivers.
As Android migrates away from C/C++ to Java/Kotlin/Rust, we expect the number of memory safety vulnerabilities to continue to fall. Here’s to a future where memory corruption bugs on Android are rare!
We believe that security and transparency are paramount pillars for electronic products connected to the Internet. Over the past year, we’ve been excited to see more focused activity across policymakers, industry partners, developers, and public interest advocates around raising the security and transparency bar for IoT products.
That said, the details of IoT product labeling - the definition of labeling, what labeling needs to convey in terms of security and privacy, where the label should reside, and how to achieve consumer acceptance, are still open for debate. Google has also been considering these core questions for a long time. As an operating system, IoT product provider, and the maintainer of multiple large ecosystems, we see firsthand how critical these details will be to the future of the IoT. In an effort to be a catalyst for collaboration and transparency, today we’re sharing our proposed list of principles around IoT security labeling.
Setting the Stage: Defining IoT Labeling
IoT labeling is a complex and nuanced topic, so as an industry, we should first align on a set of labeling definitions that could help reduce potential fragmentation and offer a harmonized approach that could drive a desired outcome:
Proposed Principles for IoT Security Labeling Schemes
We believe in five core principles for IoT labeling schemes. These principles will help increase transparency against the full baseline of security criteria for IoT. These principles will also increase competition in security and push manufacturers to offer products with effective security protections, increase transparency, and help generate higher levels of assurance of protection over time.
1. A printed label must not imply trust
Unlike food labels, digital security labels must be “live” labels, where security/privacy status is conveyed on a central maintained website, which ideally would be the same site hosting the evaluation scheme. A physical label, either printed on a box or visible in an app, can be used if and only if it encourages users to visit the website (e.g. scan a QR code or click a link) to obtain the real-time status.
At any point in time, a digital product may become unsafe for use. For example, if a critical, in-the-wild, remote exploit of a product is discovered and cannot be mitigated (e.g. via a patch), then it may be necessary to change that product’s status from safe to unsafe.
Printed labels, if they convey trust implicitly such as, “certified to NNN standard” or, “3 stars”, run the danger of influencing consumers to make harmful decisions. A consumer may purchase a webcam with a “3-star” security label only to find when they return home the product has non-mitigatable vulnerabilities that make it unsafe. Or, a product may sit on a shelf long enough to become non-compliant or unsafe. Labeling programs should help consumers make better security decisions. The dangers around a printed “trust me” label will in some circumstances, mislead consumers.
2. Labels must reference strong international evaluation schemes
The challenge of utilizing a labeling scheme is not the physical manifestation of the label but rather ensuring that the label references a security/privacy status/posture that is maintained by a trustworthy security/privacy evaluation scheme, such as the ones being developed by the Connectivity Standards Alliance (CSA) and GSMA. Both of these organizations are actively developing IoT security/privacy evaluation schemes that reference well-regarded standards, including recent IoT baseline security guidance from NIST, ETSI, ISO, and OWASP. Some important requirements for evaluation schemes leveraged by a national labeling program include:
Strong governance: The NGO must have strong governance. For example, NGOs that house both a scheme and their own in-house evaluation lab introduce potential conflicts of interest that should be avoided.
Strong track record for managing evaluation schemes at scale: Managing a high quality, global scheme is hard. National authorities have struggled at this for many years, especially in the consumer realm. An NGO that has no prior track record of managing a scheme with significant global adoption is unlikely to be sufficiently trustworthy for a national labeling scheme to reference. CSA and GSMA have long track records of managing global schemes that have stood the test of time.
Choice with a high quality bar: The world needs a small set of high quality evaluation schemes that can act as the hub within a hub and spoke model for enabling national labeling schemes across the globe. Evaluation schemes will authorize a range of labs for lab-tested results, providing price competition for lab engagements. We need more than one scheme to encourage competition among evaluation schemes, as they too will levy fees for membership, certification, and monitoring. However, balance is key, as too many schemes could be challenging for governments to monitor and trust. Setting a high bar for governance and track record, as described above, will help curate global evaluation scheme choices.
International participation: National labeling schemes must recognize that many manufacturers sell products across the world. A national label that does not reference NGOs that serve the global community will force multiple inconsistent national labeling schemes that are prohibitively expensive for small and medium size product developers. Misaligned or non-harmonized national efforts may become a significant barrier to entry for smaller vendors and run counter to the intended goals of competition-enhancing policies in their respective markets.
Assurance maintenance: The NGO evaluation scheme must provide a mechanism for independent researchers to pressure test conformance claims made by manufacturers. Moment-in-time certifications have historically plagued security evaluation schemes, and for cost reasons, forced annual re-certifications are not the answer either. For the vast majority of consumer products, we should rely on crowdsourced research to identify weaknesses that may question a certification result. This approach has succeeded in helping to maintain the security of numerous global products and platforms and is especially needed to help monitor the results of self-attestation certifications that will be needed in any national scale labeling program. This is also an area where federal funding may be most needed; security bounty programs will add even more incentive for the security community to pressure test evaluation scheme results and hold the entire labeling program supply chain accountable. These reward programs are also a great way to recruit more people into the cybersecurity field.
3. A minimum security baseline must be coupled with flexibility above it
A minimum security baseline must be coupled with flexibility to define additional requirements and/or levels to accelerate ecosystem improvements. Security labeling is nascent, and most schemes are focused on common sense baseline requirement standards. These standards will set an important minimum bar for digital security, reducing the likelihood that consumers will be exposed to truly poor security practices. However, we should never say things like, “we need a labeling scheme to ensure that digital products are secure.” Security is not a binary state. Applying a minimum set of best practices will not magically make a product free of vulnerabilities. But it will discourage the most common security foibles. Furthermore, it is folly to expect that baseline security standards will protect against advanced persistent threat actors. Rather, they’ll hopefully provide broad protection against common opportunistic attackers. The Mirai botnet attack was so successful because so many digital products lack the most rudimentary security functionality: the ability to apply a security update in the field.
Over time we need to do better. Security evaluation schemes need to be sufficiently flexible to allow for additional security functional requirements to be measured and rated across products. For example, the current baseline security requirements do not cover things like the strength of a biometric authenticator (important for phones and a growing range of consumer digital products) nor do they provide a standardized method for comparing the relative strength of security update policies (e.g. a product that receives regular updates for five years should be valued more highly by consumers than one that receives updates for two years). Communities that focus on specific vertical markets of product families are motivated to create security functional requirement profiles (and labels) that go above and beyond the baseline and are more tailored for that product category. Labeling schemes must allow for this flexibility, as long as profile compliance is managed by high quality evaluation schemes.
Similarly, in addition to functionality such as biometrics and update frequency, labels need to allow for assurance levels, which answer the question, “how much confidence should we have in this product’s security functionality claims?” For example, emerging consumer evaluation schemes may permit a self-attestation of conformance or a lab test that validates basic security functionality. These kinds of attestations yield relatively low assurance, but still better than none. Today’s schemes do not allow for an assessment that emulates a high potential attacker trying to break the system’s security functionality. To date, due to cost and complexity, high potential attacker vulnerability assessments have been limited to a vanishingly small number of products, including secure elements and small hypervisors. Yet for a nation’s most critical systems, such as connected medical devices, cars, and applications that manage sensitive data for millions of consumers, a higher level of assurance will be needed, and any labeling scheme must not preclude future extensions that offer higher levels of assurance.
4. Broad-based transparency is just as important as the minimum bar
While it is desirable that labeling schemes provide consumers with simple guidance on safety, the desire for such a simple bar forces it to be the lowest common denominator for security capability so as not to preclude large portions of the market. It is equally important that labeling schemes increase transparency in security. So much of the discussion around labeling schemes has focused on selecting the best possible minimum bar rather than promoting transparency of security capability, regardless of what minimum bar a product may meet. This is short-sighted and fails to learn from many other consumer rating schemes (e.g. Consumer Reports) that have successfully provided transparency around a much wider range of product capabilities over time.
Again, while a common baseline is a good place to start, we must also encourage the use of more comprehensive requirement specifications developed by high-quality NGO standards bodies and/or schemes against which products can be assessed. The goal of this method is not to mandate every requirement above the baseline, but rather to mandate transparency of compliance against those requirements. Similar to many other consumer rating schemes, the transparency across a wide range of important capabilities (e.g. the biometrics example above) will enable easy side-by-side comparison during purchasing decisions, which will act as the tide to raise all boats, driving product developers to compete with each other in security. This already happens with speeds and feeds, battery life, energy consumption, and many other features that people care about. For example, the requirement for transparency could classify the strength of the biometric based on spoof / presentation attack detection rate, which we measure for Android. If we develop more comprehensive transparency in our labeling scheme, consumers will learn and care about a wider range of security capabilities that today remain below the veil; that awareness will drive demand for product developers to do better.
5. Labeling schemes are useless without adoption incentive
Transparency is the core concept that can raise demand and improve supply of better security across the IoT. However, what will cause products to be evaluated so that security capability data will be published and made easily consumable? After thirty years of the world wide web and connected digital technology, it is clear that simply expecting product developers to “do the right thing” for security is insufficient.
“Voluntary” regimes will attract the same developers that are already doing good security work and depend on doing so for their customers and brands. Security is, on average, poor across the IoT market because product developers optimize for profitability, and the economic impact of poor security is usually not sufficiently high to move the needle. Many avenues can lead to increased economic incentives for improved security. That means a mix of carrots and sticks will be necessary to incentivize developers to increase the security of their products.
National labeling schemes should focus on a few of the biggest market movers, in order of decreasing impact:
National mandate: Some national governments are moving towards legislation or executive orders that will require common baseline security requirements to be met, with corresponding labeling to differentiate compliant products from those not covered by the mandate. National mandates can drive improved behavior at scale. However, mandating a poor labeling scheme can do more harm than good. For example, if every nation creates a bespoke evaluation scheme, small and medium size developers would be priced out of the market due to the need to recertify and label their products across all these schemes. Not only will non-harmonized approaches harm industry financially, it will also inhibit innovation as developers create less inclusive products to avoid nations with painful labeling regimes.
National mandates and labeling schemes must reference broadly applicable, high quality, NGO standards and schemes (as described above) so that they can be reused across multiple national labeling schemes. Global normalization and cross-recognition is not a nice-to-have, national schemes will fail if they do not solve for this important economic reality upfront. Ideally, government officials who care about a successful national labeling scheme should be involved to nurture and guide the NGO schemes that are trying to solve this problem globally.
Retailers: Retailers of digital products could have a huge impact by preferencing baseline standards compliance for digital products. In its most impactful form, the retailer would mandate compliance for all products listed for sale. The larger the retailer, the more impact is possible. Less broad, but still extremely impactful, would be providing visual labeling and/or search and discovery preferences for products that meet the requirements specified in high quality security evaluation schemes.
Platform developers: Many digital products exist as part of platforms, such as devices built on the Android Open Source Project (AOSP) platform or apps published on the Google Play app store platform. In addition, interoperability standards such as Matter and Bluetooth act as platforms, certifying products that meet those interoperability standards. All of these platform developers may use security compliance within larger certification, compliance, and business incentive programs that can drive adoption at
scale. The impact depends on the size and scale of the platform and whether the carrots provided by platform providers are sufficiently attractive.
Continuing to Strive For Collaboration, Standardization, and Transparency
Our goal is to increase transparency against the full baseline of security criteria for the IoT over time. This will help drive “competition” in security and push manufacturers to offer products with more robust security protections. But we don’t want to stop at just increasing transparency. We will also strive to build realistic higher levels of assurance. As labeling efforts gain steam, we are hopeful that public sector and industry can work together to drive global harmonization to prevent fragmentation, and we hope to provide our expertise and act as a valued partner to governments as they develop policies to help their countries stay ahead of the latest threats in IoT. We look forward to our continued partnership with governments and industry to reduce complexity and increase innovation while improving global cybersecurity.
---------------------------------------------------------------------------------------------
See also: Google testimony on security labeling and evaluation schemes in UK ParliamentSee also: Google participated in a White House strategic discussion on IoT Security Labeling
Supply chain security is at the fore of the industry’s collective consciousness. We’ve recently seen a significant rise in software supply chain attacks, a Log4j vulnerability of catastrophic severity and breadth, and even an Executive Order on Cybersecurity.
It is against this background that Google is seeking contributors to a new open source project called GUAC (pronounced like the dip). GUAC, or Graph for Understanding Artifact Composition, is in the early stages yet is poised to change how the industry understands software supply chains. GUAC addresses a need created by the burgeoning efforts across the ecosystem to generate software build, security, and dependency metadata. True to Google’s mission to organize and make the world’s information universally accessible and useful, GUAC is meant to democratize the availability of this security information by making it freely accessible and useful for every organization, not just those with enterprise-scale security and IT funding.
Thanks to community collaboration in groups such as OpenSSF, SLSA, SPDX, CycloneDX, and others, organizations increasingly have ready access to:
These data are useful on their own, but it’s difficult to combine and synthesize the information for a more comprehensive view. The documents are scattered across different databases and producers, are attached to different ecosystem entities, and cannot be easily aggregated to answer higher-level questions about an organization’s software assets.
To help address this issue we’ve teamed up with Kusari, Purdue University, and Citi to create GUAC, a free tool to bring together many different sources of software security metadata. We’re excited to share the project’s proof of concept, which lets you query a small dataset of software metadata including SLSA provenance, SBOMs, and OpenSSF Scorecards.
Graph for Understanding Artifact Composition (GUAC) aggregates software security metadata into a high fidelity graph database—normalizing entity identities and mapping standard relationships between them. Querying this graph can drive higher-level organizational outcomes such as audit, policy, risk management, and even developer assistance.
Conceptually, GUAC occupies the “aggregation and synthesis” layer of the software supply chain transparency logical model:
GUAC has four major areas of functionality:
A CISO or compliance officer in an organization wants to be able to reason about the risk of their organization. An open source organization like the Open Source Security Foundation wants to identify critical libraries to maintain and secure. Developers need richer and more trustworthy intelligence about the dependencies in their projects.
The good news is, increasingly one finds the upstream supply chain already enriched with attestations and metadata to power higher-level reasoning and insights. The bad news is that it is difficult or impossible today for software consumers, operators, and administrators to gather this data into a unified view across their software assets.
To understand something complex like the blast radius of a vulnerability, one needs to trace the relationship between a component and everything else in the portfolio—a task that could span thousands of metadata documents across hundreds of sources. In the open source ecosystem, the number of documents could reach into the millions.
GUAC aggregates and synthesizes software security metadata at scale and makes it meaningful and actionable. With GUAC in hand, we will be able to answer questions at three important stages of software supply chain security:
Get Involved
GUAC is an Open Source project on Github, and we are excited to get more folks involved and contributing (read the contributor guide to get started)! The project is still in its early stages, with a proof of concept that can ingest SLSA, SBOM, and Scorecard documents and support simple queries and exploration of software metadata. The next efforts will focus on scaling the current capabilities and adding new document types for ingestion. We welcome help and contributions of code or documentation.
Since the project will be consuming documents from many different sources and formats, we have put together a group of “Technical Advisory Members'' to help advise the project. These members include representation from companies and groups such as SPDX, CycloneDX Anchore, Aquasec, IBM, Intel, and many more. If you’re interested in participating as a contributor or advisor representing end users’ needs—or the sources of metadata GUAC consumes—you can register your interest in the relevant GitHub issue.
The GUAC team will be showcasing the project at Kubecon NA 2022 next week. Come by our session if you’ll be there and have a chat with us—we’d be happy to talk in person or virtually!
We are excited to announce passkey support on Android and Chrome for developers to test today, with general availability following later this year. In this post we cover details on how passkeys stored in the Google Password Manager are kept secure. See our post on the Android Developers Blog for a more general overview.
Passkeys are a safer and more secure alternative to passwords. They also replace the need for traditional 2nd factor authentication methods such as text message, app based one-time codes or push-based approvals. Passkeys use public-key cryptography so that data breaches of service providers don't result in a compromise of passkey-protected accounts, and are based on industry standard APIs and protocols to ensure they are not subject to phishing attacks.
Passkeys are the result of an industry-wide effort. They combine secure authentication standards created within the FIDO Alliance and the W3C Web Authentication working group with a common terminology and user experience across different platforms, recoverability against device loss, and a common integration path for developers. Passkeys are supported in Android and other leading industry client OS platforms.
A single passkey identifies a particular user account on some online service. A user has different passkeys for different services. The user's operating systems, or software similar to today's password managers, provide user-friendly management of passkeys. From the user's point of view, using passkeys is very similar to using saved passwords, but with significantly better security.
The main ingredient of a passkey is a cryptographic private key. In most cases, this private key lives only on the user's own devices, such as laptops or mobile phones. When a passkey is created, only its corresponding public key is stored by the online service. During login, the service uses the public key to verify a signature from the private key. This can only come from one of the user's devices. Additionally, the user is also required to unlock their device or credential store for this to happen, preventing sign-ins from e.g. a stolen phone.
To address the common case of device loss or upgrade, a key feature enabled by passkeys is that the same private key can exist on multiple devices. This happens through platform-provided synchronization and backup.
On Android, the Google Password Manager provides backup and sync of passkeys. This means that if a user sets up two Android devices with the same Google Account, passkeys created on one device are available on the other. This applies both to the case where a user has multiple devices simultaneously, for example a phone and a tablet, and the more common case where a user upgrades e.g. from an old Android phone to a new one.
Passkeys in the Google Password Manager are always end-to-end encrypted: When a passkey is backed up, its private key is uploaded only in its encrypted form using an encryption key that is only accessible on the user's own devices. This protects passkeys against Google itself, or e.g. a malicious attacker inside Google. Without access to the private key, such an attacker cannot use the passkey to sign in to its corresponding online account.
Additionally, passkey private keys are encrypted at rest on the user's devices, with a hardware-protected encryption key.
Creating or using passkeys stored in the Google Password Manager requires a screen lock to be set up. This prevents others from using a passkey even if they have access to the user's device, but is also necessary to facilitate the end-to-end encryption and safe recovery in the case of device loss.
When a user sets up a new Android device by transferring data from an older device, existing end-to-end encryption keys are securely transferred to the new device. In some cases, for example, when the older device was lost or damaged, users may need to recover the end-to-end encryption keys from a secure online backup.
To recover the end-to-end encryption key, the user must provide the lock screen PIN, password, or pattern of another existing device that had access to those keys. Note, that restoring passkeys on a new device requires both being signed in to the Google Account and an existing device's screen lock.
Since screen lock PINs and patterns, in particular, are short, the recovery mechanism provides protection against brute-force guessing. After a small number of consecutive, incorrect attempts to provide the screen lock of an existing device, it can no longer be used. This number is always 10 or less, but for safety reasons we may block attempts before that number is reached. Screen locks of other existing devices may still be used.
If the maximum number of attempts is reached for all existing devices on file, e.g. when a malicious actor tries to brute force guess, the user may still be able to recover if they still have access to one of the existing devices and knows its screen lock. By signing in to the existing device and changing its screen lock PIN, password or pattern, the count of invalid recovery attempts is reset. End-to-end encryption keys can then be recovered on the new device by entering the new screen lock of the existing device.
Screen lock PINs, passwords or patterns themselves are not known to Google. The data that allows Google to verify correct input of a device's screen lock is stored on Google's servers in secure hardware enclaves and cannot be read by Google or any other entity. The secure hardware also enforces the limits on maximum guesses, which cannot exceed 10 attempts, even by an internal attack. This protects the screen lock information, even from Google.
When the screen lock is removed from a device, the previously configured screen lock may still be used for recovery of end-to-end encryption keys on other devices for a period of time up to 64 days. If a user believes their screen lock is compromised, the safer option is to configure a different screen lock (e.g. a different PIN). This disables the previous screen lock as a recovery factor immediately, as long as the user is online and signed in on the device.
If end-to-end encryption keys were not transferred during device setup, the recovery process happens automatically the first time a passkey is created or used on the new device. In most cases, this only happens once on each new device.
From the user's point of view, this means that when using a passkey for the first time on the new device, they will be asked for an existing device's screen lock in order to restore the end-to-end encryption keys, and then for the current device's screen lock or biometric, which is required every time a passkey is used.
Passkeys are an instance of FIDO multi-device credentials. Google recognizes that in certain deployment scenarios, relying parties may still require signals about the strong device binding that traditional FIDO credentials provide, while taking advantage of the recoverability and usability of passkeys.
To address this, passkeys on Android support the proposed Device-bound Public Key WebAuthn extension (devicePubKey). If this extension is requested when creating or using passkeys on Android, relying parties will receive two signatures in the result: One from the passkey private key, which may exist on multiple devices, and an additional signature from a second private key that only exists on the current device. This device-bound private key is unique to the passkey in question, and each response includes a copy of the corresponding device-bound public key.
Observing two passkey signatures with the same device-bound public key is a strong signal that the signatures are generated by the same device. On the other hand, if a relying party observes a device-bound public key it has not seen before, this may indicate that the passkey has been synced to a new device.
On Android, device-bound private keys are generated in the device's trusted execution environment (TEE), via the Android Keystore API. This provides hardware-backed protections against exfiltration of the device-bound private keys to other devices. Device-bound private keys are not backed up, so e.g. when a device is factory reset and restored from a prior backup, its device-bound key pairs will be different.
The device-bound key pair is created and stored on-demand. That means relying parties can request the devicePubKey extension when getting a signature from an existing passkey, even if devicePubKey was not requested when the passkey was created.
Every day, billions of people around the world trust Google products to enrich their lives and provide helpful features – across mobile devices, smart home devices, health and fitness devices, and more. We keep more people safe online than anyone else in the world, with products that are secure by default, private by design and that put you in control. As our advancements in knowledge and computing grow to deliver more help across contexts, locations and languages, our unwavering commitment to protecting your information remains.
That’s why Pixel phones are designed from the ground up to help protect you and your sensitive data while keeping you in control. We’re taking our industry-leading approach to security and privacy to the next level with Google Pixel 7 and Pixel 7 Pro, our most secure and private phones yet, which were recently recognized as the highest rated for security when tested among other smartphones by a third-party global research firm.1
Pixel phones also get better every few months with Feature Drops that provide the latest product updates, tips and tricks from Google. And Pixel 7 and Pixel 7 Pro users will receive at least five years of security updates2, so your Pixel gets even more secure over time.
Your protection, built into Pixel
Your digital life and most sensitive information lives on your phone: financial information, passwords, personal data, photos – you name it. With Google Tensor G2 and our custom Titan M2 security chip, Pixel 7 and Pixel 7 Pro have multiple layers of hardware security to help keep you and your personal information safe. We take a comprehensive, end-to-end approach to security with verifiable protections at each layer - the network, application, operating system and multiple layers on the silicon itself. If you use Pixel for your business, this approach helps protect your company data, too.
Google Tensor G2 is Pixel’s newest powerful processor custom built with Google AI, and makes Pixel 7 faster, more efficient and secure3. Every aspect of Tensor G2 was designed to improve Pixel's performance and efficiency for great battery life, amazing photos and videos.
Tensor’s built-in security core works with our Titan M2 security chip to keep your personal information, PINs and passwords safe. Titan family chips are also used to protect Google Cloud data centers and Chromebooks, so the same hardware that protects Google servers also secures your sensitive information stored on Pixel.
And, in a first for Google, Titan M2 hardware has now been certified under Common Criteria PP0084: the international gold standard for hardware security components also used for identity, SIM cards, and bankcard security chips.4 This means that the Titan M2 hardware meets the same rigorous protection guidelines trusted by banks, carriers, and governments.
To achieve the certification we went through rigorous third party lab testing by SGS Brightsight, a leading international security lab, and received certification against CC PP0084 with AVA_VAN.5 for the Titan M2 hardware and cryptography library from the Netherlands scheme for Certification in the Area of IT Security (NSCIB). Of all those numbers and acronyms the part we’re most proud of is that Titan hardware passed the highest level of vulnerability assessment (AVA_VAN.5) - the truest measure of resilience to advanced, methodical attacks.
This process took us more than three years to complete. The certification not only requires chip hardware to resist invasive penetration testing, but also mandates audits of the chip design and manufacturing process itself. The benefit for consumers? The now certified Titan M2 chip makes your phone even more resilient to sophisticated attacks.5
Private by design
Evolving our security and privacy standards to our fast-paced world requires new approaches as well. Earlier this year at I/O, we introduced Protected Computing, a toolkit of technologies that transforms how, when, and where personal data is processed to protect your privacy and security. Our approach focuses on:
Many elements of Protected Computing can be found on the new Pixel 7:
On Android, Private Compute Core keeps your information and AI-driven personalizations private with on-device processing. Data from features like Now Playing, Live Caption and Smart Reply in Messages are all processed on device and are never sent to Google to maintain your privacy. And even your device backups to the cloud are end-to-end encrypted using Titan in the cloud.6
With Google Tensor G2, Pixel’s advanced privacy protection also now covers audio data from events like cough and snore detection on Pixel 7.7 Audio data from cough and snore detection is never stored by or sent to Google to maintain your privacy.
On Pixel 7, Tensor G2 helps safeguard your system with the Android Virtualization Framework, unlocking improved security protections like enabling system update integrity checking to occur on-the-fly, reducing boot time after an update.
Extra protection when you’re online
Helping to keep you safe when you use your phone to browse the web and use apps is also critical. This is where a Virtual Private Network (VPN) comes in. A VPN helps protect your online activity from anyone who might try to access it by encrypting your network traffic to turn it into an unreadable format, and masking your original IP address. Typically, if you want a VPN on your phone, you need to get one from a third party.
To ensure more people have access to enhanced security, later this year, Pixel 7 and Pixel 7 Pro owners will be able to use VPN by Google One, at no extra cost.8 VPN by Google One is verifiably private, and will allow you to tap into Google’s world-class security for peace of mind when you connect online. With VPN by Google One, Pixel helps protect your online activity at a network level. Think of it like an extra layer of protection for your online security.
VPN by Google One creates a high-performance secure connection to the web so your browsing and app data is sent and received via an encrypted pathway. A few simple taps will activate the VPN to help keep your network traffic private from internet providers and hackers, giving you peace of mind when using cellular data, home Wi-Fi, and especially when connected to public networks, like a café or airport Wi-Fi. No need to worry about online intruders, hackers, or unsecure networks.
Unlike traditional VPN services, VPN by Google One uses Protected Computing to technically make it impossible for anyone at a network level, even VPN by Google One, to link your online traffic with your account or identity. VPN by Google One will be available at no extra cost as long as your phone continues to receive security updates. See here to learn more about VPN by Google One.
More protection and privacy with Android 13
Pixel 7 and Pixel 7 Pro have built-in anti-phishing protections from Android that scan for potential threats from phone calls, text messages and emails, and more anti-phishing protections enabled out-of-the-box than smartphones from leading competitors.9 In fact, Messages alone protects consumers against 1.5 billion spam messages per month.
Android also resets permissions for apps you haven’t used for an extended time. In a typical month, Android automatically resets more than 3 billion permissions affecting more than 1 billion installed apps. Similarly, if you use clipboard on Android 13, your history is automatically deleted after a period of time. This blocks apps running in the foreground from seeing old information that you previously copied.
You’re in control
Core to your safety is knowing that you’re in control. You always have control over your settings and devices across all of our products. With Android 13, coming soon through a Feature Drop, Pixel 7 and Pixel 7 Pro will give you additional ways to stay in control of your privacy and what you share with first and third-party apps. With Quick Settings, you can act on security issues as they arise, or review which apps are running in the background and easily stop them. You’ll have a single destination for reviewing your security and privacy settings, risk levels and information, making it easier to manage your safety status.
With this new experience, you can review actionable steps to improve your safety status, like revoking a permission or app. This page will also have new action cards to notify you of any safety risks and provide timely recommendations on how to enhance your privacy. And with a single tap, you can grant or remove permissions to data that you don’t want to share with compatible apps. This will be coming soon first to Pixel devices later this year, and other Android phones soon after.
Verifiably secure
As computing extends to more devices and use cases, Google is committed to innovating in security and being transparent about the processes that we take to get there. We are leading the industry in verifiable security by not only having products that are tested against real-world threats (like advanced spam, phishing and malware attacks), but also in publishing the results of penetration tests, security audits, and industry certifications across our Pixel and Nest products.
Another way to verify our security is through our Android and Google Devices Security Reward Program where we reward security researchers who find vulnerabilities across products, including Pixel, Nest and Fitbit. Last year on Android, we awarded nearly $3 million dollars, creating a valuable feedback loop between us and the security research community and, most importantly, helping us keep our users safe.
To learn more about Pixel 7 and Pixel 7 Pro, check out the Google Store.
Based on third-party global research firm. Evaluation considered features that may not be available in all countries. See here for more information. ↩
Android version updates and feature drops for at least 3 years from when the device first became available on the Google Store in the US. Android security updates for at least 5 years from when the device first became available on the Google Store in the US. See g.co/pixel/updates for details. ↩
Compared to Pixel 6. Speed and efficiency claims based on internal testing on pre-production devices. ↩
Common Criteria certification for hardware and cryptographic library (CC PP0084 EAL4+, AVA_VAN.5 and ALC_DVS.2). See g.co/pixel/certifications for details. ↩
Compared to Pixel 5a and earlier Pixel phones. ↩
Excludes MMS attachments and Google Photos. ↩
Not intended to diagnose, cure, mitigate, prevent or treat any disease or condition. Consult your healthcare professional if you have questions about your health. See g.co/pixel/digitalwellbeing for more information. ↩
Coming soon. Restrictions apply. Some data is not transmitted through VPN. Not available in all countries. All other Google One membership benefits sold separately. This VPN offer does not impact price or benefits of Google One Premium plan. Use of VPN may increase data costs depending on your plan. See g.co/pixel/vpn for details. ↩
Based on third-party research funded by Google LLC in June 2022. Evaluation based on no-cost smartphone features enabled by default. Some features may not be available in all countries. See here for more information. ↩
Memory safety bugs are the most numerous category of Chrome security issues and we’re continuing to investigate many solutions – both in C++ and in new programming languages. The most common type of memory safety bug is the “use-after-free”. We recently posted about an exciting series of technologies designed to prevent these. Those technologies (collectively, *Scan, pronounced “star scan”) are very powerful but likely require hardware support for sufficient performance.
Today we’re going to talk about a different approach to solving the same type of bugs.
It’s hard, if not impossible, to avoid use-after-frees in a non-trivial codebase. It’s rarely a mistake by a single programmer. Instead, one programmer makes reasonable assumptions about how a bit of code will work, then a later change invalidates those assumptions. Suddenly, the data isn’t valid as long as the original programmer expected, and an exploitable bug results.
These bugs have real consequences. For example, according to Google Threat Analysis Group, a use-after-free in the ChromeHTML engine was exploited this year by North Korea.
Half of the known exploitable bugs in Chrome are use-after-frees:
Diving Deeper: Not All Use-After-Free Bugs Are Equal
Chrome has a multi-process architecture, partly to ensure that web content is isolated into a sandboxed “renderer” process where little harm can occur. An attacker therefore usually needs to find and exploit two vulnerabilities - one to achieve code execution in the renderer process, and another bug to break out of the sandbox.
The first stage is often the easier one. The attacker has lots of influence in the renderer process. It’s easy to arrange memory in a specific way, and the renderer process acts upon many different kinds of web content, giving a large “attack surface” that could potentially be exploited.
The second stage, escaping the renderer sandbox, is trickier. Attackers have two options how to do this:
We imagine the attackers squeezing through the narrow part of a funnel:
Here’s a sample of 100 recent high severity Chrome security bugs that made it to the stable channel, divided by root cause and by the process they affect.
You might notice:
As you can see, the biggest category of bugs in each process is: V8 in the renderer process (JavaScript engine logic bugs - work in progress) and use-after-free bugs in the browser process. If we can make that “thin” bit thinner still by removing some of those use-after-free bugs, we make the whole job of Chrome exploitation markedly harder.
MiraclePtr: Preventing Exploitation of Use-After-Free Bugs
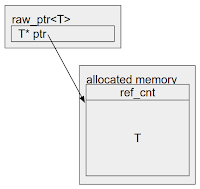
This is where MiraclePtr comes in. It is a technology to prevent exploitation of use-after-free bugs. Unlike aforementioned *Scan technologies that offer a non-invasive approach to this problem, MiraclePtr relies on rewriting the codebase to use a new smart pointer type, raw_ptr<T>. There are multiple ways to implement MiraclePtr. We came up with ~10 algorithms and compared the pros and cons. After analyzing their performance overhead, memory overhead, security protection guarantees, developer ergonomics, etc., we concluded that BackupRefPtr was the most promising solution.
class A { ... }; class B { B(A* a) : a_(a) {} void doSomething() { a_->doSomething(); } raw_ptr<A> a_; // MiraclePtr }; std::unique_ptr<A> a = std::make_unique<A>(); std::unique_ptr<B> b = std::make_unique<B>(a.get()); […] a = nullptr; // The free is delayed because the MiraclePtr is still pointing to the object. b->doSomething(); // Use-after-free is neutralized.
We successfully rewrote more than 15,000 raw pointers in the Chrome codebase into raw_ptr<T>, then enabled BackupRefPtr for the browser process on Windows and Android (both 64 bit and 32 bit) in Chrome 102 Stable. We anticipate that MiraclePtr meaningfully reduces the browser process attack surface of Chrome by protecting ~50% of use-after-free issues against exploitation. We are now working on enabling BackupRefPtr in the network, utility and GPU processes, and for other platforms. In the end state, our goal is to enable BackupRefPtr on all platforms because that ensures that a given pointer is protected for all users of Chrome.
Balancing Security and Performance
There is no free lunch, however. This security protection comes at a cost, which we have carefully weighed in our decision making.
Unsurprisingly, the main cost is memory. Luckily, related investments into PartitionAlloc over the past year led to 10-25% total memory savings, depending on usage patterns and platforms. So we were able to spend some of those savings on security: MiraclePtr increased the memory usage of the browser process 4.5-6.5% on Windows and 3.5-5% on Android1, still well below their previous levels. While we were worried about quarantined memory, in practice this is a tiny fraction (0.01%) of the browser process usage. By far the bigger culprit is the additional memory needed to store the reference count. One might think that adding 4 bytes to each allocation wouldn’t be a big deal. However, there are many small allocations in Chrome, so even the 4B overhead is not negligible. PartitionAlloc also uses pre-defined bucket sizes, so this extra 4B pushes certain allocations (particularly power-of-2 sized) into a larger bucket, e.g. 4096B->5120B.
We also considered the performance cost. Adding an atomic increment/decrement on common operations such as pointer assignment has unavoidable overhead. Having excluded a number of performance-critical pointers, we drove this overhead down until we could gain back the same margin through other performance optimizations. On Windows, no statistically significant performance regressions were observed on most of our top-level performance metrics like Largest Contentful Paint, First Input Delay, etc. The only adverse change there1 is an increase of the main thread contention (~7%). On Android1, in addition to a similar increase in the main thread contention (~6%), there were small regressions in First Input Delay (~1%), Input Delay (~3%) and First Contentful Paint (~0.5%). We don't anticipate these regressions to have a noticeable impact on user experience, and are confident that they are strongly outweighed by the additional safety for our users.
We should emphasize that MiraclePtr currently protects only class/struct pointer fields, to minimize the overhead. As future work, we are exploring options to expand the pointer coverage to on-stack pointers so that we can protect against more use-after-free bugs.
Note that the primary goal of MiraclePtr is to prevent exploitation of use-after-free bugs. Although it wasn’t designed for diagnosability, it already helped us find and fix a number of bugs that were previously undetected. We have ongoing efforts to make MiraclePtr crash reports even more informative and actionable.
Continue to Provide Us Feedback
Last but not least, we’d like to encourage security researchers to continue to report issues through the Chrome Vulnerability Reward Program, even if those issues are mitigated by MiraclePtr. We still need to make MiraclePtr available to all users, collect more data on its impact through reported issues, and further refine our processes and tooling. Until that is done, we will not consider MiraclePtr when determining the severity of a bug or the reward amount.
1 Measured in Chrome 99.
Recently, OSS-Fuzz—our community fuzzing service that regularly checks 700 critical open source projects for bugs—detected a serious vulnerability (CVE-2022-3008): a bug in the TinyGLTF project that could have allowed attackers to execute malicious code in projects using TinyGLTF as a dependency.
TinyGLTF
The bug was soon patched, but the wider significance remains: OSS-Fuzz caught a trivially exploitable command injection vulnerability. This discovery shows that fuzzing, a type of testing once primarily known for detecting memory corruption vulnerabilities in C/C++ code, has considerable untapped potential to find broader classes of vulnerabilities. Though the TinyGLTF library is written in C++, this vulnerability is easily applicable to all programming languages and confirms that fuzzing is a beneficial and necessary testing method for all software projects.
OSS-Fuzz was launched in 2016 in response to the Heartbleed vulnerability, discovered in one of the most popular open source projects for encrypting web traffic. The vulnerability had the potential to affect almost every internet user, yet was caused by a relatively simple memory buffer overflow bug that could have been detected by fuzzing—that is, by running the code on randomized inputs to intentionally cause unexpected behaviors or crashes that signal bugs. At the time, though, fuzzing was not widely used and was cumbersome for developers, requiring extensive manual effort.
Google created OSS-Fuzz to fill this gap: it's a free service that runs fuzzers for open source projects and privately alerts developers to the bugs detected. Since its launch, OSS-Fuzz has become a critical service for the open source community, helping get more than 8,000 security vulnerabilities and more than 26,000 other bugs in open source projects fixed. With time, OSS-Fuzz has grown beyond C/C++ to detect problems in memory-safe languages such as Go, Rust, and Python.
Google Cloud’s Assured Open Source Software Service, which provides organizations a secure and curated set of open source dependencies, relies on OSS-Fuzz as a foundational layer of security scanning. OSS-Fuzz is also the basis for free fuzzing tools for the community, such as ClusterFuzzLite, which gives developers a streamlined way to fuzz both open source and proprietary code before committing changes to their projects. All of these efforts are part of Google’s $10B commitment to improving cybersecurity and continued work to make open source software more secure for everyone.
Last December, OSS-Fuzz announced an effort to improve our bug detectors (known as sanitizers) to find more classes of vulnerabilities, by first showing that fuzzing can find Log4Shell. The TinyGLTF bug was found using one of those new sanitizers, SystemSan, which was developed specifically to find bugs that can be exploited to execute arbitrary commands in any programming language. This vulnerability shows that it was possible to inject backticks into the input glTF file format and allow commands to be executed during parsing.
SystemSan
# Craft an input that exploits the vulnerability to insert a string to poc $ echo '{"images":[{"uri":"a`echo iamhere > poc`"}], "asset":{"version":""}}' > payload.gltf # Execute the vulnerable program with the input $ ./loader_exampler payload.gltf # The string was inserted to poc, proving the vulnerability was successfully exploited $ cat poc iamhere
A proof of exploit in TinyGLTF, extended from the input found by OSS-Fuzz with SystemSan. The culprit was the use of the “wordexp” function to expand file paths.
SystemSan uses ptrace, and is built in a language-independent and highly extensible way to allow new bug detectors to be added easily. For example, we’ve built proofs of concept to detect issues in JavaScript and Python libraries, and an external contributor recently added support for detecting arbitrary file access (e.g. through path traversal).
ptrace
OSS-Fuzz has also continued to work with Code Intelligence to improve Java fuzzing by integrating over 50 additional Java projects into OSS-Fuzz and developing sanitizers for detecting Java-specific issues such as deserialization and LDAP injection vulnerabilities. A number of these types of vulnerabilities have been found already and are pending disclosure.
Want to get involved with making fuzzing more widely used and get rewarded? There are two ways:
To apply for these rewards, see the OSS-Fuzz integration reward program.
Fuzzing still has a lot of unexplored potential in discovering more classes of vulnerabilities. Through our combined efforts we hope to take this effective testing method to the next level and enable more of the open source community to enjoy the benefits of fuzzing.