



Abstract
We explore the potential of enhancing LLM performance in astronomy-focused question-answering through targeted, continual pre-training. By employing a compact 7B-parameter LLaMA-2 model and focusing exclusively on a curated set of astronomy corpora—comprising abstracts, introductions, and conclusions—we achieve notable improvements in specialized topic comprehension. While general LLMs like GPT-4 excel in broader question-answering scenarios due to superior reasoning capabilities, our findings suggest that continual pre-training with limited resources can still enhance model performance on specialized topics. Additionally, we present an extension of AstroLLaMA: the fine-tuning of the 7B LLaMA model on a domain-specific conversational data set, culminating in the release of the chat-enabled AstroLLaMA for community use. Comprehensive quantitative benchmarking is currently in progress and will be detailed in an upcoming full paper. The model, AstroLLaMA-Chat, is now available at https://huggingface.co/universeTBD, providing the first open-source conversational AI tool tailored for the astronomy community.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Motivation
Large Language Models (LLMs) have demonstrated exceptional capabilities across a wide range of tasks, covering both general and specialized domains, as evidenced by models like GPT and LLaMA (Radford et al. 2019; Brown et al. 2020; Touvron et al. 2023a, 2023b). Despite their impressive achievements, these models face notable challenges in highly specialized fields such as astronomy, particularly in keeping abreast of the latest field developments. This limitation arises from two primary factors: first, LLMs' propensity to align with general concepts restricts their capacity for providing detailed, nuanced responses in question-answering scenarios; second, infrequent updates to their training data sets result in a delay in assimilating recent astronomical advancements.
2. AstroLLaMA-Chat
Building upon our earlier initiative, AstroLLaMA (Nguyen et al. 2023), a pioneering LLM tailored for astronomy, we identified that while AstroLLaMA excelled in abstract completion, its ability in question-answering is still wanting. To enhance this, we introduce AstroLLaMA-Chat, an advanced version of AstroLLaMA. This new iteration broadens the training scope to include introductions and conclusions of papers up to 2023 July, along with their abstracts. After training on the enriched data set, we further fine-tuned AstroLLaMA-Chat on domain-specific question-answer pairs generated from GPT-4 (OpenAI 2023) based on abstracts of 300,000 arXiv papers, where GPT-4 first formulates pertinent questions from those abstracts and then answers these questions by retrieving context-relevant information from the same paragraph. A typical QA sample is as follows: Q: What is the refined planet-to-star radius ratio for HD 149026? A: The refined planet-to-star radius ratio for HD 149026 is R_p/R_star=0.0491{o+0.0018}. We created 10,356 samples in this fashion and integrated additional open-source data sets, including the LIMA data set (Zhou et al. 2023), 10,000 samples from Open Orca (Lian et al. 2023; Longpre et al. 2023; Mukherjee et al. 2023), and 10,000 samples from UltraChat (Ding et al. 2023).
3. Training
We executed fine-tuning on the LLaMA-2 models using the LMFlow LLM-training framework (Diao et al. 2023), incorporating advanced techniques like Flash Attention (Dao et al. 2022; Dao 2023) and ZeRO Optimization (Rajbhandari et al. 2020). This approach led to a significant efficiency gain: LMFlow reduced the time cost for training AstroLLaMA (Nguyen et al. 2023) by approximately fivefold. When training AstroLLaMA-Chat, despite the expanded data set, LMFlow required only about twelve A100 GPU days. Our hyperparameters for domain-specific training included a peak learning rate of η = 10−5, a batch size of 32, a maximum token length of 2048, a warmup ratio of 0.03, two gradient accumulation steps, and the use of the fp16 format, while the downstream chat training shares a similar set of hyperparameters except for learning rate η = 2 × 10−5 and batch size 64. We opted for a cosine learning rate (Loshchilov & Hutter 2016), as empirical evidence suggested it enhanced model performance for our specific tasks. While we are releasing the 7b conversational model, our team has also trained a more substantial 70b version, which is plan to be released in an upcoming full paper.
4. Discussion
A question naturally arises in the era of versatile and powerful large language models: Is there merit to developing specialized chatbots? Our findings indicate that general-purpose models such as GPT-4 and, to some extent, LLaMA-2, demonstrate robust reasoning and a good general understanding of astronomy. This suggests that with strategic prompting and engineering, existing large language models can serve as effective tools in this domain.
However, the primary objective of our research is to demonstrate that continual pre-training, even with a relatively modest model such as the 7b AstroLLaMA, can yield competitive and, in certain specific cases, superior performance. Our experiments reveal that while AstroLLaMA-Chat may not consistently outperform GPT-4 and LLaMA-2 in general astronomy-related Q&A, it performs better in highly specialized topics (Figure 1). These include intricate areas like the dimensionality of elemental abundance space, differential line-by-line spectroscopic analysis, and recent studies in astronomy, such as the Large Magellanic Cloud (LMC) wake in the Milky Way's stellar halo or the cosmological parity violation. In these niche areas, AstroLLaMA tends to provide more accurate answers than GPT-4 and LLaMA-2, albeit still with limitations in alignment and a propensity for more hallucination. We aim to address the limitation of multi-turn conversations by enhancing our model in the future. This involves incorporating additional training data and implementing alignment techniques.

Figure 1. Demonstration of AstroLLaMA-Chat's Capabilities. While general large language models like GPT-4 continue to exhibit robust reasoning and Q&A abilities, even in specialized domains such as astronomy, our study highlights the benefits of continual pre-training on a dedicated astronomy corpus from arXiv, enriched with the latest data. This approach gives AstroLLaMA-Chat an edge in two specific areas. The top example illustrates its performance in a highly specialized topic within astronomy. AstroLLaMA-Chat demonstrates a better understanding of the complexities involved in studying the dimensionality of elemental abundance in stars, reflecting the true chemical yield channels. It also outlines prevalent methods in this specialized area. In contrast, GPT-4 and the LLaMA-2-7b model, from which AstroLLaMA is derived, often provide responses that lack depth in understanding this field. The bottom panel illustrates AstroLLaMA-Chat's adeptness in addressing contemporary and dynamic research areas, notably the burgeoning field of parity violation studies in cosmology. While it captures some of the latest directions in the field (though with occasional detail inaccuracies), both GPT-4 and LLaMA-2 tend to diverge into broader implications and detection methods, failing to encapsulate the current focus of the field.
Download figure:
Standard image High-resolution image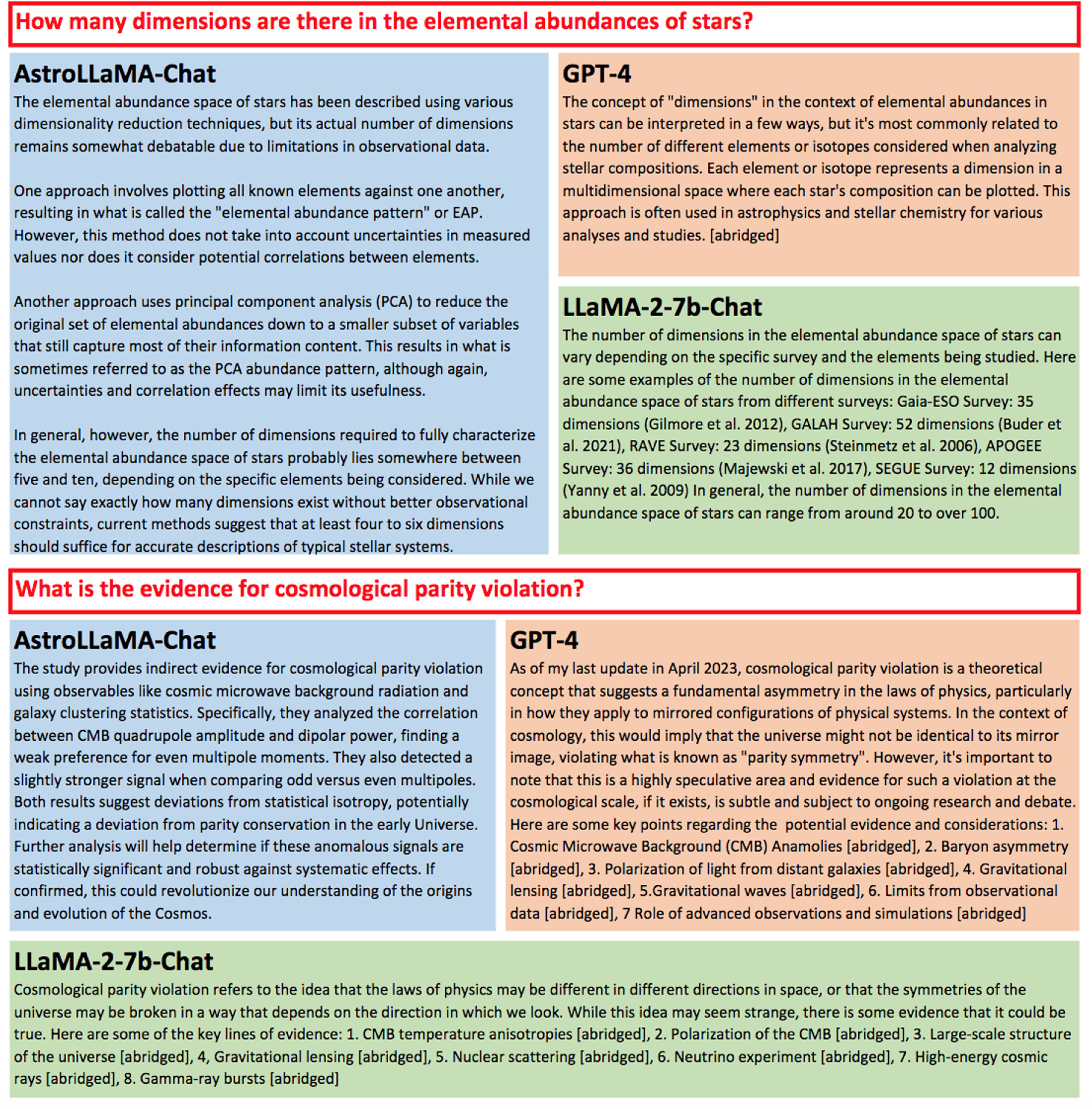{kind=link}
Acknowledgments
The authors thank Microsoft Research for their support through the Microsoft Accelerating Foundation Models Academic Research Program. We are also thankful for the support from OpenAI through the OpenAI Researcher Access Program.