
Nesta página, apresentamos uma visão geral do serviço de avaliação de IA generativa, que permite avaliar o desempenho do modelo em casos de uso específicos. A avaliação também pode ser chamada de observabilidade do desempenho de um modelo. O serviço de avaliação de IA generativa permite monitorar o desempenho do modelo em diferentes condições, fornecendo insights que ajudam a otimizar o modelo com base no caso de uso específico.
Os rankings podem fornecer métricas sobre o desempenho geral do modelo, mas não sobre o desempenho dele em casos de uso específicos. Ao desenvolver modelos de linguagem grandes (LLMs), é importante avaliar seu modelo usando critérios específicos para seu caso de uso.
As avaliações ajudam a garantir que os modelos possam se adaptar aos requisitos específicos do domínio de diferentes usuários. Ao avaliar modelos em relação a comparativos de mercado e objetivos definidos pelo usuário, é possível aplicar a engenharia de comando e o ajuste de modelos para melhor alinhar com o as empresas que você atende. Essas avaliações são usadas para orientar o desenvolvimento e a melhoria dos modelos, além de ajudar a garantir que eles sejam úteis, seguros e eficazes para os usuários.
Exemplos de casos de uso
Você avaliará modelos de IA generativa para fornecer um comparativo de mercado para o desempenho do modelo e para orientar o desenvolvimento e o refinamento estratégico de seus modelos e aplicativos. Esse processo ajuda a garantir que os modelos de IA generativa estejam alinhados às suas necessidades de negócios. A avaliação do modelo oferece benefícios diferentes para diferentes fases de desenvolvimento. Na pré-produção, use a avaliação de modelo para selecionar e personalizar um modelo. Durante a produção, é possível monitorar o desempenho do modelo para garantir que ele seja eficaz.
A avaliação da IA generativa pode ser aplicada a uma variedade de cenários de casos de uso, como:
- Selecionar modelos pré-treinados: escolha um modelo pré-treinado para uma tarefa ou aplicativo específico avaliando o desempenho do modelo nas tarefas de comparativo de mercado associadas.
- Definir configurações de geração de modelos: otimize as configurações
dos parâmetros de geração de modelos, como
temperature, o que pode melhorar o desempenho das tarefas. - Engenharia de prompts usando um modelo: crie comandos mais eficazes que geram resultados de maior qualidade, melhorando a interação com o modelo.
- Melhorar e proteger o ajuste detalhado: ajuste os processos para melhorar o desempenho do modelo, evitando vieses ou comportamentos indesejáveis.
Para mais informações sobre modelos de linguagem generativa, consulte Notebooks de avaliação.
Serviços de avaliação
A Vertex AI oferece duas opções de serviço para realizar avaliações de modelos de IA generativa. Escolha o serviço que melhor se adapta ao seu caso de uso:
| Serviço | Caso de uso |
|---|---|
| Avaliação on-line (avaliação rápida) | Algumas instâncias para avaliação. Fluxos de trabalho que exigem iterações rápidas. |
| Avaliação de pipeline (AutoSxS e baseada em computação) | Muitas instâncias para avaliar. Fluxos de trabalho assíncronos e MLOps. Modelos de avaliação criados no Vertex AI Pipelines. |
Avaliação rápida
O serviço de avaliação rápida produz avaliações síncronas e de baixa latência em pequenos lotes de dados. É possível realizar avaliações sob demanda e integrar o serviço on-line a outros serviços da Vertex AI usando o SDK da Vertex AI para Python. O uso do SDK torna o serviço on-line adaptável a uma variedade de casos de uso.
O serviço on-line é mais adequado para casos de uso que envolvem pequenos lotes de dados ou quando você precisa iterar e testar rapidamente.
Avaliação de pipeline: AutoSxS e baseado em computação
Os serviços de pipeline de avaliação oferecem opções completas para avaliar modelos de IA generativa. Essas opções usam o Vertex AI Pipelines para orquestrar uma série de etapas relacionadas à avaliação, como gerar respostas de modelo, chamar o serviço de avaliação on-line e calcular métricas. Essas etapas também podem ser chamadas individualmente em pipelines personalizados.
Como o Vertex AI Pipelines não tem servidor, há uma latência de inicialização mais alta associada ao uso de pipelines para avaliação. Portanto, esse serviço é mais adequado para jobs de avaliação maiores, fluxos de trabalho em que as avaliações não são necessárias imediatamente e integração com pipelines de MLOps.
Oferecemos dois pipelines de avaliação separados, como:
- AutoSxS: avaliação baseada em modelo e pareada.
- Baseado em computação: com base em computação, avaliação pontual.
Paradigmas de avaliação
As avaliações de IA generativa funcionam devido a dois paradigmas de avaliação de modelos, que incluem:
- Por pontos: é possível avaliar um modelo.
- Em pares: é possível comparar dois modelos.
Por pontos
A avaliação por pontos avalia o desempenho de um único modelo. Isso ajuda você
a entender o desempenho do modelo em uma tarefa específica, como
summarization ou uma dimensão, como instruction following. O processo
de avaliação inclui as seguintes etapas:
- Os resultados previstos são produzidos a partir do modelo com base no comando de entrada.
- A avaliação é realizada com base nos resultados gerados.
Dependendo do método de avaliação, pares de entrada e saída e informações empíricas
podem ser necessários. Quando informações empíricas estão disponíveis, as saídas do modelo são
avaliadas com base no alinhamento delas com os resultados esperados. Para mais informações,
consulte Executar avaliação baseada em computação. Quando usada sem informações empíricas, a avaliação depende da resposta do modelo
para os comandos de entrada. Um modelo de autoavaliação separado também é usado. Para mais informações, consulte
Executar avaliação do AutoSxS (avaliação baseada em modelo de paridade) para produzir métricas personalizadas de acordo com a natureza da tarefa. Por exemplo, é
possível usar coherence e relevance em text generation ou accuracy em
summarization.
Esse paradigma permite a compreensão dos recursos de um modelo na geração de conteúdo, fornecendo insights sobre os pontos fortes e as áreas de melhoria do modelo em um contexto autônomo, sem exigir uma comparação direta com outro modelo.
Em pares
A avaliação em pares é realizada comparando as previsões dos dois modelos. Existe um modelo A para ser avaliado
em relação a um modelo B, o modelo de referência de referência. É necessário fornecer prompts de entrada que representem o domínio de entrada usado para a comparação dos modelos.
Considerando o mesmo comando de entrada, a comparação lado a lado especifica qual previsão de modelo é a preferida com base nos critérios de comparação. Os resultados finais da avaliação
são capturados peo win rate. Esse paradigma também pode funcionar sem
a necessidade de uma referência a dados de informações empíricas.
Métodos de avaliação
Há duas categorias de métricas com base no método de avaliação, que incluem:
Métricas baseadas em computação
As métricas baseadas em computação comparam se os resultados gerados pelo LLM são consistentes com um conjunto de dados de informações empíricas de pares de entrada e saída. As métricas mais usadas são categorizadas nos seguintes grupos:
- Métricas baseadas no léxico: use cálculos para calcular as semelhanças
de strings entre os resultados gerados pelo LLM e as informações
empíricas, como
Exact MatcheROUGE. - Métricas baseadas em contagem: agregue o número de linhas que alcançam ou não determinados
rótulos de informações empíricas, como
F1-score,AccuracyeTool Name Match. - Métricas baseadas em embedding: calcule a distância entre os resultados gerados pelo LLM e as informações empíricas no espaço de embedding, refletindo o nível de semelhança entre eles.
No serviço de avaliação de IA generativa, é possível usar métricas baseadas em computação por meio do SDK do Python de avaliação rápida e o pipeline. A avaliação baseada em computação só pode ser realizada em casos de uso por pontos No entanto, é possível comparar diretamente as pontuações de métricas de dois modelos para uma comparação entre os pares.
Métricas baseadas em modelos
Um modelo de autoavaliação é usado para gerar métricas de avaliação baseadas em modelos. Assim como avaliadores humanos, o avaliador automático realiza avaliações complexas e diferenciadas. Os avaliadores automáticos tentam aprimorar a avaliação humana. Nós calibramos a qualidade off-line com avaliadores humanos. Assim como os avaliadores humanos, o avaliador automático determina a qualidade das respostas por meio de uma saída de pontuação numérica e fornece o raciocínio por trás dos julgamentos com um nível de confiança. Para mais informações, consulte Ver os resultados da avaliação.
A avaliação baseada em modelo está disponível sob demanda e avalia modelos de linguagem com desempenho comparável ao de avaliadores humanos. Outros benefícios da avaliação baseada em modelos incluem:
- Avaliação de modelos de linguagem natural sem dados de preferência humana.
- Melhor escalabilidade, aumenta a disponibilidade e reduz os custos em comparação com a avaliação de modelos de linguagem com avaliadores humanos.
- Transparência das classificações capturando explicações de preferências e pontuações de confiança.
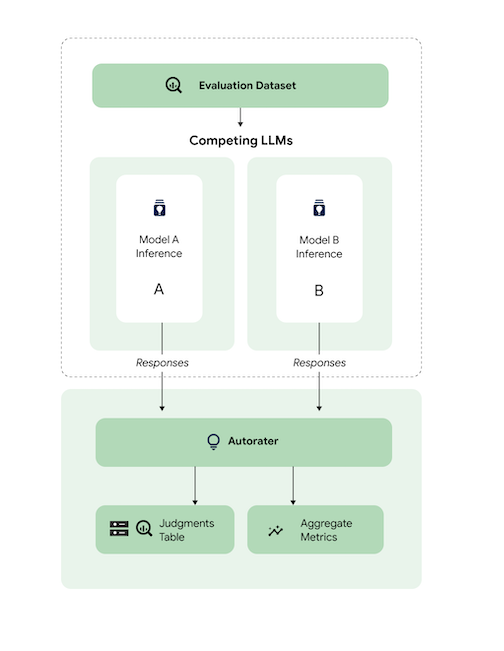
Este diagrama ilustra como funciona a avaliação baseada em modelo em pares, que pode ser realizada em casos de uso pontuais e em pares. É possível ver como o avaliador automático realiza a avaliação em pares no serviço de pipeline de avaliação, AutoSxS.
A seguir
- Teste um notebook de exemplo de avaliação.
- Saiba mais sobre a avaliação on-line com uma avaliação rápida.
- Saiba mais sobre a avaliação em pares baseada em modelo com o pipeline AutoSxS.
- Saiba mais sobre o pipeline de avaliação baseado em computação.
- Saiba como ajustar um modelo de fundação.