
생성형 AI 평가 서비스를 사용하면 특정 사용 사례에서 모델 성능을 평가할 수 있습니다.
리더보드는 모델의 일반적인 성능에 대한 유용한 개요를 제공할 수 있지만 특정 사용 사례에서의 모델 성능에 대한 정보를 제공할 수 없습니다.
AI 기반 솔루션을 개발할 때는 생성형 AI 모델이 비즈니스 요구사항에 따라 고정된 기준으로 사용자 데이터를 평가해야 합니다. 평가를 통해 여러 사용자의 분야별 요구사항에 맞게 모델을 조정할 수 있습니다. 사용자 정의 벤치마크와 목표에 따라 모델을 평가하면 프롬프트 엔지니어링 및 모델 미세 조정을 적용하여 서비스를 제공 중인 비즈니스의 운영 상황, 문화적 민감성, 전략적 목표에 더 잘 부합하도록 조정할 수 있습니다. 이러한 평가는 모델이 사용자에게 유용하고 안전하며 효과적인지 확인하면서 모델의 개발과 개선을 안내하는 데 사용됩니다.
이 섹션에서는 개발 수명 주기 전반에서 생성형 AI 평가의 사용 사례를 제공합니다. 또한 주요 패러다임, 온라인 평가 빠른 시작 사용해 보기를 통한 온라인 평가 환경, 평가 로직을 프로덕션에 이전할 수 있는 파이프라인 구성요소를 제공합니다. 대화형 평가 및 프로덕션에 즉시 사용 가능한 파이프라인 간에 전환할 수 있습니다. 평가 결과는 Vertex AI Experiments에 자동 로깅됩니다. summarization 또는 question answering과 같은 태스크를 평가하고 coherence 또는 summarization verbosity와 같은 개별 측정항목을 평가할 수 있도록 사전 빌드된 구성요소를 제공합니다. 측정항목을 정의하고 자동 평가 도구 기준을 제공할 수도 있습니다.
사용 사례 예시
생성형 AI 평가는 모델 성능을 벤치마크하고 생성형 AI 모델 및 애플리케이션의 전략적 개발과 상세검색을 안내하는 포괄적인 프로세스로, 생성형 AI 모델이 비즈니스 요구사항에 맞게 조정되었는지 확인합니다. 생성형 AI는 개발의 여러 단계에서 사용할 수 있습니다.
- 사전 프로덕션: 모델 선택 및 조정과 같은 맞춤설정 환경설정과 관련하여 더 나은 결정을 내릴 수 있습니다.
- 프로덕션 중: 모델의 성능을 모니터링하여 모델이 효과적인지 확인할 수 있습니다.
생성형 AI 평가는 다음과 같은 다양한 사용 사례 시나리오에 적용할 수 있습니다.
- 사전 학습된 모델 선택: 관련 벤치마크 태스크에 대한 모델 성능을 평가하여 특정 태스크 또는 애플리케이션에 대해 사전 학습된 모델을 선택할 수 있습니다.
- 모델 생성 설정 구성:
temperature와 같은 모델 생성 매개변수의 구성 설정을 최적화하여 태스크의 성능을 개선할 수 있습니다. - 템플릿을 사용한 프롬프트 엔지니어링: 고품질의 출력을 제공하는 보다 효과적인 프롬프트를 설계하여 모델과의 사용자 상호작용을 개선할 수 있습니다.
- 미세 조정 개선 및 보호: 미세 조정 프로세스는 편향이나 원치 않는 동작을 방지하면서 모델 성능을 향상시킵니다.
더 많은 예시는 평가 예시를 참조하세요.
평가 패러다임
생성형 AI 평가는 다음과 같은 모델 평가의 두 가지 패러다임으로 인해 작동합니다.
점별
점별 평가는 단일 모델의 성능을 평가합니다. 이렇게 하면 summarization과 같은 특정 태스크 또는 instruction following와 같은 측정기준에서 모델 성능을 이해하는 데 도움이 됩니다. 평가 프로세스에는 다음 단계가 포함됩니다.
- 입력 프롬프트를 기반으로 모델에서 예측 결과가 생성됩니다.
- 생성된 결과를 기반으로 평가가 수행됩니다.
평가 방법에 따라 입력 및 출력 쌍과 정답이 필요할 수 있습니다. 정답을 사용할 수 있으면 출력이 예상 결과와 얼마나 일치하는지를 기준으로 모델의 출력이 평가됩니다.
자세한 내용은 계산 기반 평가 수행을 참조하세요.
정답을 사용할 수 없으면 평가는 입력 프롬프트에 대한 모델의 응답을 사용합니다. 별도의 자동 평가 도구 모델도 사용됩니다. 자세한 내용은 태스크 특성에 맞춤설정된 측정항목을 생성하기 위한 쌍별 모델 기반 평가 수행을 참조하세요. 예를 들어 text generation에서 coherence 및 relevance를 사용하거나 summarization에서 accuracy를 사용할 수 있습니다.
이 패러다임을 사용하면 콘텐츠 생성 시 모델의 기능을 이해하고 다른 모델과 직접 비교할 필요 없이 모델의 강점과 독립형 컨텍스트에서 개선할 영역에 대한 유용한 정보를 얻을 수 있습니다.
쌍별
쌍별 평가는 두 모델의 예측을 비교하여 수행됩니다. 기준 참조 모델인 모델 B에 대해 평가할 모델 A가 있다고 가정하겠습니다. 모델 비교에 사용되는 입력 도메인을 나타내는 입력 프롬프트를 제공해야 합니다.
동일한 입력 프롬프트가 주어지면 병렬 비교는 비교 기준에 따라 선호되는 모델 예측을 지정합니다. 최종 평가 결과는 win rate로 캡처됩니다. 이 패러다임은 정답 데이터를 참조할 필요 없이 작동할 수도 있습니다.
평가 방법
평가 방법에 따라 다음과 같은 두 가지 측정항목 카테고리가 있습니다.
계산 기반 측정항목
계산 기반 측정항목은 LLM에서 생성된 결과가 입력 및 출력 쌍의 정답 데이터 세트와 일치하는지 여부를 비교합니다. 일반적으로 사용되는 측정항목은 다음 그룹으로 분류할 수 있습니다.
- Lexicon 기반 측정항목: 수학을 사용하여
Exact Match및ROUGE와 같은 LLM에서 생성된 결과와 정답 간의 문자열 유사성을 계산합니다. - 개수 기반 측정항목:
F1-score,Accuracy,Tool Name Match와 같은 특정 정답 라벨에 도달하거나 누락된 행 수를 집계합니다. - 임베딩 기반 측정항목: 임베딩 공간에서 LLM에서 생성된 결과와 정답 사이의 거리를 계산하여 유사성 수준을 반영합니다.
생성형 AI 평가 서비스에서 파이프라인 및 Rapid Eval Python SDK를 통해 계산 기반 측정항목을 사용할 수 있습니다. 계산 기반 평가는 쌍별 사용 사례에서만 수행될 수 있습니다. 그러나 쌍별 비교를 위해 두 모델의 측정항목 점수를 직접 비교할 수 있습니다.
모델 기반 측정항목
자동 평가 도구 모델은 모델 기반 평가 측정항목을 생성하는 데 사용됩니다. 자동 평가 도구는 기존에는 비용이 많이 드는 인간 평가자가 수행했던 복잡하고 세밀한 평가를 수행합니다. 자동 평가 도구는 인간의 평가를 보강하며 Google에서는 인간 평가자를 통해 자동 평가 도구의 품질을 오프라인으로 조정합니다. 인간 평가자와 마찬가지로 자동 평가 도구는 숫자 점수 출력을 통해 응답의 품질을 결정하고 신뢰도 수준과 함께 판단의 근거를 제공합니다. 자세한 내용은 평가 결과 보기를 참조하세요.
모델 기반 평가는 주문형으로 제공되며 인간 평가자와 성능이 비슷한 언어 모델을 평가합니다. 모델 기반 평가의 몇 가지 추가 이점은 다음과 같습니다.
- 인간 선호도 데이터 없이 자연어 모델을 평가합니다.
- 인간 평가자를 통해 언어 모델을 평가할 때보다 확장성이 뛰어나고 가용성이 높아지며 비용이 절감됩니다.
- 선호도 설명과 신뢰도 점수를 캡처하여 평가 투명성을 확보합니다.
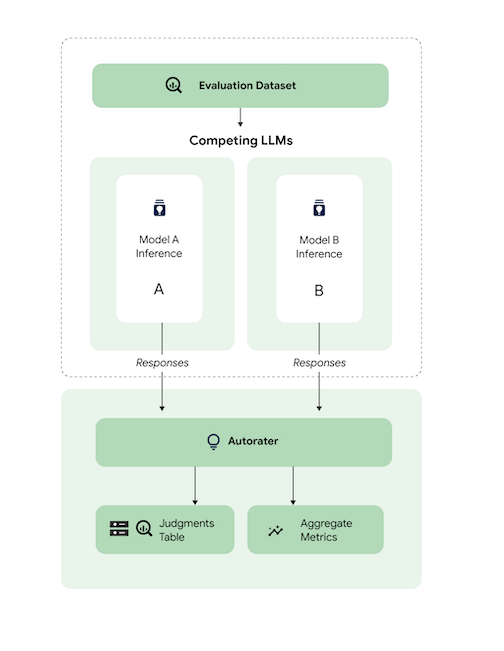
이 다이어그램은 점별 및 쌍별 사용 사례에서 수행될 수 있는 쌍별 모델 기반 평가의 작동 방식을 보여줍니다. 자동 평가 도구는 평가 파이프라인 서비스인 AutoSxS에서 쌍별 평가를 수행하는 방법을 확인할 수 있습니다.
다음 단계
- 온라인 평가 서비스를 빠르게 실행하는 방법 알아보기. 온라인 평가 빠른 시작 사용해 보기
- 온라인 및 파이프라인 평가 비교 자세히 알아보기
- 계산 기반 평가 알아보기
- 쌍별 모델 기반 평가 알아보기
- 기반 모델 조정 방법 알아보기