
AI에 최적화된 하드웨어, 소프트웨어, 소비를 결합하여 생산성과 효율성을 개선합니다.
개요
Google Cloud TPU, Google Cloud GPU, Google Cloud Storage, 기본 Jupiter 네트워크 등 성능에 최적화된 Google 인프라는 아키텍처의 강력한 확장 특성으로 인해 대규모 모델 서빙에 최고의 가격 대비 성능을 제공하므로 대규모 최신 모델에 가장 빠른 학습 시간을 제공합니다.
Google의 아키텍처는 Tensorflow, Pytorch, JAX와 같은 가장 일반적인 도구와 라이브러리를 지원하도록 최적화되어 있습니다. 또한 고객은 Cloud TPU 멀티슬라이스 및 멀티호스트 구성과 같은 기술과 Google Kubernetes Engine과 같은 관리형 서비스를 활용할 수 있습니다. 이를 통해 고객은 SLURM으로 조정된 NVIDIA NeMO 프레임워크와 같은 일반적인 워크로드에 대해 턴키 방식의 배포를 제공할 수 있습니다.
Google의 유연한 소비 모델을 통해 고객은 약정 사용 할인이 적용된 고정 비용 또는 동적 주문형 모델을 선택하여 비즈니스 니즈를 충족할 수 있습니다. 동적 워크로드 스케줄러는 고객이 과도한 할당 없이 필요한 용량을 확보하여 필요한 만큼만 지불할 수 있도록 도와줍니다. 또한 Google Cloud의 비용 최적화 도구는 리소스 사용을 자동화하여 엔지니어의 수동 작업을 줄여 줍니다.
작동 방식
Google은 TensorFlow와 같은 기술을 발명한 인공지능 분야의 리더입니다. Google의 기술을 프로젝트에 활용할 수 있다는 사실을 알고 계셨나요? Google이 AI 인프라 부문에서 혁신해 온 역사와 이를 워크로드에 활용할 수 있는 방법을 알아보세요.
일반적인 용도
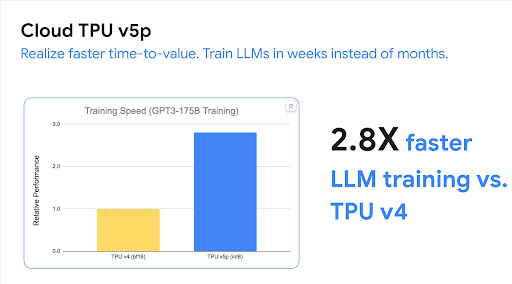
Cloud TPU 멀티슬라이스 학습은 수만 개의 TPU 칩에서 빠르고 쉬우며 안정적인 대규모 AI 모델 학습을 지원하는 풀 스택 기술입니다.
"사용자 메시지에 대한 응답을 생성하려면 GPU가 필요합니다. 더 많은 사용자가 플랫폼을 이용함에 따라 서비스를 제공하려면 더 많은 GPU가 필요합니다. Google Cloud에서는 특정 워크로드에 적합한 플랫폼을 찾기 위한 실험을 진행할 수 있습니다. 가장 가치 있는 솔루션을 유연하게 선택할 수 있다는 것은 큰 장점입니다." 마일 오트, Character.AI 창립 엔지니어
Cloud TPU 멀티슬라이스 학습은 수만 개의 TPU 칩에서 빠르고 쉬우며 안정적인 대규모 AI 모델 학습을 지원하는 풀 스택 기술입니다.
"사용자 메시지에 대한 응답을 생성하려면 GPU가 필요합니다. 더 많은 사용자가 플랫폼을 이용함에 따라 서비스를 제공하려면 더 많은 GPU가 필요합니다. Google Cloud에서는 특정 워크로드에 적합한 플랫폼을 찾기 위한 실험을 진행할 수 있습니다. 가장 가치 있는 솔루션을 유연하게 선택할 수 있다는 것은 큰 장점입니다." 마일 오트, Character.AI 창립 엔지니어
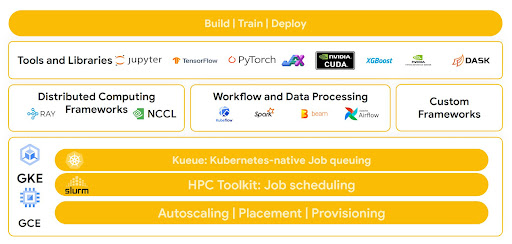
Google Cloud의 오픈 소프트웨어 생태계를 사용하면 가장 익숙한 도구와 프레임워크로 애플리케이션을 빌드하는 동시에 AI Hypercomputer 아키텍처의 가격 대비 성능 이점을 활용할 수 있습니다.
"Google Cloud와 협력하여 생성형 AI를 통합함으로써 챗봇 내에 맞춤형 여행 컨시어지를 만들 수 있게 되었습니다. 저희는 고객이 여행 계획을 세우는 것을 넘어서 취향을 반영한 특별한 여행을 경험할 수 있도록 돕고 싶습니다." 마틴 브로드벡, Priceline CTO

Google Cloud의 오픈 소프트웨어 생태계를 사용하면 가장 익숙한 도구와 프레임워크로 애플리케이션을 빌드하는 동시에 AI Hypercomputer 아키텍처의 가격 대비 성능 이점을 활용할 수 있습니다.
"Google Cloud와 협력하여 생성형 AI를 통합함으로써 챗봇 내에 맞춤형 여행 컨시어지를 만들 수 있게 되었습니다. 저희는 고객이 여행 계획을 세우는 것을 넘어서 취향을 반영한 특별한 여행을 경험할 수 있도록 돕고 싶습니다." 마틴 브로드벡, Priceline CTO
NVIDIA L4 GPU를 제공하는 Cloud TPU v5e 및 G2 VM 인스턴스는 최신 LLM 및 생성형 AI 모델을 비롯한 다양한 AI 워크로드에 비용 효율적인 고성능 추론을 지원합니다. 두 가지 모두 이전 모델에 비해 현저히 개선된 가격 대비 성능을 제공하며 Google Cloud의 AI Hypercomputer 아키텍처를 통해 고객은 배포를 업계 최고의 수준으로 확장할 수 있습니다.
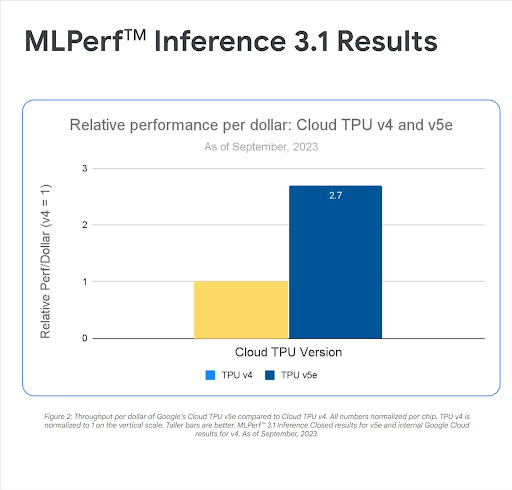
"실험 결과에 따르면 Cloud TPU v5e는 모델에 대규모 추론을 실행하기 위한 가장 비용 효율적인 가속기입니다. G2보다 달러당 성능이 2.7배, A2 인스턴스에 비해 달러당 성능이 4.2배 더 높습니다." 도메닉 도나토,
AssemblyAI 기술 부문 부사장

NVIDIA L4 GPU를 제공하는 Cloud TPU v5e 및 G2 VM 인스턴스는 최신 LLM 및 생성형 AI 모델을 비롯한 다양한 AI 워크로드에 비용 효율적인 고성능 추론을 지원합니다. 두 가지 모두 이전 모델에 비해 현저히 개선된 가격 대비 성능을 제공하며 Google Cloud의 AI Hypercomputer 아키텍처를 통해 고객은 배포를 업계 최고의 수준으로 확장할 수 있습니다.
"실험 결과에 따르면 Cloud TPU v5e는 모델에 대규모 추론을 실행하기 위한 가장 비용 효율적인 가속기입니다. G2보다 달러당 성능이 2.7배, A2 인스턴스에 비해 달러당 성능이 4.2배 더 높습니다." 도메닉 도나토,
AssemblyAI 기술 부문 부사장

































