
KI-optimierte Hardware, Software und Nutzung, für höhere Produktivität und Effizienz kombiniert.
Überblick
Unsere leistungsoptimierte Infrastruktur, die Google Cloud TPU, Google Cloud GPU, Google Cloud Storage und das zugrunde liegende Jupiter-Netzwerk umfasst, ermöglicht aufgrund der starken Skalierungsmerkmale der Architektur eine optimal kurze Zeit für das Training umfangreicher, hochmoderner Modelle, was zum besten Preis-Leistungs-Verhältnis für die Bereitstellung großer Modelle führt.
Unsere Architektur ist so optimiert, dass gängige Tools und Bibliotheken wie Tensorflow, Pytorch und JAX unterstützt werden. Außerdem können Kunden damit Technologien wie Cloud TPU-Multislice- und Multihost-Konfigurationen und verwaltete Dienste wie Google Kubernetes Engine nutzen. Kunden können so gängige Arbeitslasten wie das von SLURM orchestriert NVIDIA NeMO-Framework sofort bereitstellen.
Mit unseren flexiblen Nutzungsmodellen können Kunden feste Kosten mit Rabatten für zugesicherte Nutzung oder dynamischen On-Demand-Modellen auswählen, um ihre Geschäftsanforderungen zu erfüllen.Der dynamische Arbeitslastplaner hilft Kunden, die von ihnen benötigte Kapazität ohne Überhang zu erhalten. So zahlen sie nur für das, was sie tatsächlich benötigen.Außerdem helfen die Tools zur Kostenoptimierung von Google Cloud bei der Automatisierung der Ressourcennutzung, um manuelle Aufgaben zu reduzieren, die von Entwicklern ausgeführt werden müssten.
Funktionsweise
Google ist dank der Erfindung von Technologien wie TensorFlow im Bereich künstliche Intelligenz führend. Wussten Sie, dass Sie die Technologie von Google auch für Ihre eigenen Projekte nutzen können? Erfahren Sie mehr über die Innovationsgeschichte von Google im Bereich der KI-Infrastruktur und wie Sie diese für Ihre Arbeitslasten nutzen können.
Gängige Einsatzmöglichkeiten
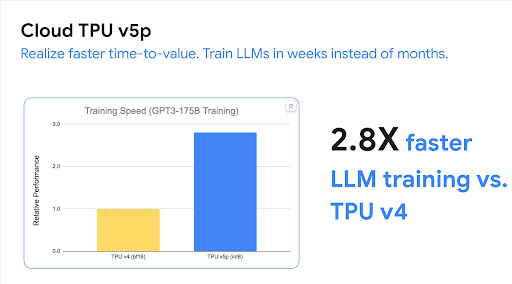
Das Cloud TPU-Multislice-Training ist eine Full-Stack-Technologie, die ein schnelles, einfaches und zuverlässiges Training großer KI-Modelle mit Zehntausenden TPU-Chips ermöglicht.
„Wir benötigen GPUs, um Antworten auf Nutzernachrichten zu generieren. Und je mehr Nutzer unsere Plattform hat, desto mehr GPUs benötigen wir, um unsere Dienste zu erbringen. In Google Cloud können wir experimentieren, um die richtige Plattform für eine bestimmte Arbeitslast zu finden. Es ist toll, die Flexibilität zu haben, die Lösungen auszuwählen, die am Besten sind.“ Myle Ott, Gründeringenieur, Character.AI
Das Cloud TPU-Multislice-Training ist eine Full-Stack-Technologie, die ein schnelles, einfaches und zuverlässiges Training großer KI-Modelle mit Zehntausenden TPU-Chips ermöglicht.
„Wir benötigen GPUs, um Antworten auf Nutzernachrichten zu generieren. Und je mehr Nutzer unsere Plattform hat, desto mehr GPUs benötigen wir, um unsere Dienste zu erbringen. In Google Cloud können wir experimentieren, um die richtige Plattform für eine bestimmte Arbeitslast zu finden. Es ist toll, die Flexibilität zu haben, die Lösungen auszuwählen, die am Besten sind.“ Myle Ott, Gründeringenieur, Character.AI
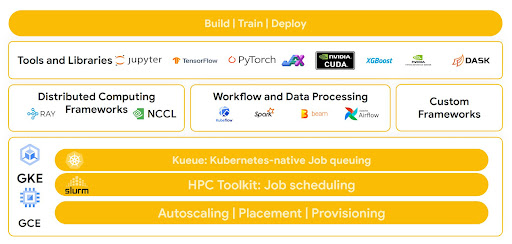
Mit der offenen Softwareumgebung von Google Cloud können Sie Anwendungen mit den Tools und Frameworks erstellen, mit denen Sie sich am besten auskennen. Gleichzeitig profitieren Sie von den Preis-Leistungs-Vorteilen der KI-Hypercomputerarchitektur.
„Durch die Zusammenarbeit mit Google Cloud und das Einbinden von generativer KI können wir einen maßgeschneiderten Reise-Concierge als Teils unseres Chatbots anbieten. Wir möchten, dass alle Personen, die unseren Service nutzen, nicht einfach nur eine Reise planen, sondern ihr ganz persönliches und einzigartiges Reiseerlebnis gestalten können.“ Martin Brodbeck, CTO, Priceline

Mit der offenen Softwareumgebung von Google Cloud können Sie Anwendungen mit den Tools und Frameworks erstellen, mit denen Sie sich am besten auskennen. Gleichzeitig profitieren Sie von den Preis-Leistungs-Vorteilen der KI-Hypercomputerarchitektur.
„Durch die Zusammenarbeit mit Google Cloud und das Einbinden von generativer KI können wir einen maßgeschneiderten Reise-Concierge als Teils unseres Chatbots anbieten. Wir möchten, dass alle Personen, die unseren Service nutzen, nicht einfach nur eine Reise planen, sondern ihr ganz persönliches und einzigartiges Reiseerlebnis gestalten können.“ Martin Brodbeck, CTO, Priceline
Cloud TPU v5e- und G2-VM-Instanzen mit NVIDIA L4-GPUs ermöglichen leistungsstarke und kostengünstige Inferenzen für eine breite Palette an KI-Arbeitslasten, einschließlich der neuesten LLMs und Gen AI-Modelle. Beide bieten erhebliche Preisleistungsverbesserungen im Vergleich zu früheren Modellen. Mit der KI-Hypercomputerarchitektur von Google Cloud können Kunden ihre Bereitstellungen auf branchenführende Levels skalieren.
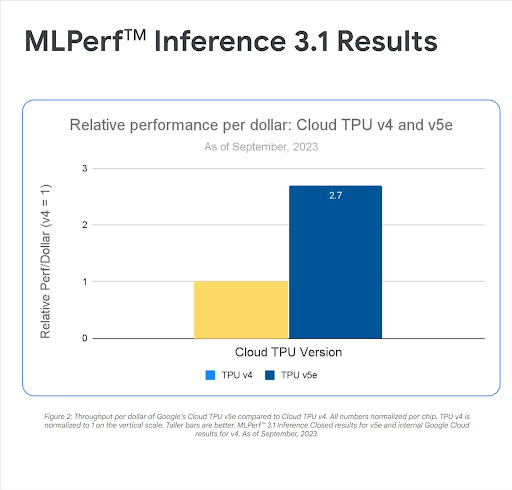
„Unsere Testergebnisse zeigen, dass Cloud TPU v5e der kostengünstigste Beschleuniger für umfangreiche Inferenzen für unser Modell ist. Geboten wird eine 2,7-mal höhere Leistung pro Dollar als bei G2- und eine 4,2-mal höhere Leistung pro Dollar als bei A2-Instanzen.“ Domenic Donato
Vice President Technology, AssemblyAI

Cloud TPU v5e- und G2-VM-Instanzen mit NVIDIA L4-GPUs ermöglichen leistungsstarke und kostengünstige Inferenzen für eine breite Palette an KI-Arbeitslasten, einschließlich der neuesten LLMs und Gen AI-Modelle. Beide bieten erhebliche Preisleistungsverbesserungen im Vergleich zu früheren Modellen. Mit der KI-Hypercomputerarchitektur von Google Cloud können Kunden ihre Bereitstellungen auf branchenführende Levels skalieren.
„Unsere Testergebnisse zeigen, dass Cloud TPU v5e der kostengünstigste Beschleuniger für umfangreiche Inferenzen für unser Modell ist. Geboten wird eine 2,7-mal höhere Leistung pro Dollar als bei G2- und eine 4,2-mal höhere Leistung pro Dollar als bei A2-Instanzen.“ Domenic Donato
Vice President Technology, AssemblyAI

































