

您可以使用以下各部分中介绍的信息和工具监控 Spark 批处理工作负载的 Dataproc Serverless 并对其进行问题排查
Persistent History Server
Dataproc Serverless for Spark 会创建运行工作负载所需的计算资源,在这些资源上运行工作负载,然后在工作负载结束时删除资源。工作负载完成后,工作负载指标和事件不会保留。但是,您可以使用永久性历史记录服务器 (PHS) 在 Cloud Storage 中保留工作负载应用历史记录(事件日志)。
如需将 PHS 用于批量工作负载,请执行以下操作:
Dataproc Serverless for Spark 日志
在 Dataproc Serverless for Spark 中默认启用日志记录,并且工作负载日志在工作负载完成后会保留。Dataproc Serverless for Spark 收集 Cloud Logging 中的工作负载日志。您可以在日志浏览器中访问 Cloud Dataproc Batch 资源下的工作负载 spark、agent、output 和 container 日志。
Dataproc Serverless for Spark 批处理示例:

如需了解详情,请参阅 Dataproc 日志。
工作负载指标
默认情况下,Dataproc Serverless for Spark 支持收集可用的 Spark 指标,除非您使用 Spark 指标收集属性停用或替换一个或多个 Spark 指标的收集。
您可以通过 Google Cloud 控制台中的 Metrics Explorer 或批量详情页面查看工作负载指标。
批量指标
Dataproc batch 资源指标可让您深入了解批处理资源,例如批处理执行器的数量。批处理指标带有 dataproc.googleapis.com/batch 前缀。

Spark 指标
可用的 Spark 指标包括 Spark 驱动程序和执行器指标以及系统指标。可用的 Spark 指标带有 custom.googleapis.com/ 前缀。
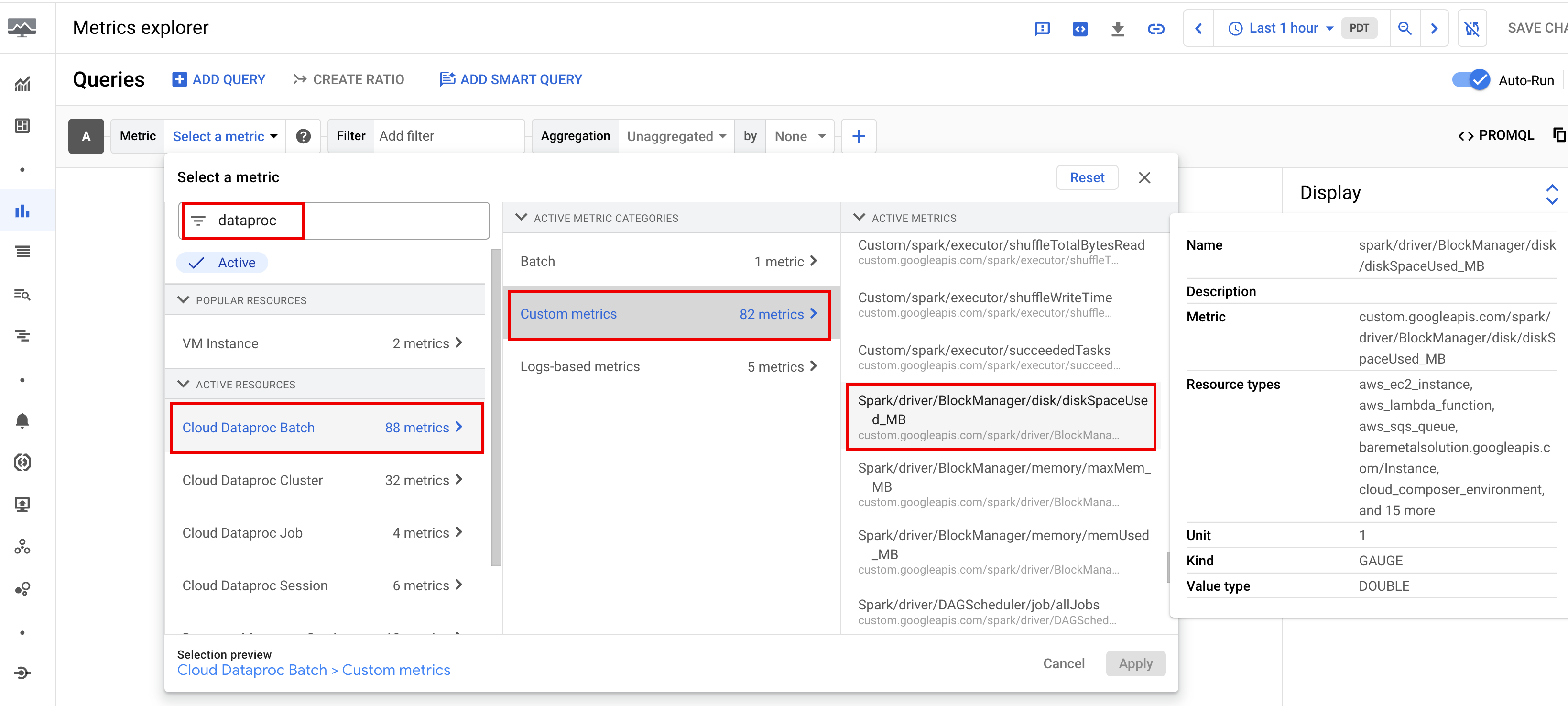
设置指标提醒
您可以创建 Dataproc 指标提醒,以接收工作负载问题的通知。
创建图表
您可以使用 Google Cloud 控制台中的 Metrics Explorer 来创建图表,以直观呈现工作负载指标。例如,您可以创建一个显示 disk:bytes_used 的图表,然后按 batch_id 进行过滤。
Cloud Monitoring
Monitoring 使用工作负载元数据和指标来深入了解适用于 Spark 工作负载的 Dataproc Serverless 的运行状况和性能。工作负载指标包括 Spark 指标、批处理指标和操作指标。
您可以使用 Google Cloud 控制台中的 Cloud Monitoring 来探索指标、添加图表、创建信息中心和创建提醒。
创建信息中心
您可以创建信息中心,以便使用多个项目和不同 Google Cloud 产品的指标来监控工作负载。如需了解详情,请参阅创建和管理自定义信息中心。
高级问题排查(预览版)
本部分介绍了 Google Cloud 控制台中提供的高级问题排查预览版功能,其中包括 Dataproc Serverless 的双子座辅助问题排查。该功能是 BigQuery 中的 Gemini 产品的一部分。
使用预览版功能
如需注册高级问题排查功能的预览版,请填写并提交 BigQuery 预览版中的 Genmini 表单。表单获得批准后,表单中列出的项目即可使用预览功能。
预览价格
试用预览版不会产生额外费用。以下预览版功能在正式发布 (GA) 后会产生费用:
GA 费用的提前通知将发送到您在预览版注册表单中提供的电子邮件地址。
功能要求
注册:你必须注册才能使用此功能。
权限:您必须拥有
dataproc.batches.analyze权限。如果您具有预定义的
roles/dataproc.admin、roles/dataproc.editor或roles/dataproc.viewer角色,则您已具备所需的权限。您无需执行任何其他操作。如果您使用自定义角色访问 Dataproc 服务,则该自定义角色必须具有
dataproc.batches.analyze权限。您可以使用 gcloud CLI 添加权限,如以下命令所示,该命令会在项目级别添加权限:
gcloud iam roles update CUSTOM_ROLE_ID --project=PROJECT_ID \ --add-permissions="dataproc.batches.analyze"
为 Dataproc Serverless 启用 Gemini 辅助的问题排查:使用 Google Cloud 控制台、gcloud CLI 或 Dataproc API 提交每个周期性 Spark 批量工作负载时,您可以为 Dataproc Serverless 启用 Gemini 辅助的问题排查。为周期性批量工作负载启用此功能后,Dataproc 将存储工作负载日志副本 30 天,并使用已保存的日志数据提供 Gemini 辅助的工作负载问题排查。如需了解 Spark 工作负载日志内容,请参阅适用于 Spark 日志的 Dataproc 无服务器。
控制台
执行以下步骤,为每个周期性 Spark 批量工作负载启用 Gemini 辅助的问题排查功能:
在 Google Cloud 控制台中,转到 Dataproc 批处理页面。
如需创建批量工作负载,请点击创建。
在容器部分,填写同类群组名称,该名称将批量标识为一系列周期性工作负载中的一个。Gemini 辅助分析适用于以此同类群组名称提交的第二个及后续工作负载。例如,指定
TPCH-Query1作为运行每日 TPC-H 查询的计划工作负载的同类群组名称。根据需要填写创建批次页面的其他部分,然后点击提交。如需了解详情,请参阅提交批量工作负载。
gcloud
在终端窗口或 Cloud Shell 中本地运行以下 gcloud CLI gcloud dataproc batches submit 命令,为每个周期性 Spark 批量工作负载启用 Gemini 辅助的问题排查功能:
gcloud dataproc batches submit COMMAND \
--region=REGION \
--cohort=COHORT \
other arguments ...
请替换以下内容:
- COMMAND:Spark 工作负载类型,例如
Spark、PySpark、Spark-Sql或Spark-R。 - REGION:将运行工作负载的区域。
- COHORT:同类群组名称,用于将批量标识为一系列周期性工作负载中的一个。Gemini 辅助分析适用于以此同类群组名称提交的第二个及后续工作负载。例如,将
TPCH Query 1指定为运行每日 TPC-H 查询的计划工作负载的同类群组名称。
API
在 batches.create 请求中添加 RuntimeConfig.cohort 名称,以对每个周期性 Spark 批量工作负载启用 Gemini 辅助问题排查。Gemini 辅助分析适用于使用此同类群组名称提交的第二个及后续工作负载。例如,将 TPCH-Query1 指定为运行每日 TPC-H 查询的计划工作负载的同类群组名称。
示例:
...
runtimeConfig:
cohort: TPCH-Query1
...
Gemini 辅助的 Dataproc Serverless 问题排查
Google Cloud 控制台的批次详情和批次列表页面上提供了以下 Gemini 辅助问题排查预览功能。
调查标签页:批次详情页面上的“调查”标签页提供了一个“运行状况概览(预览版)”部分,其中包含以下双双辅助问题排查面板:
- 什么是自动调优的?如果您为一个或多个工作负载启用了自动调节,此面板将显示应用于正在运行、已完成和失败的工作负载的最新自动调节更改。
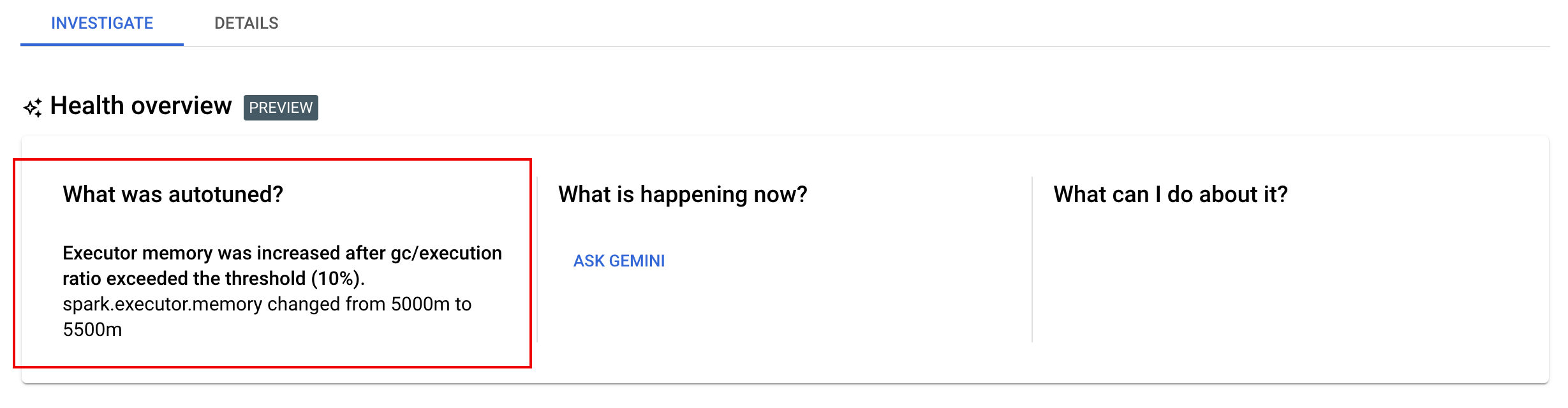
- 现在发生了什么?以及我该怎么办? 点击询问 Gemini,请求相关建议,以帮助修复失败的工作负载或改善成功但运行缓慢的工作负载。

如果您点击向 Gemini 询问,Gemini 将生成有关工作负载日志、Spark 指标和 Spark 事件的任何错误、异常或突出显示的摘要。Gemini 还会显示一系列建议步骤,您可以采取哪些措施来修复失败的工作负载或提高成功但运行缓慢的工作负载的性能。

Gemini 辅助问题排查列:在预览版中,Google Cloud 控制台中的 Dataproc 批次列表页面包含
What was Autotuned、What is happening now?和What can I do about it?列。
仅当已完成的批次处于
Failed、Cancelled或Succeeded状态时,系统才会显示并启用 Ask Gemini 按钮。如果您点击向 Gemini 询问,Gemini 将生成有关工作负载日志、Spark 指标和 Spark 事件的任何错误、异常或突出显示的摘要。Gemini 还会显示一系列建议步骤,您可以采取哪些措施来修复失败的工作负载或提高成功但运行缓慢的工作负载的性能。
批处理指标亮点
在预览版中,Google Cloud 控制台中的批量详情页面包含显示重要的批量工作负载指标值的图表。批量处理完成后,指标图表会填充值。

下表列出了 Google Cloud 控制台的批处理详情页面上显示的 Spark 工作负载指标,并描述了指标值如何使您可以深入了解工作负载状态和性能。
| 指标 | 它会显示什么? |
|---|---|
| 执行器级别的指标 | |
| JVM GC 时间与运行时的比率 | 该指标显示每个执行器的 JVM GC(垃圾回收)时间与运行时之间的比率。高比率可能表明在特定执行器上运行的任务中或低效数据结构内存在内存泄漏,这可能会导致较高的对象流失。 |
| 溢出的磁盘字节数 | 此指标显示溢出到不同执行程序的磁盘字节总数。如果执行器显示溢出的磁盘字节数较大,则可能表示数据倾斜。如果该指标随时间的推移而上升,则可能表示某些阶段存在内存压力或内存泄漏。 |
| 读取和写入的字节数 | 此指标显示每个执行器的写入字节数与读取字节数。如果读取或写入的字节数存在较大差异,则可能表示复制联接会导致特定执行器上出现数据膨胀。 |
| 读取和写入的记录 | 此指标显示每个执行器读取和写入的记录。如果读取的记录数量较少,但写入的记录数量较少,则可能表示特定执行器的处理逻辑存在瓶颈,导致在等待期间读取记录。如果执行器在读取和写入操作中持续滞后,可能表示这些节点上存在资源争用情况或执行器特有的代码效率低下。 |
| Shuffle 写入时间与运行时间之比 | 该指标显示执行器在 Shuffle 运行时中花费的时间与总运行时的对比情况。如果某些执行器的此值较高,则可能表示数据偏差或数据序列化效率低下。 您可以在 Spark 界面中找出 Shuffle 写入时间较长的阶段。查找这些阶段中完成时间超过平均时间的离群任务。检查 shuffle 写入时间较长的执行程序是否也显示高磁盘 I/O 活动。更高效的序列化和额外的分区步骤可能会有所帮助。与记录读取相比,记录写入次数过大可能表示由于联接效率低下或转换不正确导致的数据意外重复。 |
| 应用级别的指标 | |
| 阶段进程 | 此指标会显示处于失败、等待和正在运行的阶段的阶段数量。大量失败或等待的阶段可能表示数据倾斜。检查数据分区,并使用 Spark 界面中的阶段标签页调试阶段失败的原因。 |
| 批处理 Spark 执行器 | 此指标显示可能需要的执行器数量与运行的执行器数量。如果必需的执行程序和正在运行的执行程序之间有较大差异,则可能表示存在自动扩缩问题。 |
| 虚拟机级别的指标 | |
| 使用的内存 | 此指标显示已使用的虚拟机内存百分比。如果主进程百分比较高,则可能表示驱动程序面临内存压力。对于其他虚拟机节点,高百分比可能表示执行程序正在耗尽内存,这可能会导致大量磁盘溢出和工作负载运行时变慢。使用 Spark 界面分析执行程序,以检查是否存在高 GC 时间和高任务失败情况。还要调试用于大型数据集缓存和不必要的变量广播的 Spark 代码。 |
作业日志
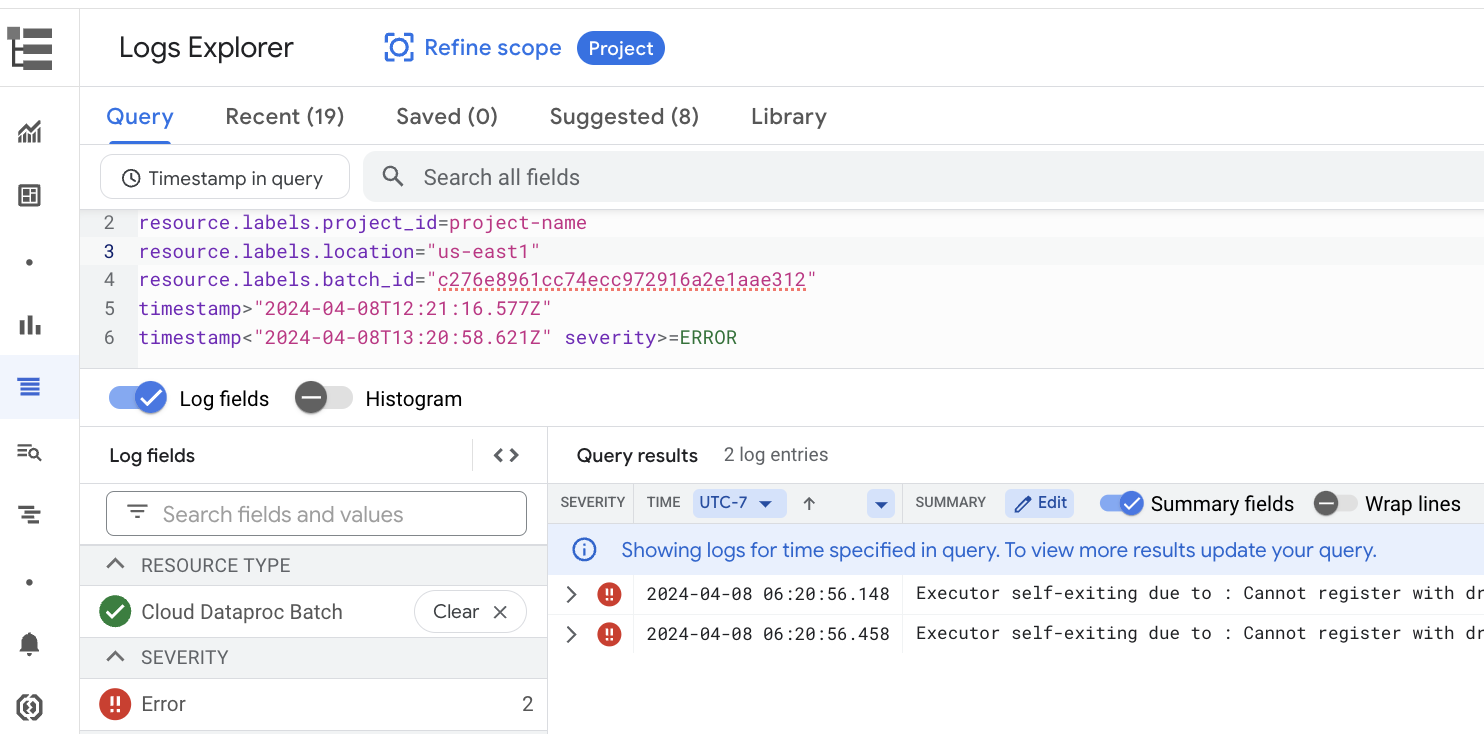
在预览版中,Google Cloud 控制台中的批处理详情页面会列出作业(批量工作负载)日志。这些日志包括从工作负载输出和 Spark 日志中滤除的警告和错误。您可以选择日志严重程度,添加过滤条件,然后点击在 Logs Explorer 中查看图标,在日志浏览器中打开所选的批量日志。

示例:在 Google Cloud 控制台的批处理详情页面上从严重性选择器中选择 Errors 后,系统会打开日志浏览器。
Spark 界面(预览版)
如果您在 Spark 界面预览版功能中注册了项目,则可以在 Google Cloud 控制台中查看 Spark 界面,而无需创建 Dataproc PHS(永久性历史记录服务器)集群。Spark 界面从批处理工作负载中收集 Spark 执行详细信息。如需了解详情,请参阅作为 Spark 界面预览版的一部分分发给已注册客户的用户指南。