

Mit den in den folgenden Abschnitten beschriebenen Informationen und Tools können Sie Dataproc Serverless für Spark-Batcharbeitslasten überwachen und Fehler beheben.
Persistent History Server
Dataproc Serverless for Spark erstellt die Rechenressourcen, die zum Ausführen einer Arbeitslast erforderlich sind, führt die Arbeitslast auf diesen Ressourcen aus und löscht die Ressourcen dann, wenn die Arbeitslast beendet ist. Arbeitslastmesswerte und -ereignisse bleiben nach Abschluss einer Arbeitslast nicht erhalten. Sie können jedoch einen Persistent History Server (PHS) verwenden, um den Verlauf von Arbeitslastanwendungen (Ereignislogs) in Cloud Storage aufzubewahren.
So verwenden Sie PHS mit einer Batcharbeitslast:
Geben Sie Ihre PHS an, wenn Sie eine Arbeitslast senden.
Verwenden Sie Component Gateway, um eine Verbindung zum PHS herzustellen, um Anwendungsdetails, Planerphasen, Details auf Aufgabenebene sowie Umgebungs- und Executor-Informationen anzusehen.
Dataproc Serverless für Spark-Logs
Logging ist in Dataproc Serverless für Spark standardmäßig aktiviert und Arbeitslastlogs bleiben nach Abschluss einer Arbeitslast erhalten. Dataproc Serverless for Spark erfasst Arbeitslastlogs in Cloud Logging.
Sie können auf die Logs spark, agent, output und container der Arbeitslast im Log-Explorer unter der Ressource Cloud Dataproc Batch zugreifen.
Batch-Beispiel für Dataproc Serverless for Spark:

Weitere Informationen finden Sie unter Dataproc-Logs.
Arbeitslastmesswerte
Standardmäßig aktiviert Dataproc Serverless for Spark die Erfassung verfügbarer Spark-Messwerte, es sei denn, Sie verwenden Attribute für die Sammlung von Spark-Messwerten, um die Erfassung eines oder mehrerer Spark-Messwerte zu deaktivieren oder zu überschreiben.
Sie können Arbeitslastmesswerte über den Metrics Explorer oder die Seite Batchdetails in der Google Cloud Console ansehen.
Batchmesswerte
Dataproc-Ressourcenmesswerte batch bieten Einblicke in Batchressourcen, z. B. die Anzahl der Batch-Executors. Batchmesswerte haben das Präfix dataproc.googleapis.com/batch.

Spark-Messwerte
Zu den verfügbaren Spark-Messwerten gehören Spark-Treiber- und Executor-Messwerte sowie Systemmesswerte. Verfügbare Spark-Messwerte haben das Präfix custom.googleapis.com/.
Messwertbenachrichtigungen einrichten
Sie können Dataproc-Messwertbenachrichtigungen erstellen, um über Probleme mit der Arbeitslast informiert zu werden.
Diagramme erstellen
Mit dem Metrics Explorer in der Google Cloud Console können Sie Diagramme erstellen, in denen Arbeitslastmesswerte visualisiert werden. Sie können beispielsweise ein Diagramm erstellen, um disk:bytes_used anzuzeigen, und dann nach batch_id filtern.
Cloud Monitoring
Monitoring stellt anhand von Arbeitslastmetadaten und -messwerten Informationen zum Zustand und zur Leistung von Dataproc Serverless for Spark-Arbeitslasten bereit. Arbeitslastmesswerte umfassen Spark-Messwerte, Batchmesswerte und Vorgangsmesswerte.
Mit Cloud Monitoring in der Google Cloud Console können Sie Messwerte untersuchen, Diagramme hinzufügen, Dashboards und Benachrichtigungen erstellen.
Dashboards erstellen
Sie können ein Dashboard erstellen, um Arbeitslasten mithilfe von Messwerten aus mehreren Projekten und verschiedenen Google Cloud-Produkten zu überwachen. Weitere Informationen finden Sie unter Benutzerdefinierte Dashboards erstellen und verwalten.
Erweiterte Fehlerbehebung (Vorschau)
In diesem Abschnitt werden die in der Google Cloud Console verfügbaren Vorabfunktionen zur erweiterten Fehlerbehebung behandelt. Dazu gehört auch die von Gemini unterstützte Fehlerbehebung für Dataproc Serverless, die Teil des Gemini in BigQuery-Angebots ist.
Zugriff auf Vorschaufunktionen
Füllen Sie das Formular Gemini in der BigQuery-Vorschau aus und reichen Sie es ein, um sich für die Vorabversion der erweiterten Funktionen zur Fehlerbehebung anzumelden. Sobald das Formular genehmigt wurde, haben die im Formular aufgeführten Projekte Zugriff auf Vorschaufunktionen.
Preisvorschau
Für die Teilnahme an der Vorschau fallen keine zusätzlichen Kosten an. Für die folgenden Vorschaufunktionen werden Gebühren berechnet, sobald sie allgemein verfügbar sind:
Eine Vorabankündigung über GA-Gebühren wird an die E-Mail-Adresse gesendet, die Sie im Anmeldeformular für die Vorschau angegeben haben.
Anforderungen an Funktionen
Registrieren: Sie müssen sich für die Funktion registrieren.
Berechtigung: Sie benötigen die Berechtigung
dataproc.batches.analyze.Wenn Sie die vordefinierte Rolle
roles/dataproc.admin,roles/dataproc.editoroderroles/dataproc.viewerhaben, haben Sie die erforderliche Berechtigung. Sie müssen nichts weiter unternehmen.Wenn Sie eine benutzerdefinierte Rolle für den Zugriff auf Dataproc-Dienste verwenden, muss die benutzerdefinierte Rolle die Berechtigung
dataproc.batches.analyzehaben. Sie können die Berechtigung über die gcloud CLI hinzufügen, wie im folgenden Befehl gezeigt, mit dem die Berechtigung auf Projektebene hinzugefügt wird:
gcloud iam roles update CUSTOM_ROLE_ID --project=PROJECT_ID \ --add-permissions="dataproc.batches.analyze"
Von Gemini unterstützte Fehlerbehebung für Dataproc Serverless aktivieren: Sie aktivieren die von Gemini unterstützte Fehlerbehebung für Dataproc Serverless, wenn Sie jede wiederkehrende Spark-Batcharbeitslast über die Google Cloud Console, die gcloud CLI oder die Dataproc API senden. Nachdem diese Funktion für eine wiederkehrende Batcharbeitslast aktiviert wurde, speichert Dataproc 30 Tage lang eine Kopie der Arbeitslastlogs und verwendet die gespeicherten Logdaten, um eine von Gemini unterstützte Fehlerbehebung für die Arbeitslast bereitzustellen. Informationen zum Inhalt der Spark-Arbeitslastlogs finden Sie unter Dataproc Serverless für Spark-Logs.
Console
Führen Sie die folgenden Schritte aus, um die von Gemini unterstützte Fehlerbehebung für jede wiederkehrende Spark-Batcharbeitslast zu aktivieren:
Rufen Sie in der Google Cloud Console die Dataproc-Seite Batches auf.
Klicken Sie auf Erstellen, um eine Batcharbeitslast zu erstellen.
Geben Sie im Abschnitt Container den Namen Kohorte ein, der den Batch als eine Reihe wiederkehrender Arbeitslasten kennzeichnet. Die von Gemini unterstützte Analyse wird auf die zweite und nachfolgende Arbeitslasten angewendet, die mit diesem Kohortennamen eingereicht werden. Geben Sie beispielsweise
TPCH-Query1als Kohortennamen für eine geplante Arbeitslast an, die eine tägliche TPC-H-Abfrage ausführt.Füllen Sie nach Bedarf die anderen Abschnitte auf der Seite Batch erstellen aus und klicken Sie dann auf Senden. Weitere Informationen finden Sie unter Batcharbeitslast senden.
gcloud
Führen Sie den folgenden gcloud dataproc batches submit-Befehl der gcloud CLI lokal in einem Terminalfenster oder in Cloud Shell aus, um die von Gemini unterstützte Fehlerbehebung für jede wiederkehrende Spark-Batcharbeitslast zu aktivieren:
gcloud dataproc batches submit COMMAND \
--region=REGION \
--cohort=COHORT \
other arguments ...
Ersetzen Sie Folgendes:
- COMMAND: der Spark-Arbeitslasttyp, z. B.
Spark,PySpark,Spark-SqloderSpark-R - REGION: Die Region, in der Ihre Arbeitslast ausgeführt wird.
- COHORT: der Kohortenname, der den Batch als einen Teil einer Reihe wiederkehrender Arbeitslasten kennzeichnet.
Die von Gemini unterstützte Analyse wird auf die zweite und nachfolgende Arbeitslasten angewendet, die mit diesem Kohortennamen eingereicht werden. Geben Sie beispielsweise
TPCH Query 1als Kohortennamen für eine geplante Arbeitslast an, die eine tägliche TPC-H-Abfrage ausführt.
API
Fügen Sie den Namen RuntimeConfig.cohort in die Anfrage batches.create ein, um die von Gemini unterstützte Fehlerbehebung für jede wiederkehrende Spark-Batcharbeitslast zu aktivieren. Die von Gemini unterstützte Analyse wird auf die zweite und nachfolgende Arbeitslasten angewendet, die mit diesem Kohortennamen eingereicht werden. Geben Sie beispielsweise TPCH-Query1 als Kohortennamen für eine geplante Arbeitslast an, die eine tägliche TPC-H-Abfrage ausführt.
Beispiel:
...
runtimeConfig:
cohort: TPCH-Query1
...
Gemini-gestützte Fehlerbehebung für Dataproc Serverless
Die folgenden von Gemini unterstützten Funktionen zur Fehlerbehebung stehen in der Google Cloud Console auf den Seiten Batchdetails und Batches zur Verfügung.
Tab Investigate: Der Tab „Investigate“ auf der Seite Batchdetails enthält einen Bereich mit den folgenden von Gemini unterstützten Bereichen zur Fehlerbehebung:
- Was wurde automatisch abgestimmt? Wenn Sie für eine oder mehrere Arbeitslasten die automatische Feinabstimmung aktiviert haben, werden in diesem Bereich die letzten Änderungen angezeigt, die beim automatischen Abstimmungsergebnis auf laufende, abgeschlossene und fehlgeschlagene Arbeitslasten angewendet wurden.
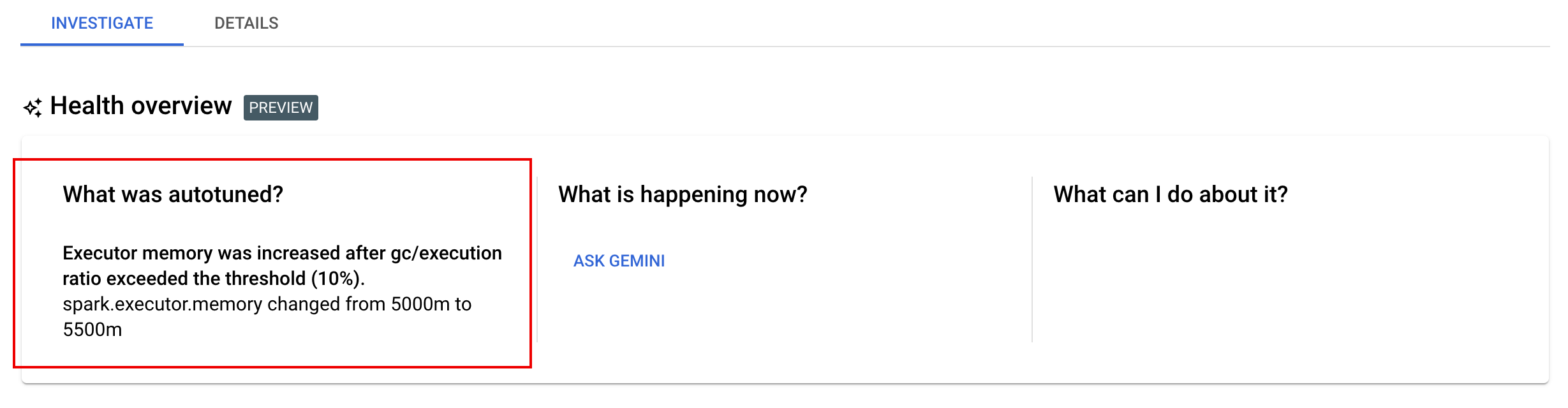
- Was passiert jetzt? und Was kann ich dagegen tun? Klicken Sie auf Gemini fragen, um Empfehlungen anzufordern, wie Sie fehlgeschlagene Arbeitslasten beheben oder erfolgreiche, aber langsame Arbeitslasten verbessern können.

Wenn Sie auf Ask Gemini klicken, generiert Gemini eine Zusammenfassung aller Fehler, Anomalien oder Highlights aus Arbeitslastlogs, Spark-Messwerten und Spark-Ereignissen. Gemini kann auch eine Liste mit empfohlenen Schritten anzeigen, die Sie ergreifen können, um eine fehlgeschlagene Arbeitslast zu beheben oder die Leistung einer erfolgreichen, aber langsamen Arbeitslast zu verbessern.

Spalten zur Fehlerbehebung von Gemini:Im Rahmen der Vorabversion enthält die Dataproc-Listenseite Batches in der Google Cloud Console die Spalten
What was Autotuned,What is happening now?undWhat can I do about it?.
Die Schaltfläche Ask Gemini wird nur angezeigt und aktiviert,wenn ein abgeschlossener Batch den Status
Failed,CancelledoderSucceededhat. Wenn Sie auf Ask Gemini klicken, generiert Gemini eine Zusammenfassung aller Fehler, Anomalien oder Highlights aus Arbeitslastlogs, Spark-Messwerten und Spark-Ereignissen. Gemini kann auch eine Liste mit empfohlenen Schritten anzeigen, die Sie ergreifen können, um eine fehlgeschlagene Arbeitslast zu beheben oder die Leistung einer erfolgreichen, aber langsamen Arbeitslast zu verbessern.
Highlights von Batchmesswerten
Die Seite Batchdetails in der Google Cloud Console enthält im Rahmen der Vorabversion Diagramme, in denen wichtige Messwerte zu Batcharbeitslasten angezeigt werden. Die Messwertdiagramme werden nach Abschluss des Batches mit Werten gefüllt.
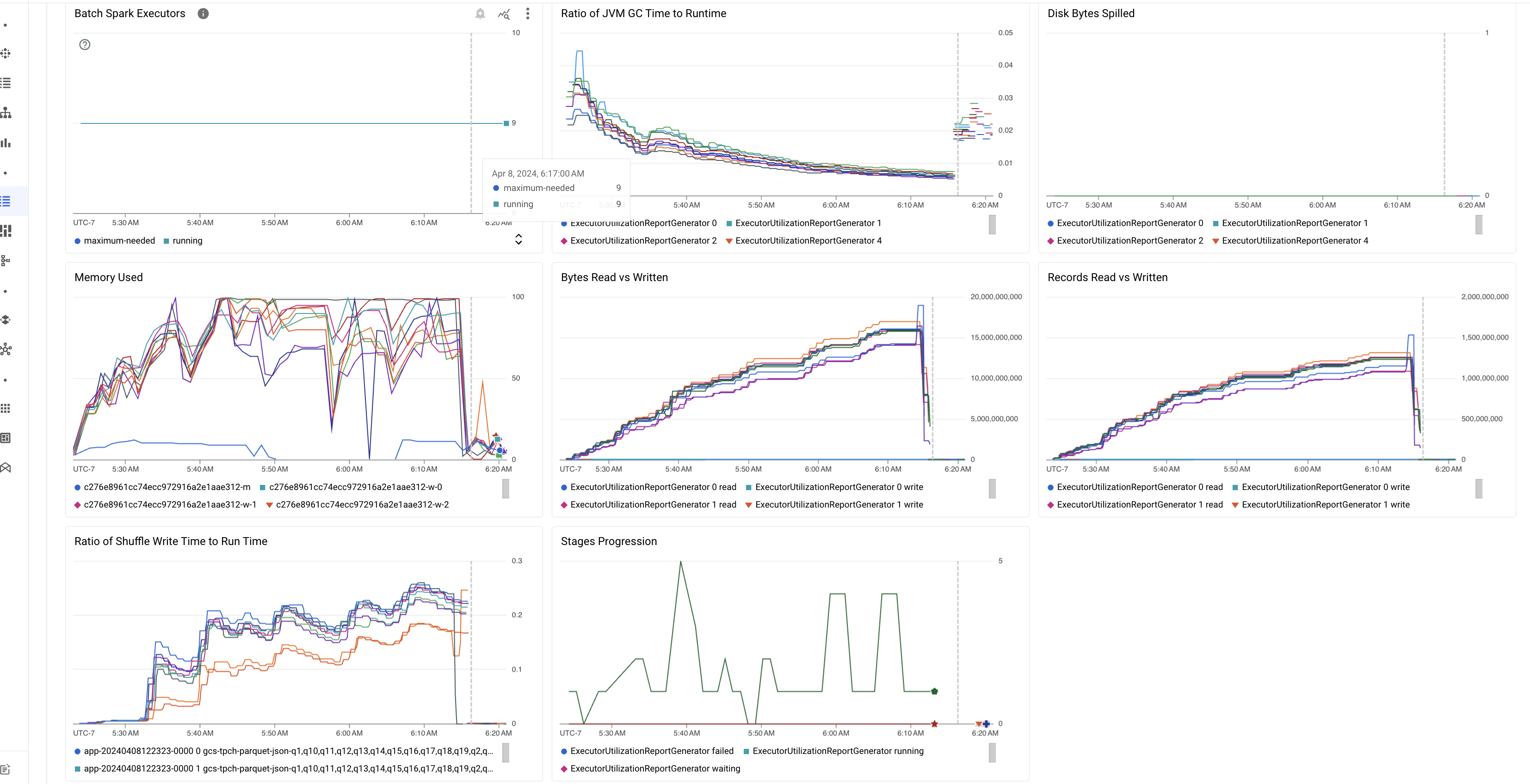
In der folgenden Tabelle sind die Spark-Arbeitslastmesswerte aufgeführt, die in der Google Cloud Console auf der Seite Batchdetails angezeigt werden. Außerdem wird beschrieben, wie Messwerte einen Einblick in den Arbeitslaststatus und die Leistung geben können.
| Messwert | Was wird angezeigt? |
|---|---|
| Messwerte auf Executor-Ebene | |
| Verhältnis der JVM-GC-Zeit zur Laufzeit | Dieser Messwert zeigt das Verhältnis der JVM-GC-Zeit (GC-Zeit zur Speicherbereinigung) zur Laufzeit pro Executor. Hohe Verhältnisse können auf Speicherlecks in Aufgaben, die auf bestimmten Executors oder ineffizienten Datenstrukturen ausgeführt werden, hinweisen, was zu einer hohen Objektabwanderung führen kann. |
| Übergegebene Laufwerkbyte | Dieser Messwert zeigt die Gesamtzahl der Laufwerkbyte, die über verschiedene Executors weitergegeben wurden. Wenn ein Executor eine hohe Anzahl übergebener Laufwerkbyte anzeigt, kann dies auf eine Datenverzerrung hinweisen. Wenn der Messwert im Laufe der Zeit zunimmt, kann dies darauf hindeuten, dass es Phasen mit Speicherauslastung oder Speicherlecks gibt. |
| Gelesene und geschriebene Byte | Dieser Messwert zeigt die geschriebenen Byte im Vergleich zu den gelesenen Byte pro Executor. Große Abweichungen bei den gelesenen oder geschriebenen Byte können auf Szenarien hinweisen, in denen replizierte Joins zu einer Datenerweiterung bei bestimmten Executors führen. |
| Gelesene und geschriebene Datensätze | Dieser Messwert zeigt die pro Executor gelesenen und geschriebenen Datensätze. Das Lesen großer Zahlen von Datensätzen mit einer geringen Anzahl von geschriebenen Datensätzen kann auf einen Engpass in der Verarbeitungslogik bei bestimmten Executors hinweisen, was dazu führt, dass während des Wartens Datensätze gelesen werden. Executors, die immer wieder Verzögerungen bei Lese- und Schreibvorgängen verursachen, können auf Ressourcenkonflikte auf diesen Knoten oder auf Ineffizienzen im Executor-spezifischen Code hinweisen. |
| Verhältnis von Shuffle-Schreibzeit und Laufzeit | Der Messwert zeigt die Zeit, die der Executor im Vergleich zur Gesamtlaufzeit in der Shuffle-Laufzeit verbracht hat. Wenn dieser Wert für einige Executors hoch ist, kann dies auf eine Datenverzerrung oder eine ineffiziente Datenserialisierung hindeuten. Sie können Phasen mit langen Shuffle-Schreibzeiten in der Spark-UI identifizieren. Suchen Sie nach Ausreißern in diesen Phasen, die länger dauern als die durchschnittliche Zeit. Prüfen Sie, ob die Executors mit hohen Shuffle-Schreibzeiten auch eine hohe E/A-Aktivität des Laufwerks aufweisen. Eine effizientere Serialisierung und zusätzliche Partitionierungsschritte könnten hilfreich sein. Sehr große Eintragsschreibvorgänge im Vergleich zu Lesevorgängen können auf eine unbeabsichtigte Datenduplizierung aufgrund ineffizienter Joins oder falscher Transformationen hinweisen. |
| Messwerte auf Anwendungsebene | |
| Fortschritt der Phasen | Dieser Messwert zeigt die Anzahl der Phasen in den Phasen „Fehlgeschlagen“, „Warten“ und „Laufen“ an. Eine große Anzahl fehlgeschlagener oder Wartephasen kann auf eine Datenverzerrung hinweisen. Suchen Sie nach Datenpartitionen und beheben Sie den Grund für den Phasenfehler über den Tab Phasen in der Spark-UI. |
| Spark-Batch-Executors | Dieser Messwert zeigt die Anzahl der möglicherweise erforderlichen Executors im Vergleich zur Anzahl der ausgeführten Executors. Ein großer Unterschied zwischen erforderlichen und ausgeführten Executors kann auf Probleme beim Autoscaling hinweisen. |
| Messwerte auf VM-Ebene | |
| Verwendeter Arbeitsspeicher | Dieser Messwert zeigt den Prozentsatz des verwendeten VM-Arbeitsspeichers. Wenn der Master-Prozentsatz hoch ist, kann das darauf hindeuten, dass der Treiber unter der Arbeitsspeicherauslastung steht. Bei anderen VM-Knoten kann ein hoher Prozentsatz darauf hindeuten, dass den Executors nicht genügend Arbeitsspeicher zur Verfügung steht, was zu einer hohen Speicherauslastung und einer langsameren Arbeitslastlaufzeit führen kann. Verwenden Sie die Spark-UI, um Executors zu analysieren und auf eine lange GC-Zeit und hohe Taskfehler zu prüfen. Debuggen Sie auch Spark-Code für große Dataset-Caching und unnötige Übertragung von Variablen. |
Joblogs
Im Rahmen der Vorabversion werden auf der Seite Batchdetails in der Google Cloud Console Joblogs (Batcharbeitslast) aufgeführt. Die Logs enthalten Warnungen und Fehler, die aus der Arbeitslastausgabe und Spark-Logs herausgefiltert wurden. Sie können den Log-Schweregrad auswählen, einen Filter hinzufügen und dann auf das Symbol Im Log-Explorer ansehen klicken,um die ausgewählten Batchlogs im Log-Explorer zu öffnen.

Beispiel: Der Log-Explorer wird geöffnet, nachdem Sie in der Google Cloud Console auf der Seite Batchdetails unter „Schweregrad“ die Option Errors ausgewählt haben.

Spark-UI (Vorabversion)
Wenn Sie Ihr Projekt für die Vorabversion von Spark UI registriert haben, können Sie die Spark UI in der Google Cloud Console aufrufen, ohne einen Dataproc PHS-Cluster (Persistent History Server) erstellen zu müssen. Die Spark-UI erfasst Spark-Ausführungsdetails aus Batcharbeitslasten. Weitere Informationen finden Sie im Nutzerhandbuch, das angemeldeten Kunden im Rahmen des Vorschaurelease der Spark-UI bereitgestellt wird.