
Neste documento, descrevemos como os discos permanentes podem ser acessados a partir de instâncias de máquina virtual (VM) e o processo de replicação de disco permanente. Ele também descreve a infraestrutura central dos discos permanentes. Este documento é destinado aos engenheiros e arquitetos do Google Cloud que querem usar discos permanentes nos sistemas deles.
Os discos permanentes não são discos locais anexados a máquinas físicas, mas serviços de rede conectados a VMs como dispositivos de bloco de rede. Quando você lê ou grava em um disco permanente, os dados são transmitidos pela rede. Os discos permanentes são um dispositivo de armazenamento de rede, mas eles permitem muitos casos de uso e funcionalidades em termos de capacidade, flexibilidade e confiabilidade que os discos convencionais não podem fornecer.
Discos permanentes e Colossus
Os discos permanentes foram desenvolvidos para execução acoplada ao sistema de arquivos do Google, o Colossus, que é um sistema de armazenamento em blocos distribuído. Os drivers de disco permanente criptografam automaticamente os dados na VM antes que eles sejam transmitidos da VM para a rede. Depois, o Colossus mantém os dados. Quando o Colossus lê os dados, o driver descriptografa os dados de entrada.
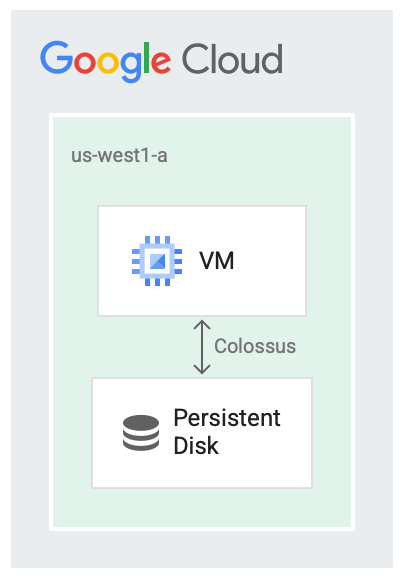
Os discos permanentes usam o Colossus como back-end de armazenamento.
É útil ter discos como serviço em vários casos, por exemplo:
- Redimensionar os discos enquanto a VM está em execução é mais fácil do que interrompê-la primeiro. É possível aumentar o tamanho do disco sem interromper a VM.
- Anexar e desanexar discos fica mais fácil quando discos e VMs não precisam compartilhar o mesmo ciclo de vida ou serem colocados no mesmo local. É possível interromper uma VM e usar o disco de inicialização permanente para inicializar outra.
- Recursos de alta disponibilidade como a replicação são mais fáceis porque o driver de disco pode simplesmente ocultar detalhes dela e fornecê-la de maneira automática no momento da gravação.
Latência do disco
Há várias ferramentas de comparativo de mercado que podem ser usadas para monitorar a latência de overhead do uso de discos, como um serviço de rede. O exemplo a seguir usa a interface de disco SCSI, não a interface NVMe, e mostra a saída da VM fazendo algumas leituras de blocos de 4 KiB a partir de um disco permanente. O exemplo a seguir mostra a latência que você vê nas leituras:
$ ioping -c 5 /dev/sda1
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=293.7 us (warmup)
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=330.0 us
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=278.1 us
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=307.7 us
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=310.1 us
--- /dev/sda1 (block device 10.00 GiB) ioping statistics ---
4 requests completed in 1.23 ms, 16 KiB read, 3.26 k iops, 12.7 MiB/s
generated 5 requests in 4.00 s, 20 KiB, 1 iops, 5.00 KiB/s
min/avg/max/mdev = 278.1 us / 306.5 us / 330.0 us / 18.6 us
O Compute Engine também permite anexar SSDs locais a máquinas virtuais, caso você precise do processo de máxima velocidade. Ao executar um servidor de cache ou grandes jobs de processamento de dados em que haja uma saída intermediária, recomendamos que você escolha SSDs locais. Diferente do que acontece nos discos permanentes, os dados nos SSDs locais não são permanentes e, portanto, a VM sempre os apaga quando a máquina virtual é reiniciada. Os SSDs locais só são adequados para casos de otimização.
A saída a seguir é um exemplo da latência observada com leituras de 4 KiB de um SSD local usando a interface de disco do NVMe:
$ ioping -c 5 /dev/nvme0n1
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=245.3 us(warmup)
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=252.3 us
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=244.8 us
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=289.5 us
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=219.9 us
--- /dev/nvme0n1 (block device 375 GiB) ioping statistics ---
4 requests completed in 1.01 ms, 16 KiB read, 3.97 k iops, 15.5 MiB/s
generated 5 requests in 4.00 s, 20 KiB, 1 iops, 5.00 KiB/s
min/avg/max/mdev = 219.9 us / 251.6 us / 289.5 us / 25.0 us
Replicação
Ao criar um novo Persistent Disk, é possível criar o disco em uma só zona ou replicá-lo em duas zonas na mesma região.
Por exemplo, se você criasse um disco em uma zona, como em us-west1-a, você teria uma cópia do disco. Eles são chamados de discos zonais.
É possível aumentar a disponibilidade do disco armazenando outra cópia dele em uma zona diferente dentro da região, como em us-west1-b.
Os discos replicados em duas zonas na mesma região são chamados de Persistent Disks regionais.
É improvável que uma região falhe completamente, mas podem ocorrer falhas zonais. A replicação na região em zonas diferentes, conforme mostrado na imagem a seguir, ajuda na disponibilidade e reduz a latência do disco. Se as duas zonas de replicação falharem, isso representará uma falha em toda a região.

O disco é replicado em duas zonas.
No cenário replicado, os dados estão disponíveis na zona local (us-west1-a), que é a zona em que a máquina virtual está sendo executada. Depois, os dados são replicados para outra instância do Colossus, em outra zona (us-west1-b). Pelo menos uma das zonas precisa ser a mesma em que a VM está sendo executada.
Observe que a replicação de disco permanente serve apenas para a alta disponibilidade dos discos. Falhas zonais podem afetar as máquinas virtuais ou outros componentes, o que também pode causar falhas temporárias.
Ler/gravar sequências
Para determinar as sequências de leitura/gravação ou a ordem em que os dados são lidos e gravados no disco, a maior parte do trabalho é feita pelo driver de disco da VM. Como usuário, você não precisa lidar com a semântica de replicação e pode interagir com o sistema de arquivos normalmente. O driver subjacente processa a sequência de leitura e gravação.
Por padrão, o sistema opera no modo de replicação completa, em que as solicitações de leitura ou gravação do disco são enviadas para as duas réplicas.
No modo de replicação completa, ocorre o seguinte:
- Durante a gravação, uma solicitação de gravação tenta fazer a gravação nas duas réplicas e confirma quando isso é feito com êxito.
- Durante a leitura, a VM envia uma solicitação de leitura às duas réplicas e apresenta os resultados daquela que foi bem sucedida. Se a solicitação de leitura expirar, outra solicitação de leitura será enviada.
Se uma réplica falhar e não confirmar a conclusão das solicitações de leitura ou gravação, as leituras e gravações não serão mais enviadas para ela. A réplica precisa passar por um processo de reconciliação para retornar ao estado atual antes da continuidade da replicação.
A seguir
- Saiba como configurar discos para atender aos requisitos de desempenho.
- Veja as práticas recomendadas para snapshots de disco permanente.